Python in Excel für die DatenanalyseFehlende Werte mit Python in Excel erkennen und bereinigen
Warum fehlende Werte ein großes Problem sind
In nahezu jedem Datensatz treten fehlende Werte auf. Typische Ursachen sind:
- unvollständige Eingaben
- Systemfehler
- fehlende Datenquellen
- Importprobleme
Diese fehlenden Werte können Analysen stark verfälschen. Zum Beispiel:
- Durchschnittswerte sind falsch.
- Gruppierungen liefern falsche Ergebnisse.
- Filter funktionieren nicht wie erwartet.
Deshalb gilt: Bevor Sie Daten analysieren, sollten Sie immer die Datenqualität prüfen.
Der erste Schritt: Daten in Python laden
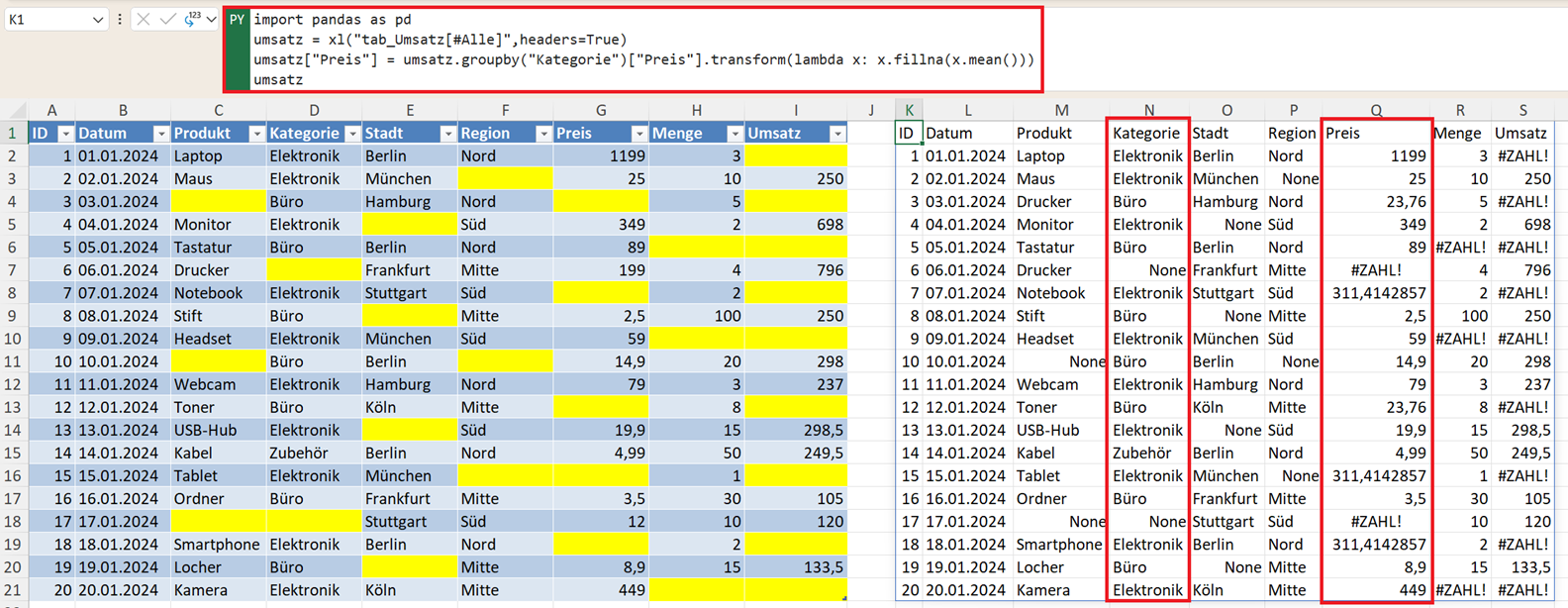
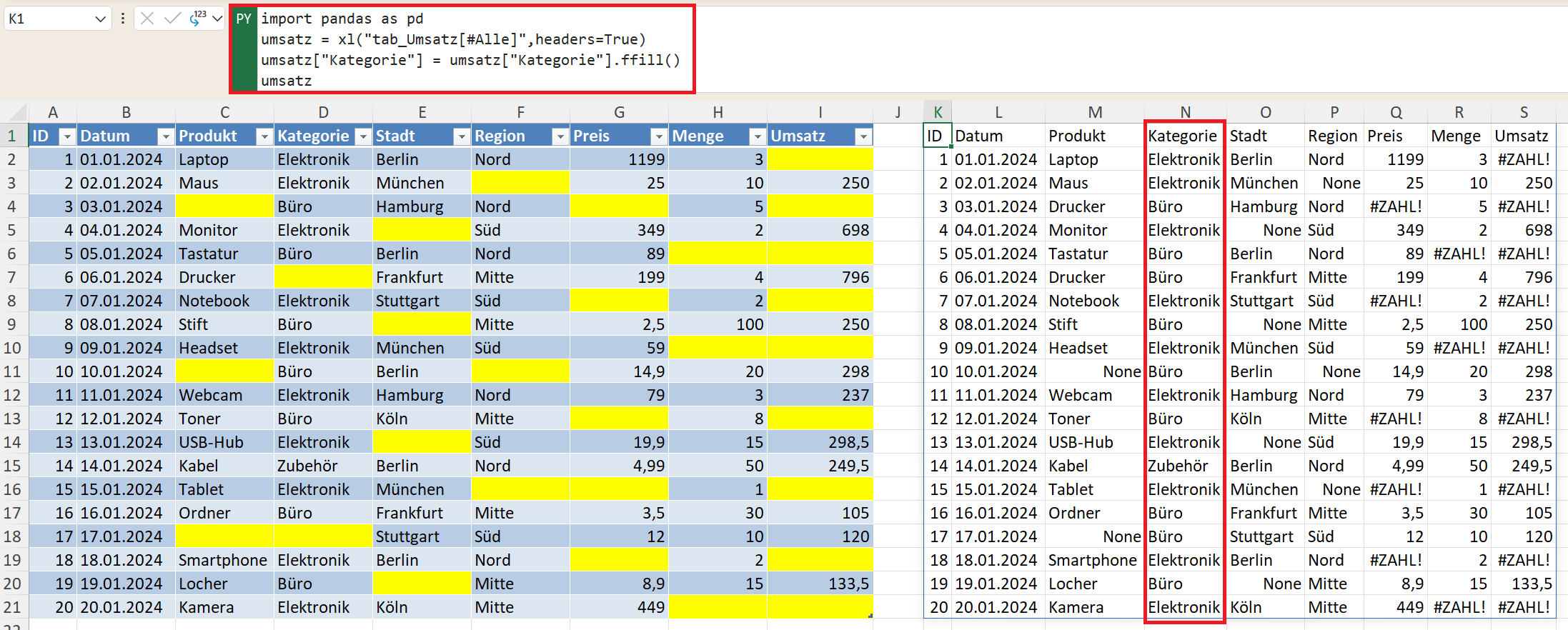
In der folgenden Abbildung sehen Sie im linken Bereich eine intelligente Tabelle, die Lücken (fehlende Werte) enthält. Die Lücken sind durch einen gelben Zellhintergrund gekennzeichnet. Der Name der intelligenten Tabelle lautet tab_Umsatz.
Bevor Sie fehlende Werte bereinigen können, müssen Sie die Excel-Daten an Python übergeben. Dazu nutzen Sie die integrierte xl()-Funktion.
Klicken Sie in die Formelleiste, tippen Sie =PY, markieren Sie Ihren Datenbereich und schließen Sie mit Strg + Enter ab.
Wichtig: Pandas wird in Python in Excel automatisch als pd bereitgestellt. Dennoch empfiehlt es sich, den Import zu Beginn explizit anzugeben – besonders für Einsteiger:
import pandas as pd
umsatz = xl("tab_Umsatz[#Alle]", headers=True)
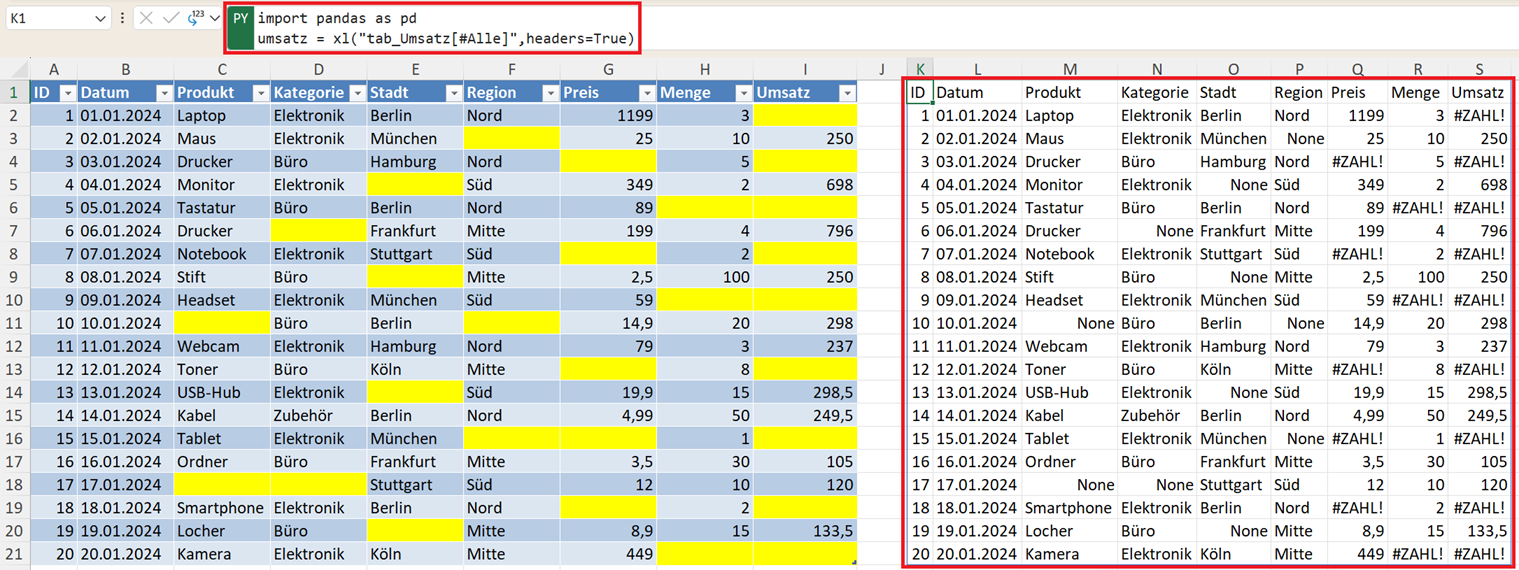
Statt eines festen Bereichs wie A1:D100 sollten Sie möglichst eine Excel-Tabelle verwenden. Dann wächst der Bereich automatisch mit. So müssen Sie den Bereich nicht jedes Mal manuell anpassen.
Erfassen Sie auch headers=True, damit die erste Zeile als Kopfzeile erkannt wird.
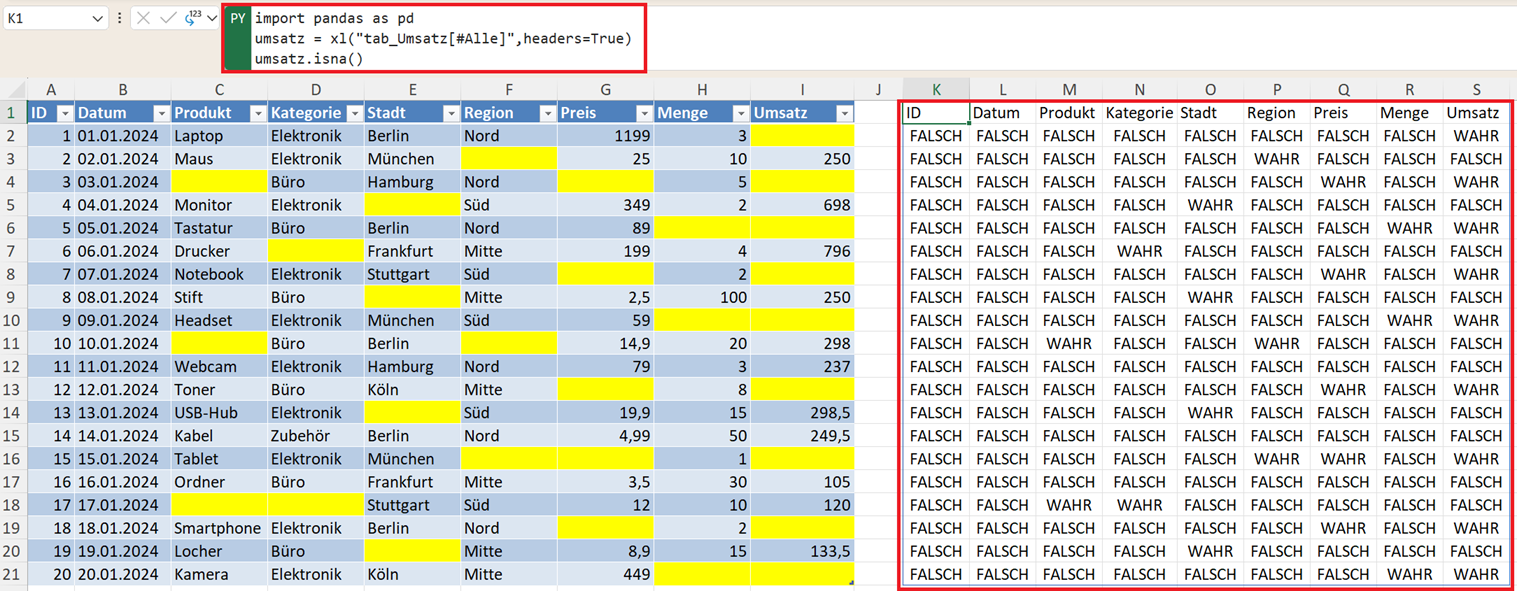
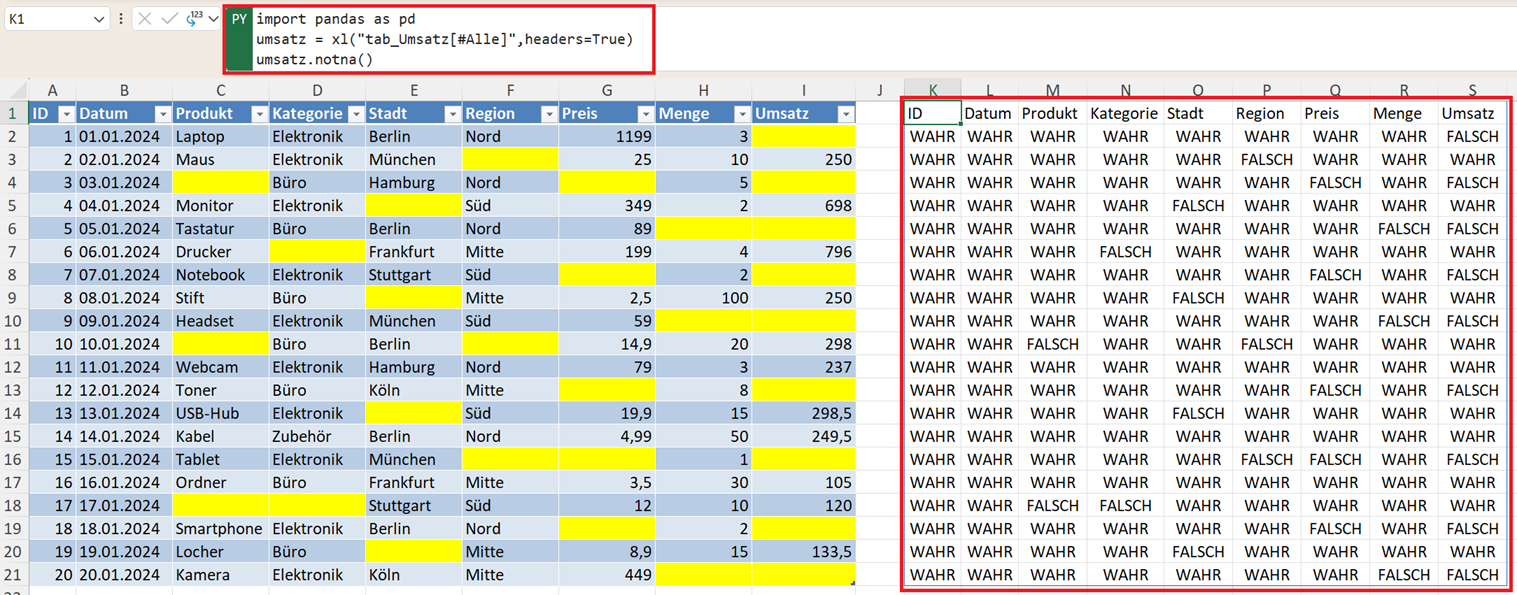
Fehlende Werte erkennen mit isna()
Pandas bietet eine einfache Funktion, um fehlende Werte zu identifizieren.
umsatz.isna()
Das Ergebnis zeigt:
- True → Wert fehlt
- False → Wert vorhanden
Das praktische Gegenstück ist: notna().
Vorsicht: In Excel-Zellen stehen oft keine echten Leerstellen, sondern Platzhalter wie n.v., -, N/A oder leere Strings (""). Pandas erkennt diese nicht automatisch als fehlende Werte.
Sie sollten diese vorab bereinigen und typische Platzhalter durch echte NaN ersetzen:
umsatz = umsatz.replace(["n.v.", "-", "N/A", ""], pd.NA)
Für unsichtbare Leerzeichen nutzen Sie den regulären Ausdruck:
umsatz = umsatz.replace(r'^\s*$', pd.NA, regex=True)
Erst dann arbeitet isna() zuverlässig.
Anzahl fehlender Werte berechnen und unvollständige Datensätze anzeigen
Im Folgenden erläutern wir weitere Python-Funktionen, um fehlenden Werten im Datensatz auf die Spur zu kommen und diese zu identifizieren.
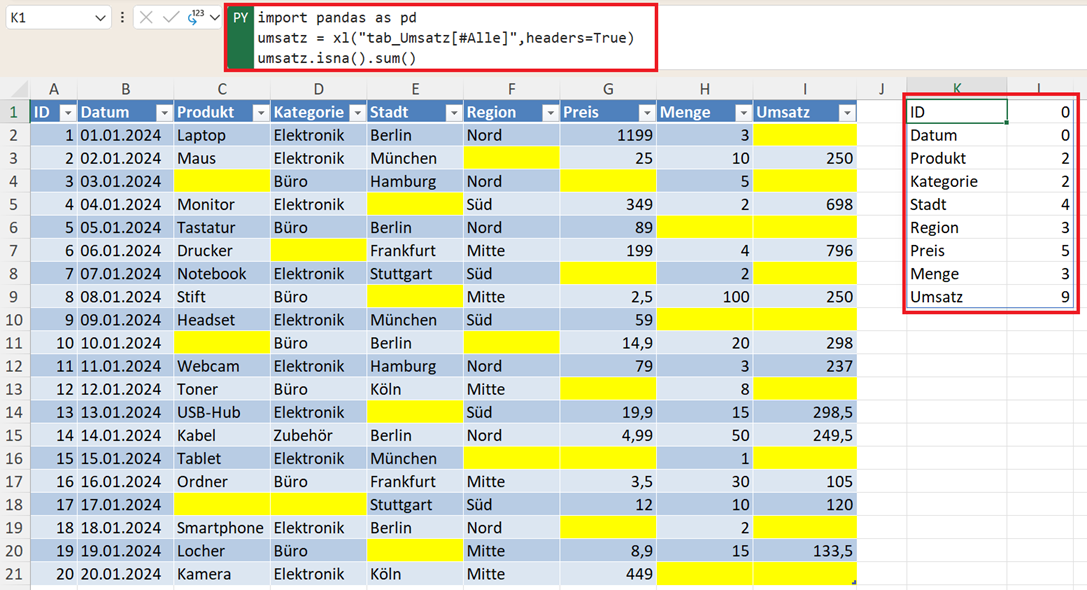
Fehlende Werte pro Spalte zählen
umsatz.isna().sum()
Damit erkennen Sie sofort problematische Bereiche.
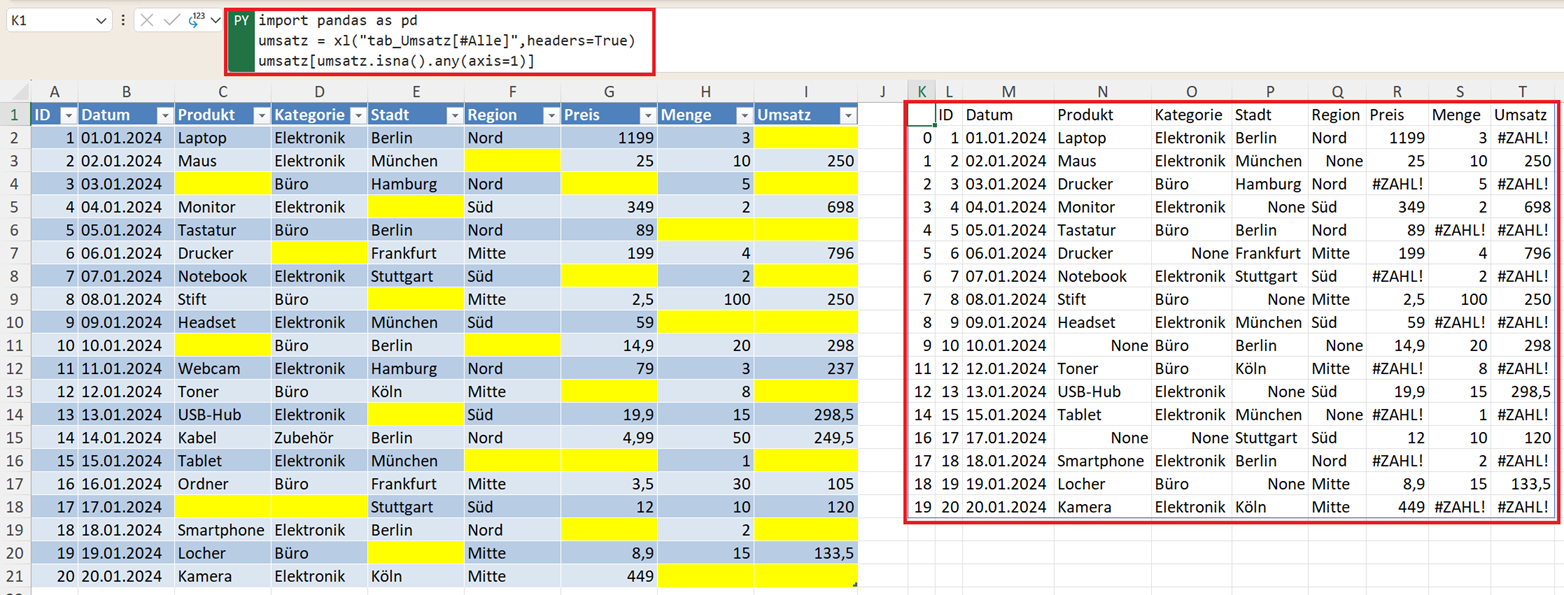
Nur Zeilen mit fehlenden Werten anzeigen
umsatz[umsatz.isna().any(axis=1)]
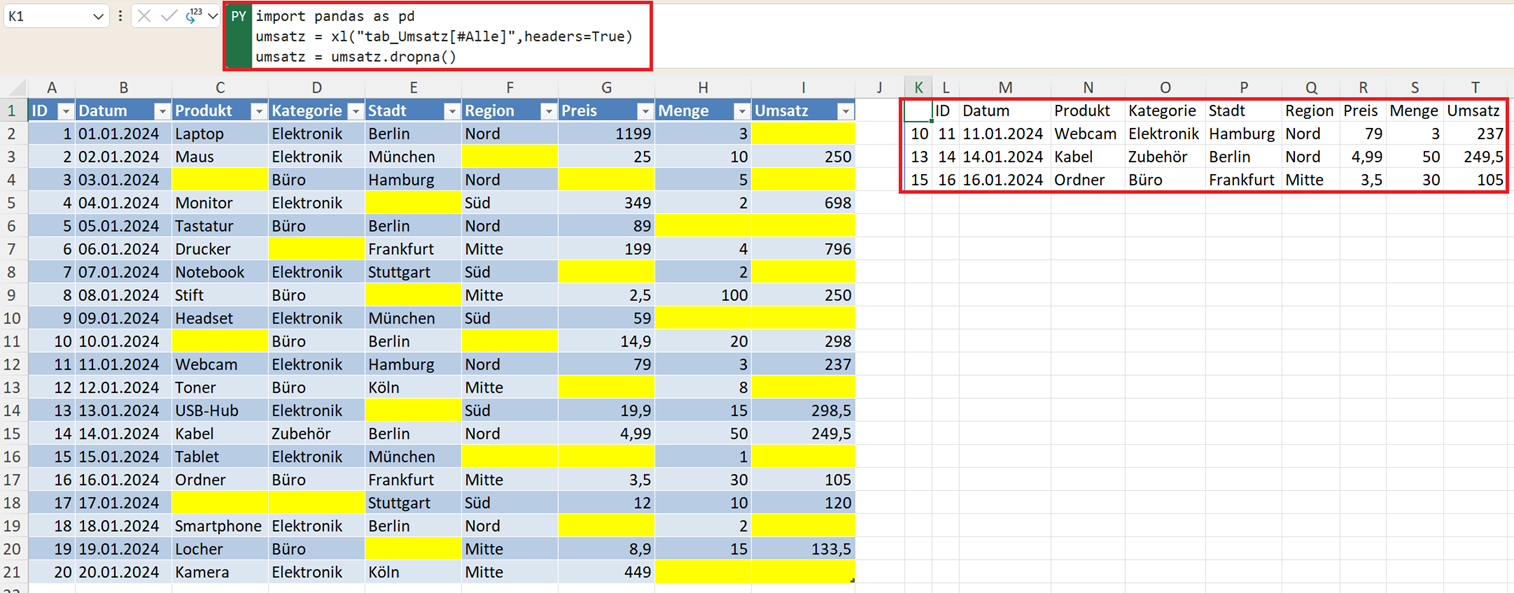
Fehlende Werte entfernen mit dropna()
Mit dem folgenden Python-Befehl werden alle Zeilen mit fehlenden Werten entfernt.
umsatz = umsatz.dropna()
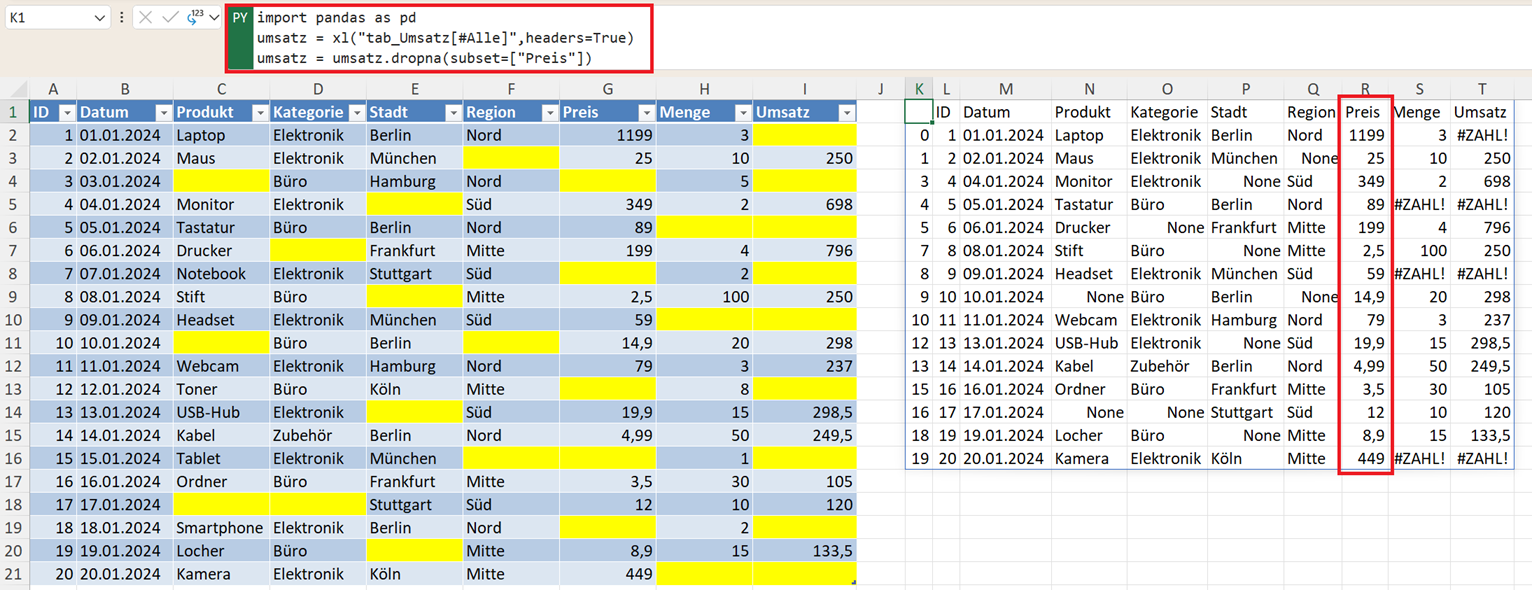
Nur bestimmte Spalten beim Löschen berücksichtigen. Es sollen die Zeilen gelöscht werden, die in der Spalte Preis keinen Wert haben:
umsatz = umsatz.dropna(subset=["Preis"])
Nur Zeilen löschen, die in ALLEN Spalten leer sind:
umsatz = umsatz.dropna(how="all")
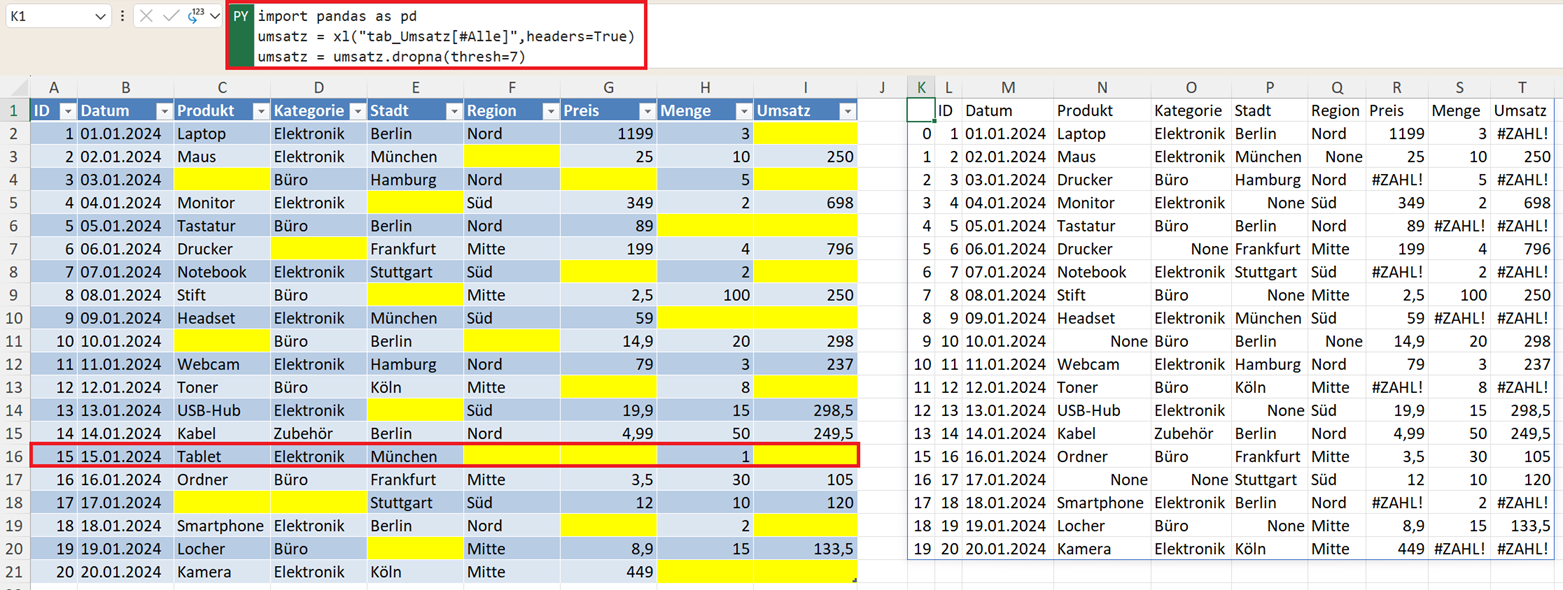
Mindestens X gültige Werte pro Zeile sollen vorhanden sein:
umsatz = umsatz.dropna(thresh=7)
Fehlende Werte ersetzen mit fillna() und ffill()
Oft möchte man Werte nicht löschen, sondern sinnvoll ergänzen. Beispiel:
- Preis durch Durchschnitt ersetzen
- Oder bei Ausreißern den Median als Ersatz nutzen
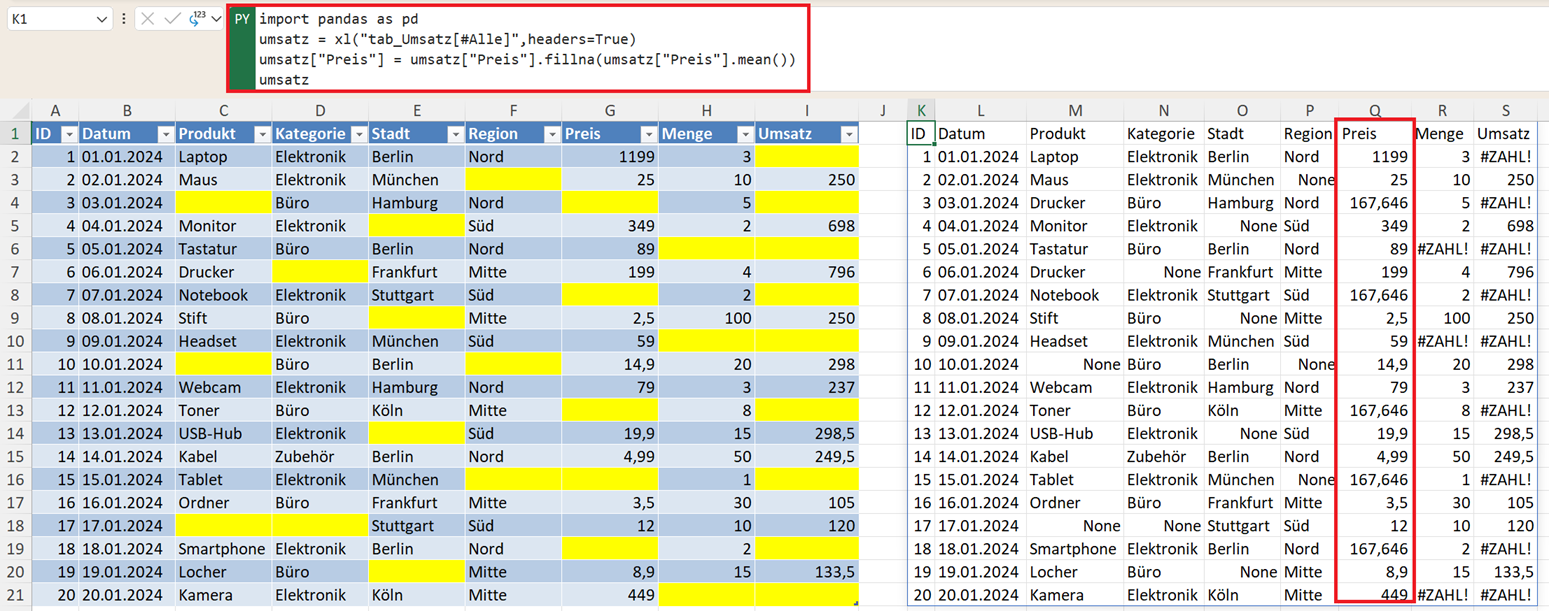
Fehlende Werte mit dem Durchschnitt ersetzen:
umsatz["Preis"] = umsatz["Preis"].fillna(umsatz["Preis"].mean())
Hinweis: .mean() ignoriert NaN (leere Zellen) automatisch – Sie müssen die NaN-Werte nicht vorher entfernen.
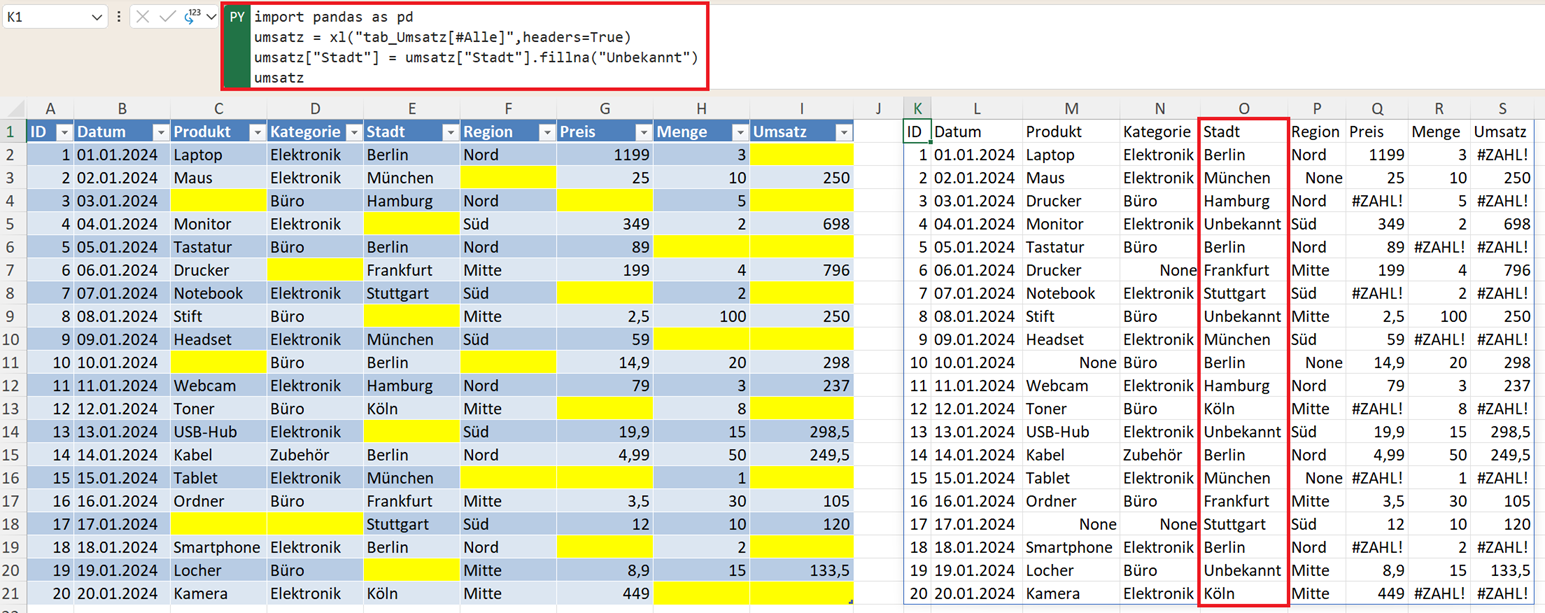
Fehlende Textwerte lassen sich durch einen geeigneten Hinweistext ersetzen mit:
umsatz["Stadt"] = umsatz["Stadt"].fillna("Unbekannt")
In Excel-Listen sind Zellen oft leer, weil der Wert darüber logisch weitergilt (zum Beispiel eine Kategorie). Hier hilft Forward Fill ffill():
umsatz["Kategorie"] = umsatz["Kategorie"].ffill()
Das Gegenstück ist, Werte von unten nach oben aufzufüllen: Backward Fill.
umsatz["Kategorie"] = umsatz["Kategorie"].bfill()
Ein Spezialfall ist das gruppenspezifische Auffüllen. Hier möchte man fehlende Werte nicht global, sondern innerhalb einer Gruppe ersetzen – zum Beispiel den Mittelwert pro Produktkategorie statt des Gesamtmittelwerts:
umsatz["Preis"] = umsatz.groupby("Kategorie")["Preis"].transform(
lambda x: x.fillna(x.mean())
)