Python in Excel für die DatenanalyseMehrere Kennzahlen gleichzeitig berechnen – Aggregationen mit Pandas
- Warum mehrere Kennzahlen gleichzeitig wichtig sind
- Datensatz laden und vorbereiten
- Mehrere Kennzahlen mit agg() berechnen
- Eigene Spaltennamen vergeben: Named Aggregation
- Mehrere Aggregationen pro Spalte
- Kombination mit Sortierung
- Kombination mit Filter
- Zwei Fallstricke (für große Datenmengen)
- Wichtiger Unterschied in der Praxis: count vs. size
- Vergleich mit Excel
Warum mehrere Kennzahlen gleichzeitig wichtig sind
In der Praxis reicht es selten aus, nur eine einzelne Kennzahl zu betrachten. In Excel verwenden Sie dafür mehrere Pivot-Felder oder Formeln. Mit Pandas können Sie mehrere Kennzahlen in einem einzigen Schritt berechnen.
Das zugrundeliegende Prinzip nennt man Split-Apply-Combine: Daten trennen, berechnen und wieder zusammenführen. Dazu erfahren Sie in diesem Beitrag, wie Sie
- mehrere Kennzahlen gleichzeitig berechnen,
- nachvollziehbare Spaltennamen vergeben,
- Ergebnisse direkt Excel-tauglich machen und
- die Performance bei großen Daten verbessern.
Hinweis zur Dateneingabe in Excel: Markieren Sie eine Zelle, tippen Sie =PY( ein, fügen Sie den Python-Code ein und schließen Sie mit ) (schließende Klammer) ab. Drücken Sie Strg + Enter, um die Zelle zu bestätigen. Das Ergebnis wird automatisch als dynamische Tabelle in Excel ausgegeben und aktualisiert sich bei Änderungen.
Datensatz laden und vorbereiten
Die Tabelle mit den folgenden Beispieldaten trägt den Namen Umsatzdaten_Filter. Sie enthält die folgenden Spalten:
- Produkt: Name des verkauften Produkts
- Preis: Einzelpreis
- Verkaufsmenge: Anzahl der verkauften Einheiten
- Land: Vertriebsland
- Vertriebskanal: zum Beispiel Online, Stationär
Wichtig ist, dass die Spalten für Berechnungen als Zahlen vorliegen – überprüfen Sie dies mit umsatz.dtypes. Zunächst wird der Umsatz berechnet:
umsatz = xl("Umsatzdaten_Filter[#Alle]", headers=True)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
umsatz
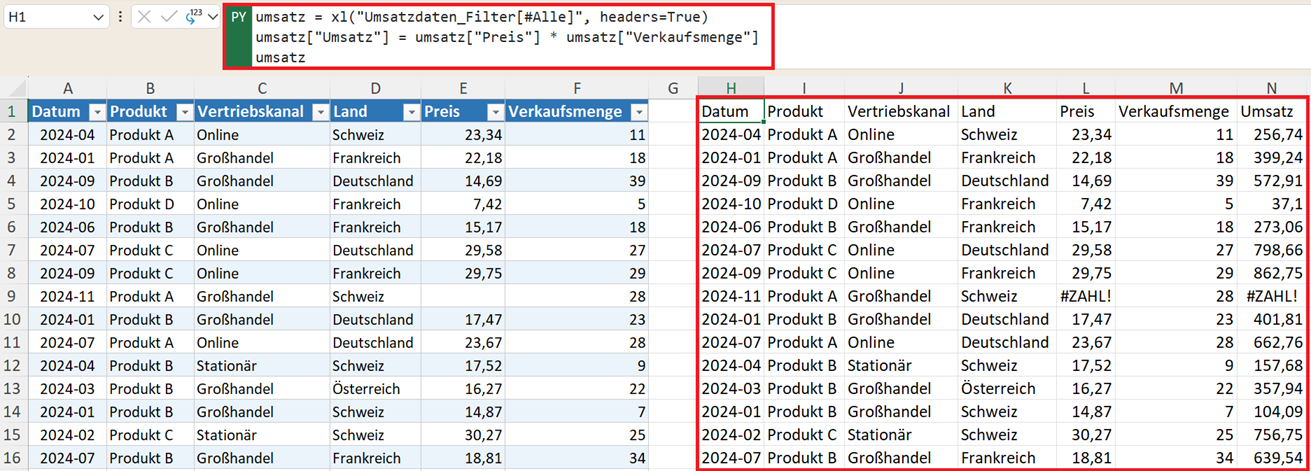
Hinweis: Die Funktion xl("Tabellenname[#Alle]") lädt eine komplette Excel-Tabelle. Ersetzen Sie "Umsatzdaten_Filter" durch den Namen Ihrer eigenen Tabelle. Fehlende Werte (NaN) werden von Aggregationen wie sum oder mean automatisch ignoriert – das ist meist erwünscht.
Falls nötig, können Sie fehlende Werte ersetzen mit:
umsatz["Preis"] = umsatz["Preis"].fillna(0)
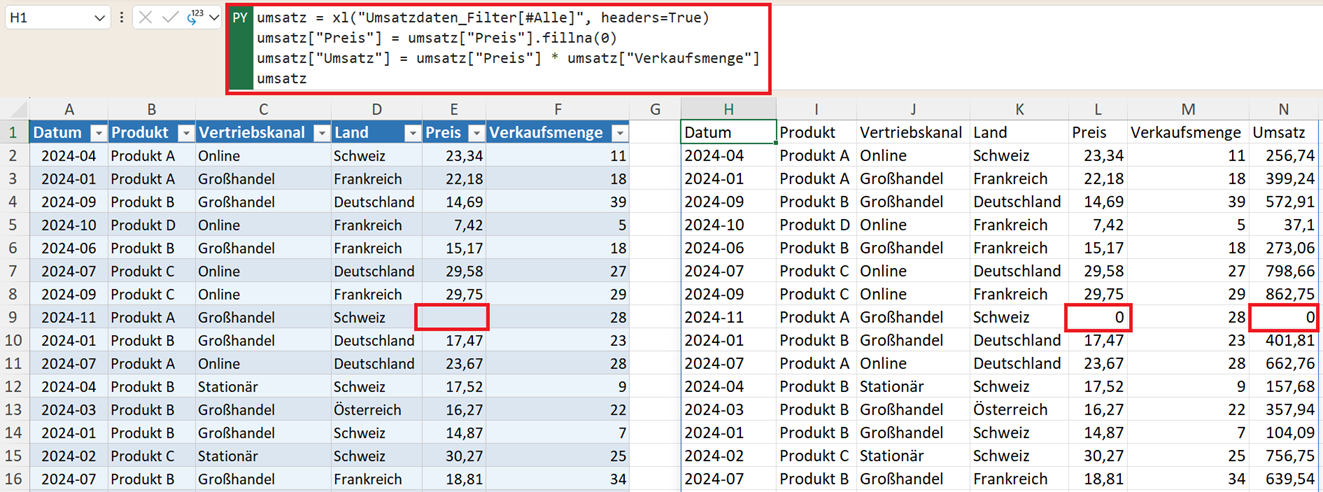
Falls eine Spalte fälschlicherweise als Text eingelesen wurde, konvertieren Sie sie mit:
umsatz["Preis"] = pd.to_numeric(umsatz["Preis"], errors="coerce")
Der Parameter errors="coerce" wandelt nicht konvertierbare Werte automatisch in NaN um, anstatt einen Fehler auszulösen. Alternativ können Sie den Datentyp direkt setzen:
umsatz["Preis"] = umsatz["Preis"].astype(float)
Mehrere Kennzahlen mit agg() berechnen
Die zentrale Funktion für diesen Beitrag ist die Aggregation agg(). Damit können Sie verschiedene Berechnungen auf verschiedene Spalten gleichzeitig anwenden.
Beispiel: Kennzahlen pro Produkt
umsatz.groupby("Produkt", as_index=False).agg({
"Umsatz": "sum",
"Preis": "mean",
"Verkaufsmenge": "sum"})
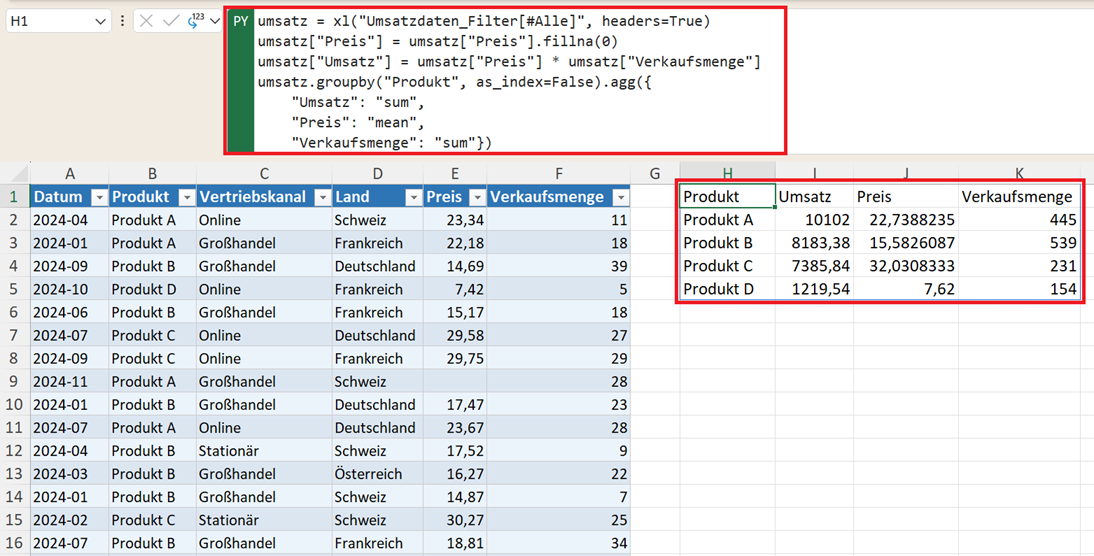
Das Ergebnis wird in Excel automatisch als Tabelle ausgegeben (Spill-Bereich).
Erklärung des Python-Codes:
- groupby("Produkt") → Gruppierung nach Produkt
- "Umsatz": "sum" → Gesamtumsatz pro Produkt
- "Preis": "mean" → durchschnittlicher Preis
- "Verkaufsmenge": "sum" → Gesamtmenge
Eigene Spaltennamen vergeben: Named Aggregation
Die Standardnamen sind oft technisch. Sie können die Ausgabe lesbarer machen, indem Sie die Spalten im Befehl mit einer gewünschten Bezeichnung definieren:
umsatz = xl("Umsatzdaten_Filter[#Alle]", headers=True)
umsatz["Preis"] = umsatz["Preis"].fillna(0)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
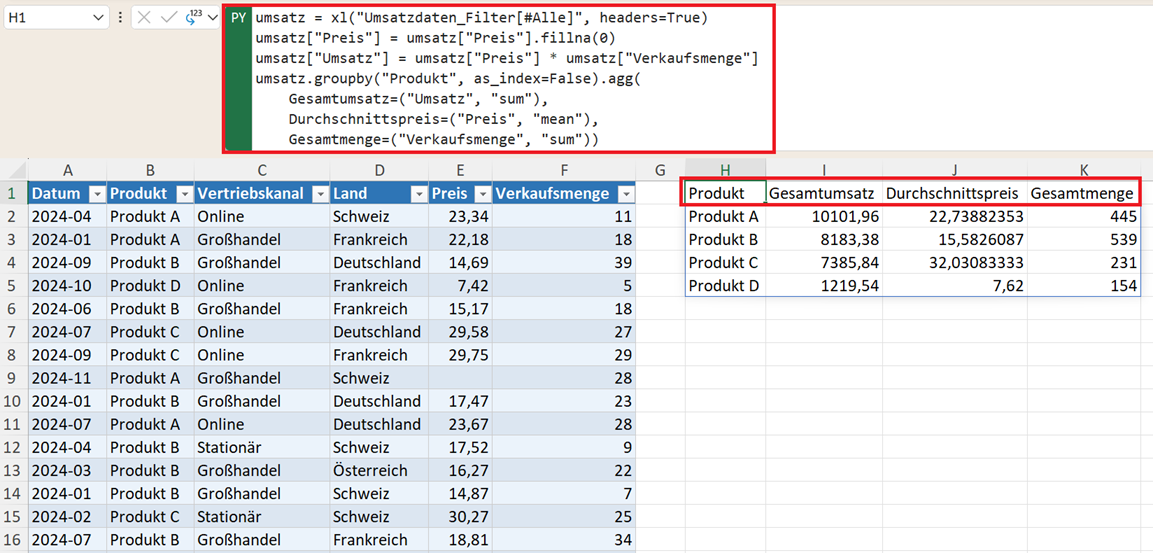
umsatz.groupby("Produkt", as_index=False).agg(
Gesamtumsatz=("Umsatz", "sum"),
Durchschnittspreis=("Preis", "mean"),
Gesamtmenge=("Verkaufsmenge", "sum"))
Vorteil: Die Ergebnistabelle ist verständlich beschriftet und vermeidet mehrstufige Spaltennamen.
Mehrere Aggregationen pro Spalte
Sie können auch mehrere Kennzahlen für ein und dieselbe Spalte berechnen.
umsatz = xl("Umsatzdaten_Filter[#Alle]", headers=True)
umsatz["Preis"] = umsatz["Preis"].fillna(0)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
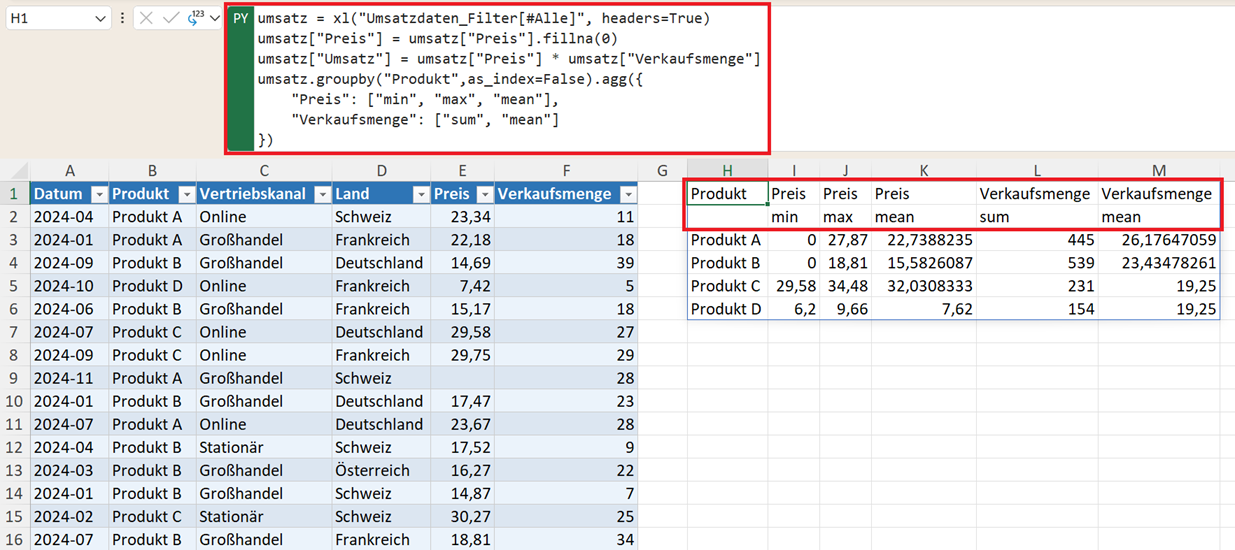
umsatz.groupby("Produkt",as_index=False).agg({
"Preis": ["min", "max", "mean"],
"Verkaufsmenge": ["sum", "mean"]
})
Das Ergebnis zeigt nun untergeordnete Spalten (z. B. Preis min, Preis max). Pandas erstellt dabei automatisch mehrstufige Spaltennamen (MultiIndex).
Kombination mit Sortierung
Die Ausgabe können Sie im nächsten Schritt sortieren. Zum Beispiel nach Gesamtumsatz:
umsatz = xl("Umsatzdaten_Filter[#Alle]", headers=True)
umsatz["Preis"] = umsatz["Preis"].fillna(0)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
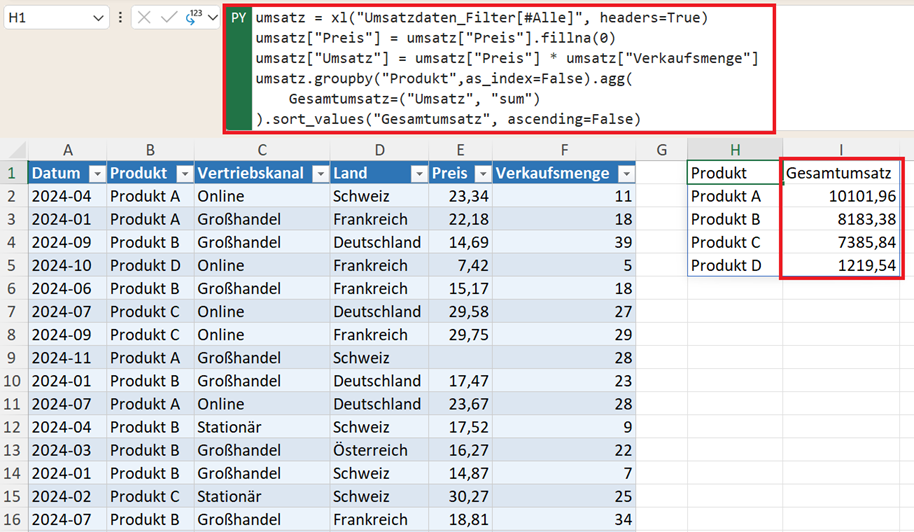
umsatz.groupby("Produkt",as_index=False).agg(
Gesamtumsatz=("Umsatz", "sum")
).sort_values("Gesamtumsatz", ascending=False)
So erhalten Sie sofort eine Rangliste Ihrer Produkte.
Kombination mit Filter
Schließlich können Sie die Daten mit den berechneten Kennzahlen nach einzelnen Merkmalen filtern. Mit diesem Python-Code werden nur die Kennzahlen berechnet und ausgegeben, die dem Filterkriterium entsprechen; hier Land = Deutschland:
umsatz = xl("Umsatzdaten_Filter[#Alle]", headers=True)
umsatz["Preis"] = umsatz["Preis"].fillna(0)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
umsatz[umsatz["Land"] == "Deutschland"].groupby("Produkt",as_index=False).agg(
Umsatz=("Umsatz", "sum"))
Zwei Fallstricke (für große Datenmengen)
groupby() sortiert standardmäßig nach dem Gruppen-Schlüssel. Mit sort=False beschleunigen Sie die Abfrage – besonders bei vielen Gruppen.
Wählen Sie vor groupby() nur die benötigten Spalten aus, um Speicher und Zeit zu sparen.
Wichtiger Unterschied in der Praxis: count vs. size
count zählt nur vorhandene Werte (ohne NaN), size zählt alle Zeilen. Den Unterschied zeigt die folgende Auswertung:
umsatz = xl("Umsatzdaten_Filter[#Alle]", headers=True)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
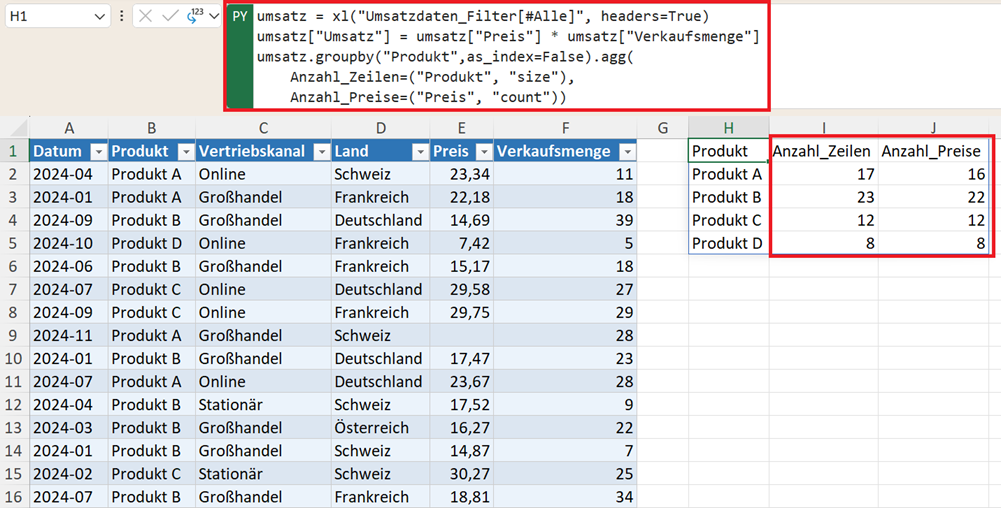
umsatz.groupby("Produkt",as_index=False).agg(
Anzahl_Zeilen=("Produkt", "size"),
Anzahl_Preise=("Preis", "count"))
Im folgenden Beispiel fehlen bei Produkt A und Produkt B ein Preiswert (NaN) – count erkennt das, size nicht.
Vergleich mit Excel
In Excel würden Sie eine Pivot-Tabelle erstellen, mehrere Felder in den Wertebereich ziehen und jedes einzeln konfigurieren.
Mit Pandas erledigen Sie das in einer einzigen, kompakten Code-Zeile. Zusätzlich ist der Ansatz reproduzierbar (der Code bleibt gleich), automatisierbar und deutlich robuster gegenüber Bedienfehlern – besonders bei großen Datenmengen.
Mit agg() können Sie:
- mehrere Kennzahlen gleichzeitig berechnen
- Daten strukturiert analysieren (auch bei Millionen von Zeilen)
- komplexe Controlling-Auswertungen automatisieren
- flexibel mit Funktionen wie count, std oder eigenen Berechnungen arbeiten
Und wie geht es weiter? Das Ergebnis einer Aggregation lässt sich direkt als Basis für ein Excel-Diagramm verwenden – wählen Sie dazu den Spill-Bereich aus und fügen Sie ein Balken- oder Säulendiagramm ein.
Alternativ können Sie das Ergebnis mit matplotlib direkt in Python visualisieren.