Python in Excel für die DatenanalyseNeue Spalten berechnen mit Pandas - Kennzahlen direkt im DataFrame erstellen
Warum berechnete Kennzahlen so wichtig sind
In der Praxis besteht Datenanalyse selten nur darin, vorhandene Daten auszuwerten. Der eigentliche Mehrwert entsteht oft erst dadurch, dass neue Kennzahlen berechnet werden.
Typische Beispiele aus dem Business-Alltag sind:
- Umsatz = Preis × Menge
- Durchschnittlicher Umsatz pro Kunde
- Rabatte und Margen
- Abweichungen (Soll vs. Ist)
In Excel würden Sie dafür neue Spalten anlegen und Formeln nach unten kopieren. Mit Pandas geht das deutlich einfacher – und vor allem fehlerfrei und reproduzierbar.
Wichtig: Für die folgenden Beispiele benötigen Sie die Bibliotheken Pandas und NumPy. In der Excel-Python-Umgebung (=PY) sind diese bereits verfügbar. Fügen Sie den Import dieser Bibliotheken einmalig ganz am Anfang Ihrer Python-Zelle ein:
import pandas as pd
import numpy as np
Datensatz laden
Zunächst laden Sie die Rohdaten aus der Tabelle „Umsatzdaten“ in Ihr DataFrame:
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz
Neue Spalte erstellen – Grundprinzip
Eine neue Spalte wird in Pandas sehr einfach erstellt:
umsatz["NeueSpalte"] = ...
Das bedeutet:
- links: DataFrame und Name der neuen Spalte (in Anführungszeichen) → umsatz["NeueSpalte"]
- rechts: Die Berechnung oder Logik → Ausdruck nach dem =
Umsatz berechnen (Vektorisierung)
Das Geniale an Pandas: Sie müssen keine Formeln „ziehen“. Pandas rechnet vektorisiert – das heißt, die Operation wird automatisch auf jede Zeile angewendet.
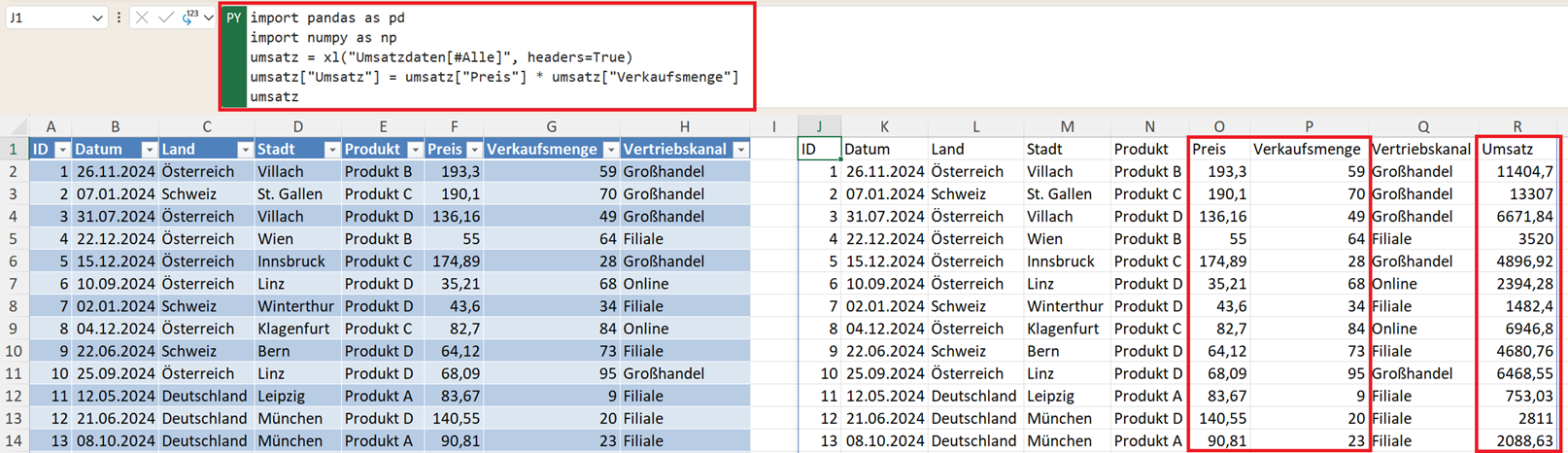
Um für jeden Verkauf (Transaktion = Datensatz) den Umsatz aus Preis und Verkaufsmenge zu berechnen, nutzen Sie den Befehl:
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
umsatz
Jetzt enthält der DataFrame eine zusätzliche Spalte "Umsatz".
Tipp: Prüfen Sie vor Berechnungen die Datentypen mit umsatz.dtypes. Falls nötig, wandeln Sie Spalten mit pd.to_numeric() um:
umsatz["Preis"] = pd.to_numeric(umsatz["Preis"], errors="coerce")
umsatz["Verkaufsmenge"] = pd.to_numeric(umsatz["Verkaufsmenge"], errors="coerce")
Durchschnittswerte und Aggregate
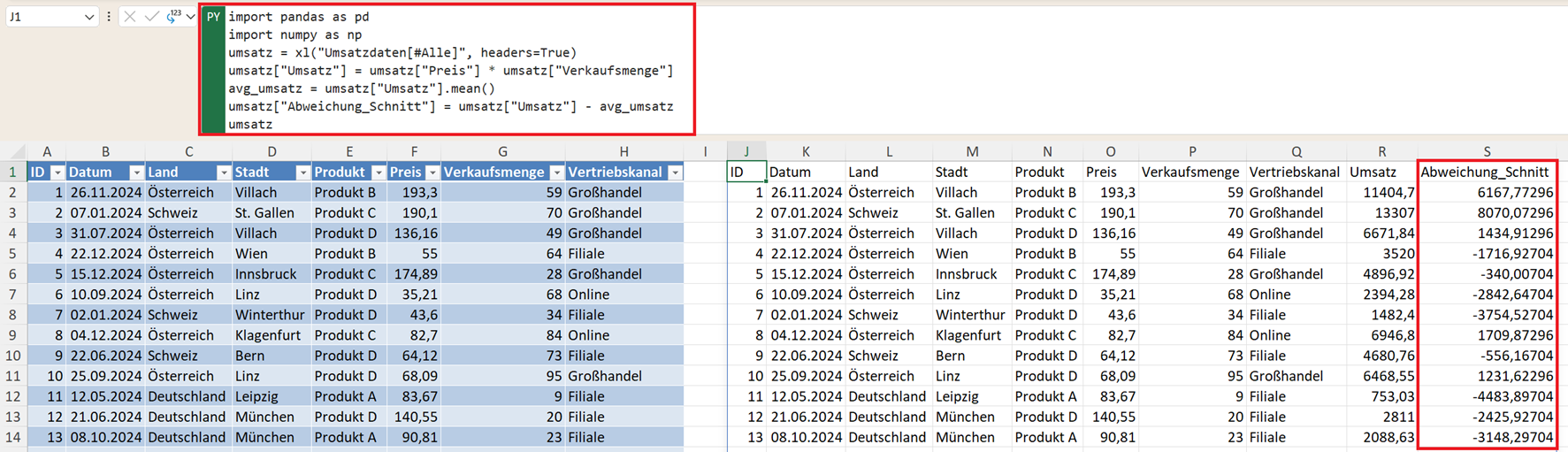
Oft möchte man wissen, wie eine einzelne Zeile im Vergleich zum Durchschnitt abschneidet. Dazu berechnen Sie den durchschnittlichen Umsatz pro Transaktion (Einzelwert):
avg_umsatz = umsatz["Umsatz"].mean()
Sowie die Abweichung vom Durchschnitt als neue Spalte:
umsatz["Abweichung_Schnitt"] = umsatz["Umsatz"] - avg_umsatz
Bedingte Berechnungen – das „WENN“ von Pandas
In Excel nutzen Sie WENN(). In Pandas gibt es dafür drei sehr einfache Methoden:
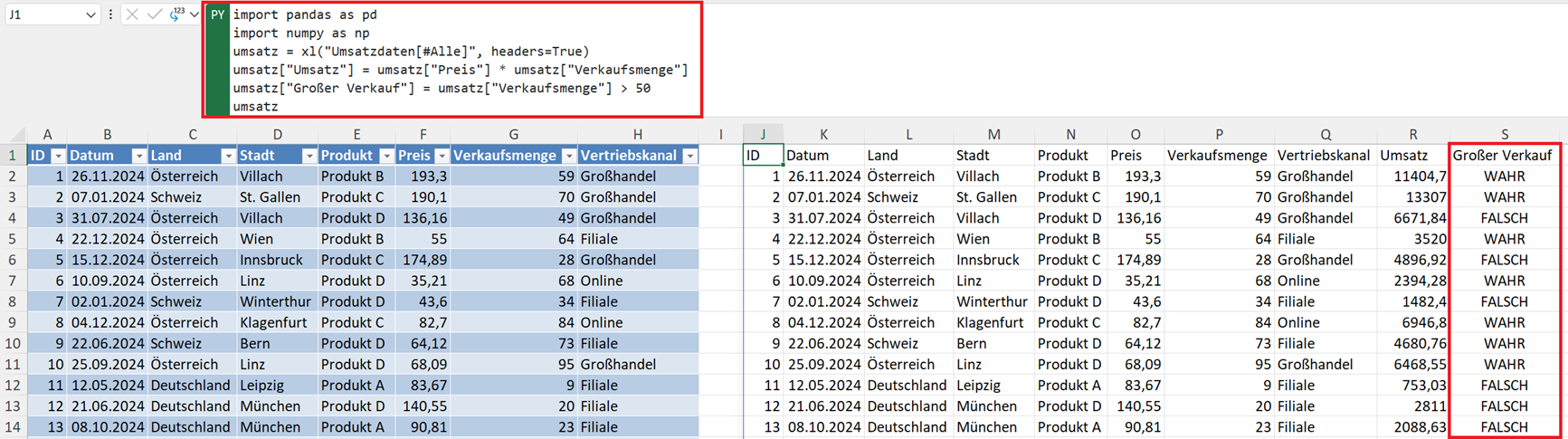
A. Einfache Logik (True/False)
umsatz["Großer Verkauf"] = umsatz["Verkaufsmenge"] > 50
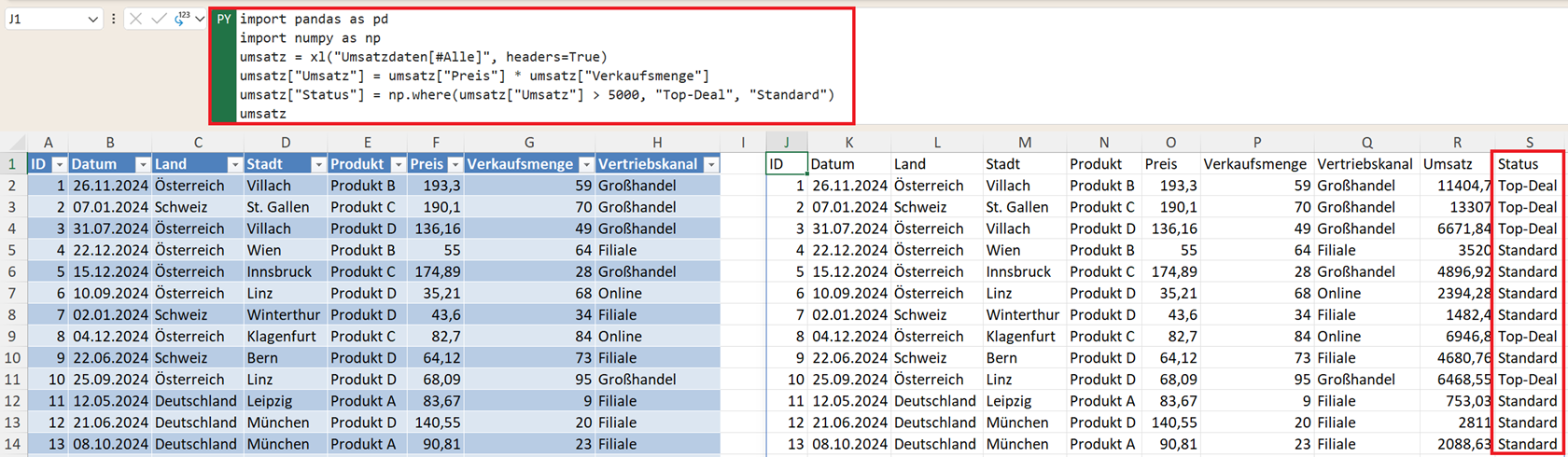
B. Das echte WENN mit numpy – np.where()
Für klassische „Wenn-Dann-Sonst“-Logik mit genau zwei Ausgängen ist die Python-Funktion np.where() ideal:
umsatz["Status"] = np.where(umsatz["Umsatz"] > 5000, "Top-Deal", "Standard")
C. Mehrere Bedingungen mit np.select()
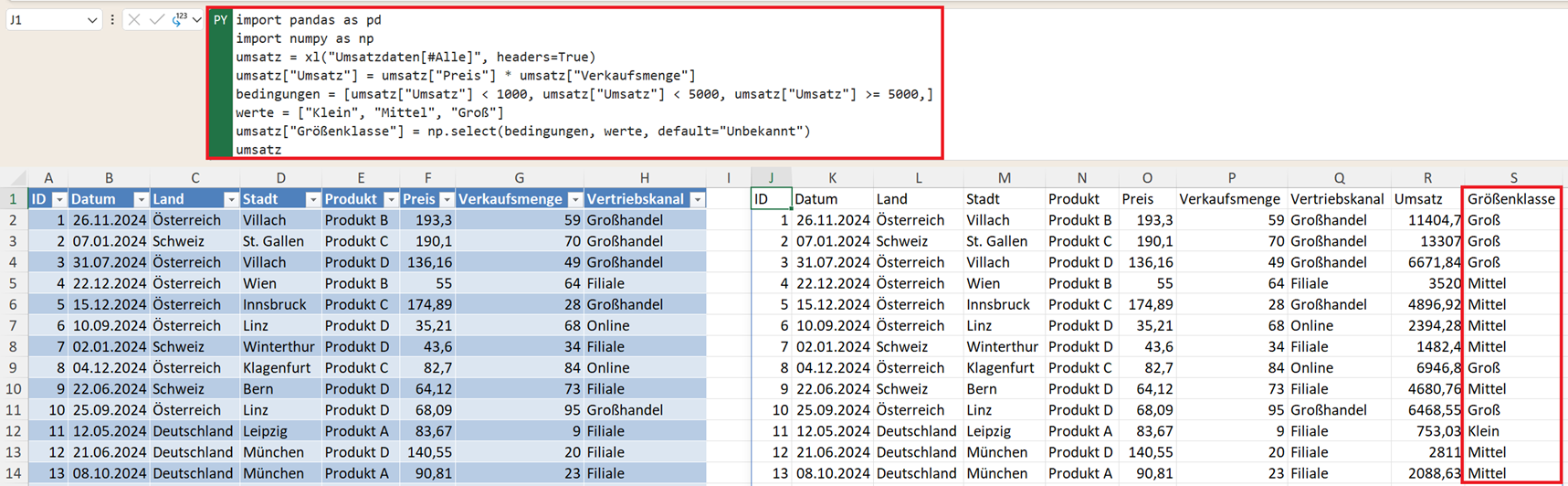
Sobald Sie mehr als zwei Ausgänge benötigen, wird np.select() zur besseren Alternative – lesbarer als mehrere .loc-Zeilen und flexibler als np.where():
bedingungen = [
umsatz["Umsatz"] < 1000,
umsatz["Umsatz"] < 5000,
umsatz["Umsatz"] >= 5000,
]
werte = ["Klein", "Mittel", "Groß"]
umsatz["Größenklasse"] = np.select(bedingungen, werte, default="Unbekannt")
Hinweis: np.select() prüft die Bedingungen der Reihe nach. Der erste Treffer gewinnt. Der Default-Wert greift, wenn keine Bedingung zutrifft.
Kategorien erstellen (Komplexe Bedingungen)
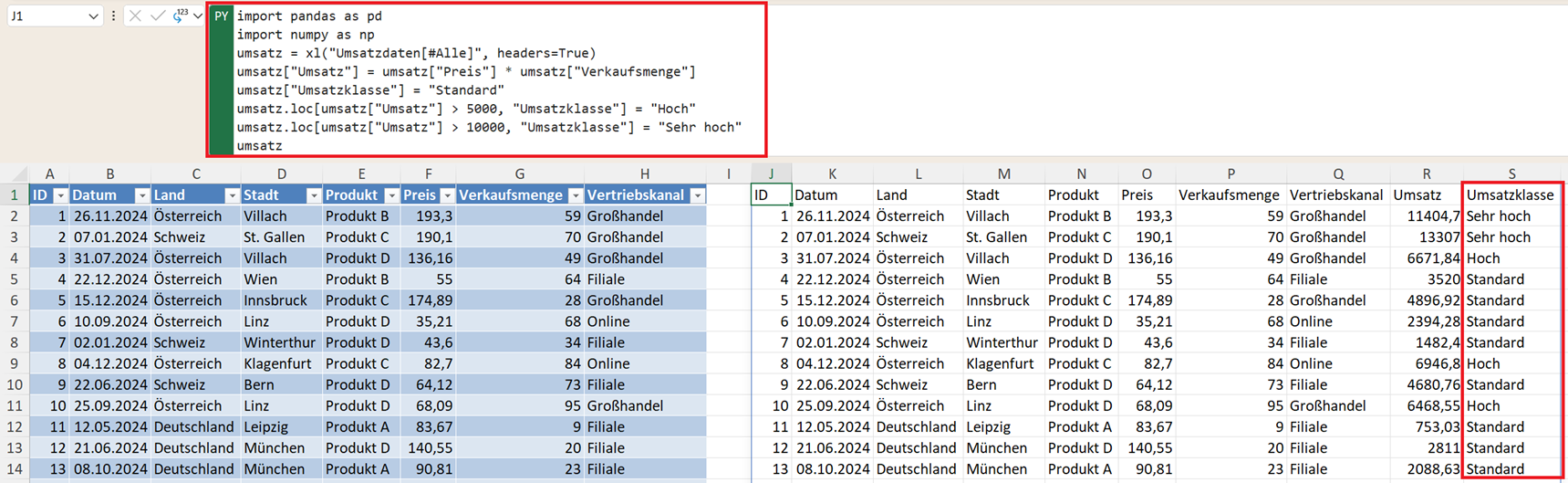
Für mehrere Stufen (wie eine Klassifizierung) nutzen Sie die .loc-Funktion:
umsatz["Umsatzklasse"] = "Standard"
umsatz.loc[umsatz["Umsatz"] > 5000, "Umsatzklasse"] = "Hoch"
umsatz.loc[umsatz["Umsatz"] > 10000, "Umsatzklasse"] = "Sehr hoch"
Allgemneine Syntax:
umsatz.loc[Zeilenbedingung, Spaltenname] = Wert
Textspalten verknüpfen
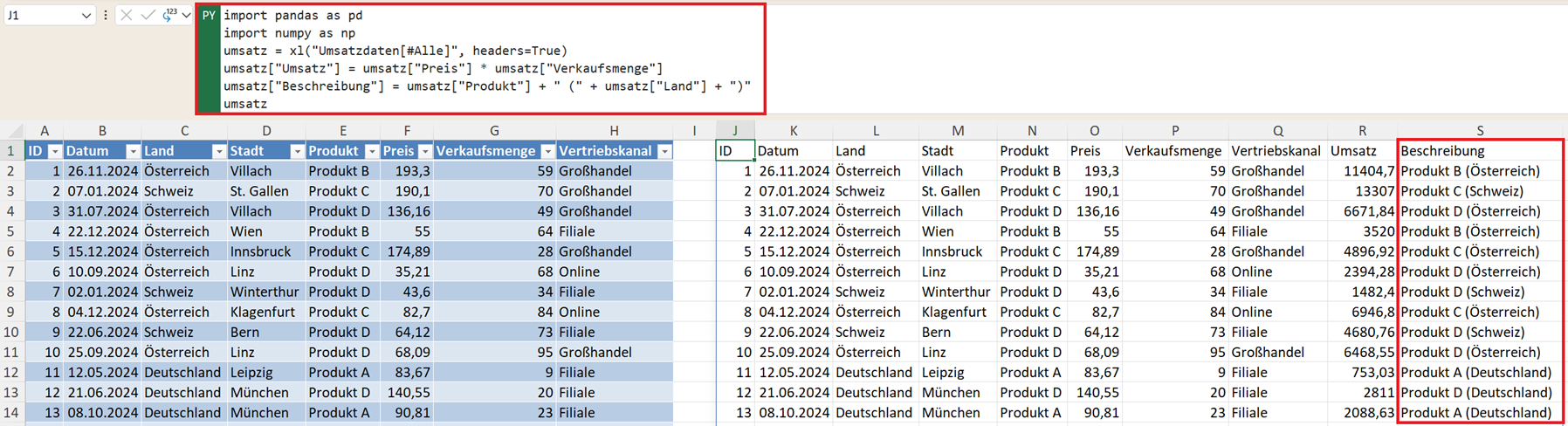
Nicht nur Zahlen, auch Text lässt sich komfortabel zu neuen Spalten kombinieren. Das Äquivalent zu =A1&" ("&B1&")" in Excel sieht in Pandas so aus:
umsatz["Beschreibung"] = umsatz["Produkt"] + " (" + umsatz["Land"] + ")"
Ergebnis wäre zum Beispiel: "Produkt B (Österreich)" oder "Produkt C (Schweiz)". Das funktioniert mit allen Textspalten und lässt sich beliebig erweitern.
Prozentwerte berechnen
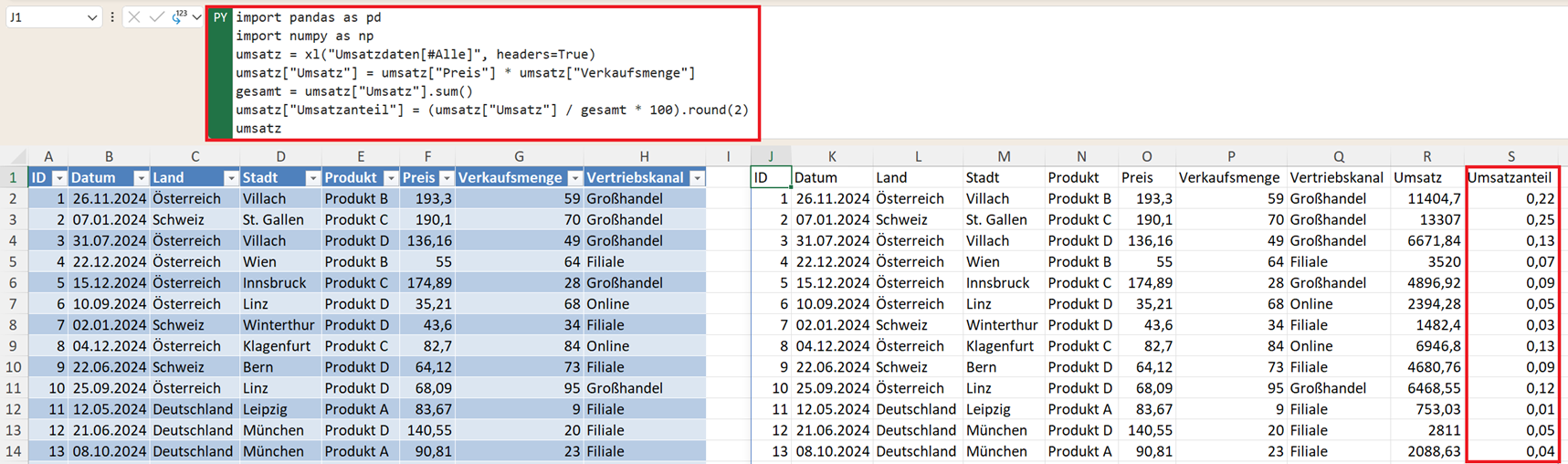
Ein weiteres Szenario im Controlling: Anteil am Gesamtumsatz (als Prozentwert, gerundet auf zwei Dezimalstellen) berechnen:
gesamt = umsatz["Umsatz"].sum()
umsatz["Umsatzanteil"] = (umsatz["Umsatz"] / gesamt * 100).round(2)
Fehlende Werte (NaN) behandeln
In Datensätzen kommen oft leere Zellen vor. Behandeln Sie diese mit fillna() vor den Berechnungen, sonst entstehen NaN-Ergebnisse:
Alle NaN in einer Spalte durch 0 ersetzen
umsatz["Umsatz"] = umsatz["Umsatz"].fillna(0)
Oder gezielt für mehrere Spalten
umsatz = umsatz.fillna({"Preis": 0, "Verkaufsmenge": 1})
Hinweis: Führen Sie die NaN-Behandlung idealerweise direkt nach dem Laden der Daten durch, bevor Sie mit Berechnungen beginnen.
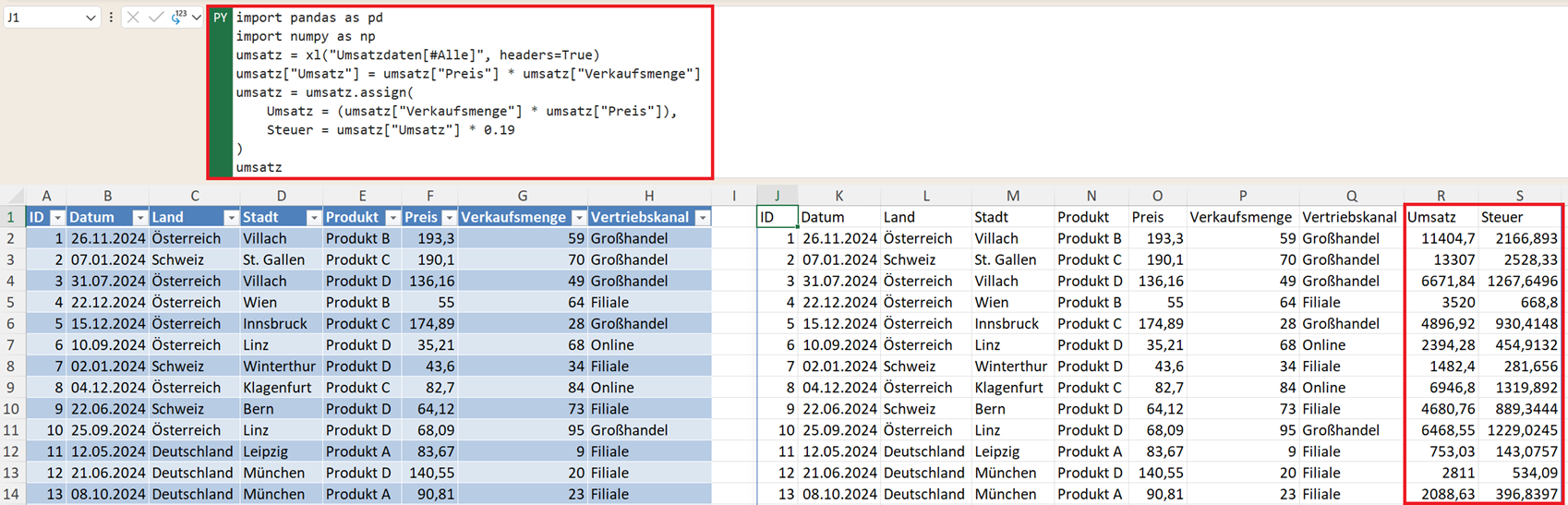
Mehrere Spalten erzeugen mit assign()
Wenn Sie viele Spalten gleichzeitig erstellen wollen, ohne den Variablennamen ständig zu wiederholen, nutzen Sie .assign():
umsatz = umsatz.assign(
Umsatz = (umsatz["Verkaufsmenge"] * umsatz["Preis"]),
Steuer = umsatz["Umsatz"] * 0.19
)
Warum Python-Berechnungen so mächtig sind
Die Vorteile von Python-Berechnungen gegenüber Excel sind:
- Keine Formeln kopieren: Einmal definiert, gilt die Logik für 10 oder 10 Millionen Zeilen.
- Keine „Lücken“: Es gibt keine Gefahr, dass eine Formel in Zeile 500 plötzlich aufhört.
- Fehlersuche: Wenn die Formel oben stimmt, stimmt sie überall.
- Dokumentation: Die Logik steht direkt im Code und ist für jeden nachvollziehbar.
- Performance: Vektorisierte Operationen sind extrem schnell – aber vermeiden Sie Schleifen (for-Schleifen über Zeilen), diese sind in Pandas sehr langsam.


