Python in Excel für die DatenanalyseDaten sortieren und Ranglisten erstellen mit Pandas in Python in Excel
Warum Sortieren in der Datenanalyse so wichtig ist
Die Sortierung von Daten wird in der Praxis ständig benötigt. Typische Fragen sind zum Beispiel:
- Welche Transaktionen haben den höchsten Umsatz?
- Welche Produkte wurden am häufigsten verkauft?
- In welchen Städten wurden die größten Mengen abgesetzt?
- Welche Artikel haben die niedrigsten Preise?
Natürlich lassen sich solche Fragestellungen auch direkt in Excel mit Filtern und Sortierfunktionen bearbeiten. Mit Pandas geht das jedoch reproduzierbar, sehr schnell und mit wenig Code.
Gerade bei größeren Datenbeständen ist das ein großer Vorteil. Statt manuell nach einer Spalte zu sortieren, definieren Sie die Logik einmal im Code und können sie jederzeit erneut anwenden.
Datensatz in Python laden
Grundlage der folgenden Datenanalyse ist: Sie nutzen Excel mit aktivierter Python-Integration. Die Funktion xl() greift dabei direkt auf Ihre Excel-Tabellen und die zu analysierenden Daten zu.
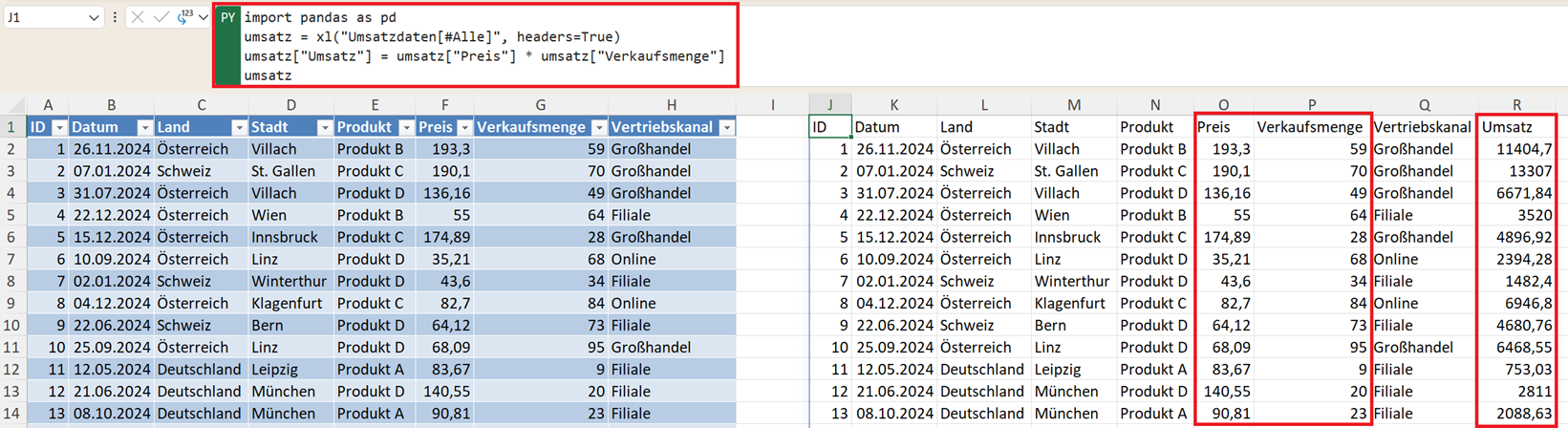
Zunächst laden Sie die Daten in einen DataFrame und berechnen die Kennzahl Umsatz, damit Sie diese für alle folgenden Analysen nutzen können. Der entsprechende Python-Code lautet:
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
umsatz
Nach einer Spalte sortieren – sort_values()
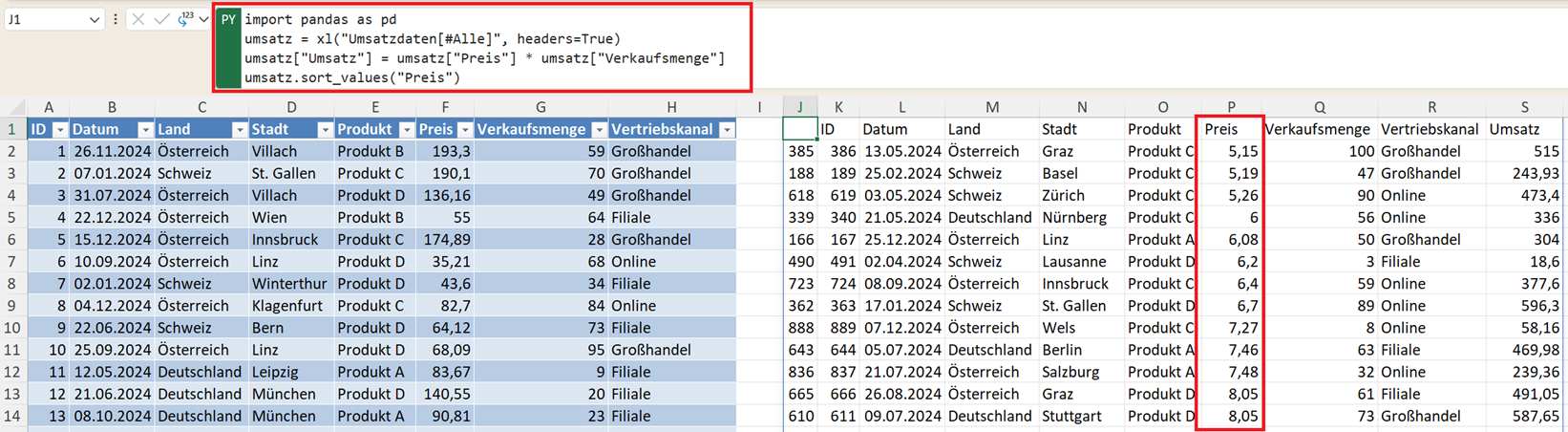
Die wichtigste Funktion zum Sortieren in Pandas ist sort_values(). Angenommen, Sie möchten die Daten nach dem Preis sortieren, dann lautet der Code:
umsatz.sort_values("Preis")
Standardmäßig sortiert Pandas aufsteigend (ascending=True). Das bedeutet: niedrige Preise stehen oben, hohe Preise unten.
Umgang mit leeren Zellen beim Sortieren
In Excel landen leere Zellen oft am Ende. In Pandas können Sie mit dem Parameter na_position steuern, ob Zeilen ohne Wert ganz oben ('first') oder ganz unten ('last') erscheinen sollen:
umsatz.sort_values("Preis", na_position='last')
Wichtig: sort_values() erstellt standardmäßig eine Kopie des DataFrames. Möchten Sie den ursprünglichen DataFrame dauerhaft sortieren, nutzen Sie den Parameter inplace=True:
umsatz.sort_values("Preis", inplace=True)
Daten absteigend sortieren
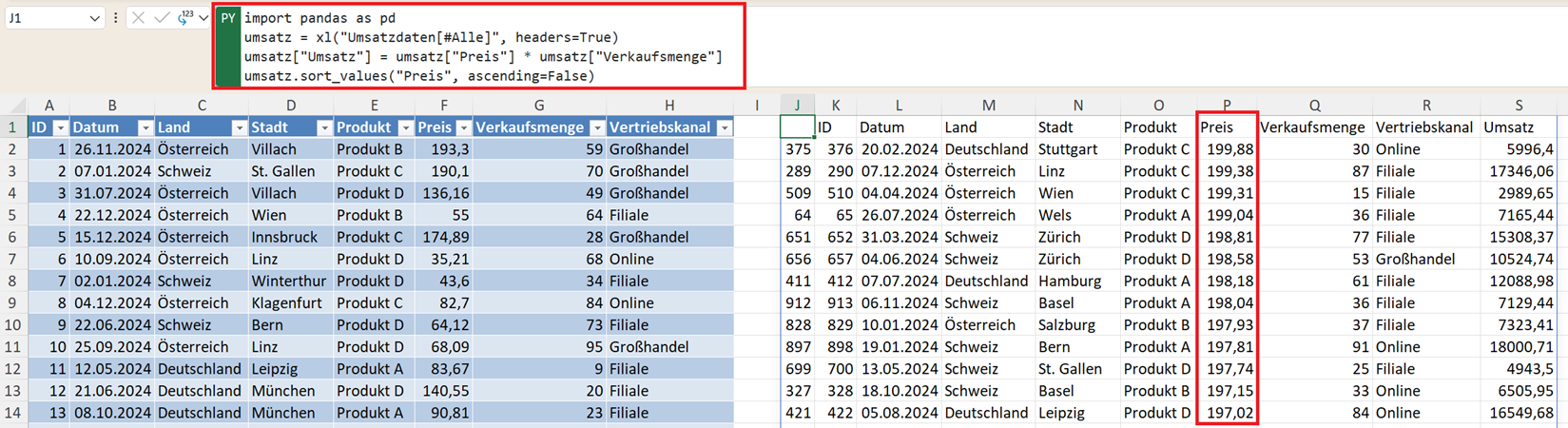
In vielen Business-Analysen interessiert jedoch nicht der kleinste, sondern der größte Wert. In diesem Fall nutzen Sie den Parameter ascending=False.
umsatz.sort_values("Preis", ascending=False)
Nun stehen die teuersten Produkte oben in Ihrer Liste. Das ist besonders hilfreich, wenn Sie schnell Top-Werte oder auffällige Datensätze finden möchten.
Nach mehreren Spalten sortieren
Häufig möchten Sie zuerst nach einem Kriterium und innerhalb dieser Gruppe nach einem weiteren sortieren. Dazu nutzen Sie den Befehl:
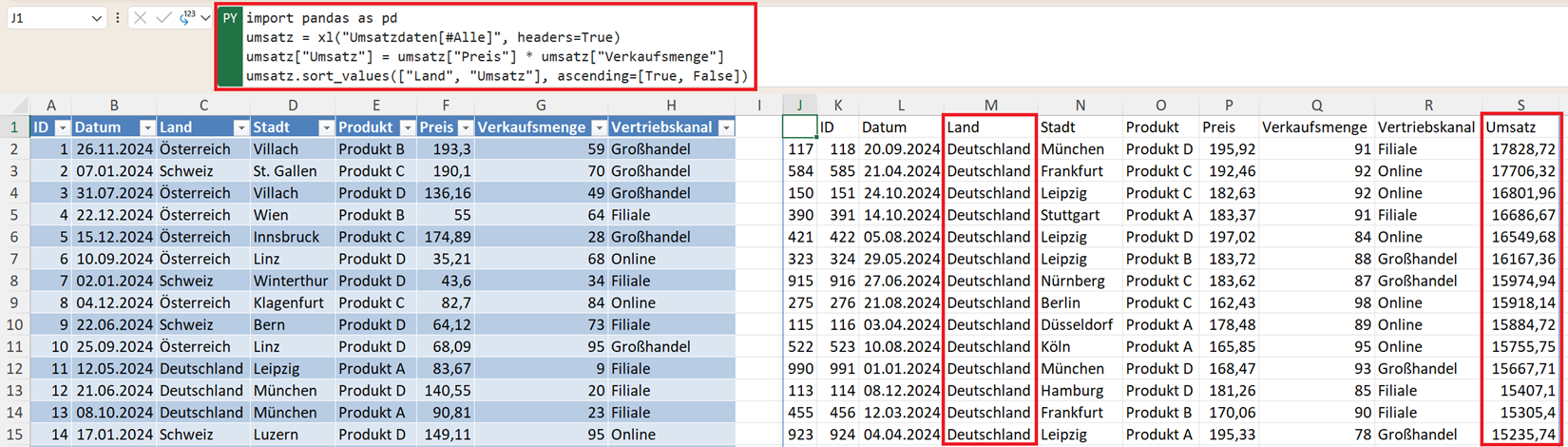
umsatz.sort_values(["Land", "Umsatz"], ascending=[True, False])
Was passiert hier?
- Zuerst werden die Datensätze alphabetisch nach Land sortiert.
- Innerhalb jedes Landes werden die Umsätze absteigend sortiert.
Daten nach Datum sortieren
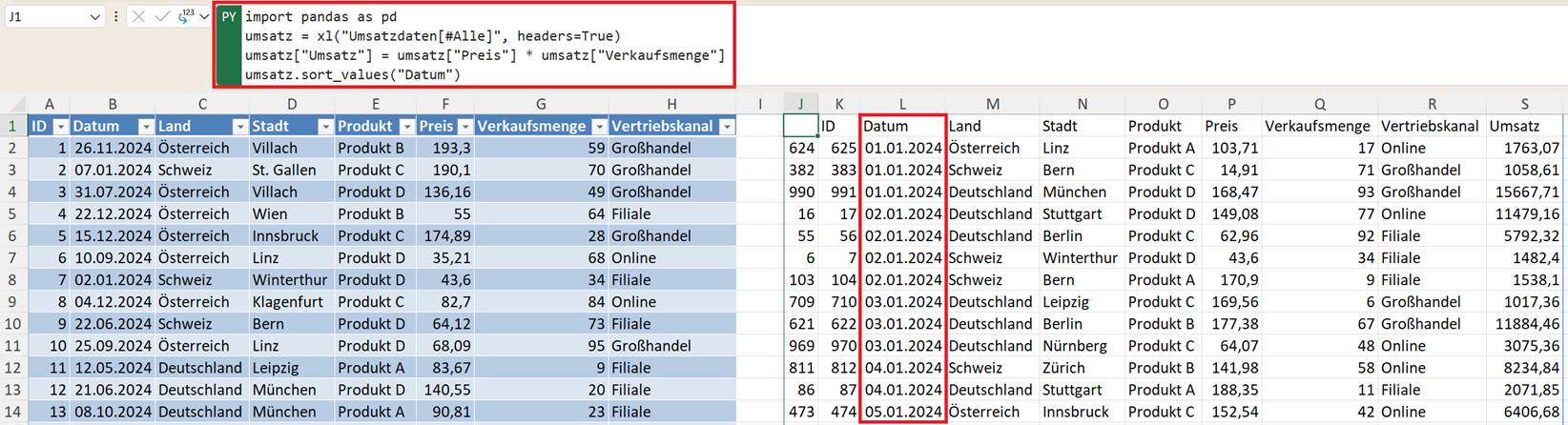
In der Praxis werden Daten häufig nach Datum sortiert. Um die ältesten Daten zuerst anzuzeigen, nutzen Sie den Code:
umsatz.sort_values("Datum")
Sollen die neuesten Daten oben stehen, wählen Sie:
umsatz.sort_values("Datum", ascending=False)
Die Top 10 anzeigen mit head() und nlargest()
Wenn Sie eine Rangliste erzeugen, möchten Sie meist nur die obersten Einträge sehen. Dafür gibt es zwei mögliche Befehle:
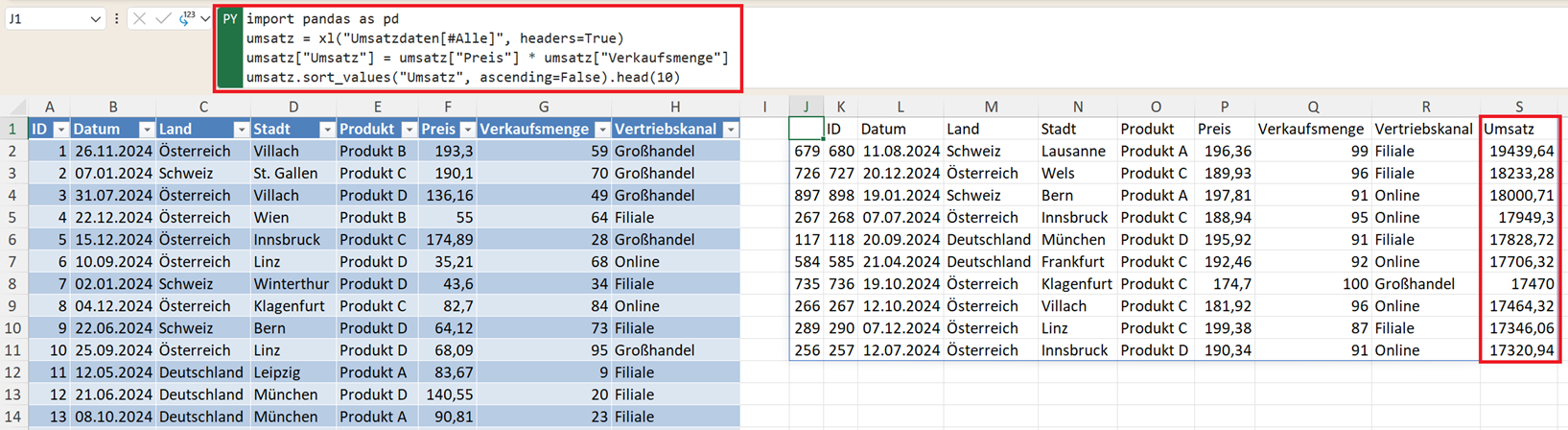
Variante A: Der klassische Weg
umsatz.sort_values("Umsatz", ascending=False).head(10)
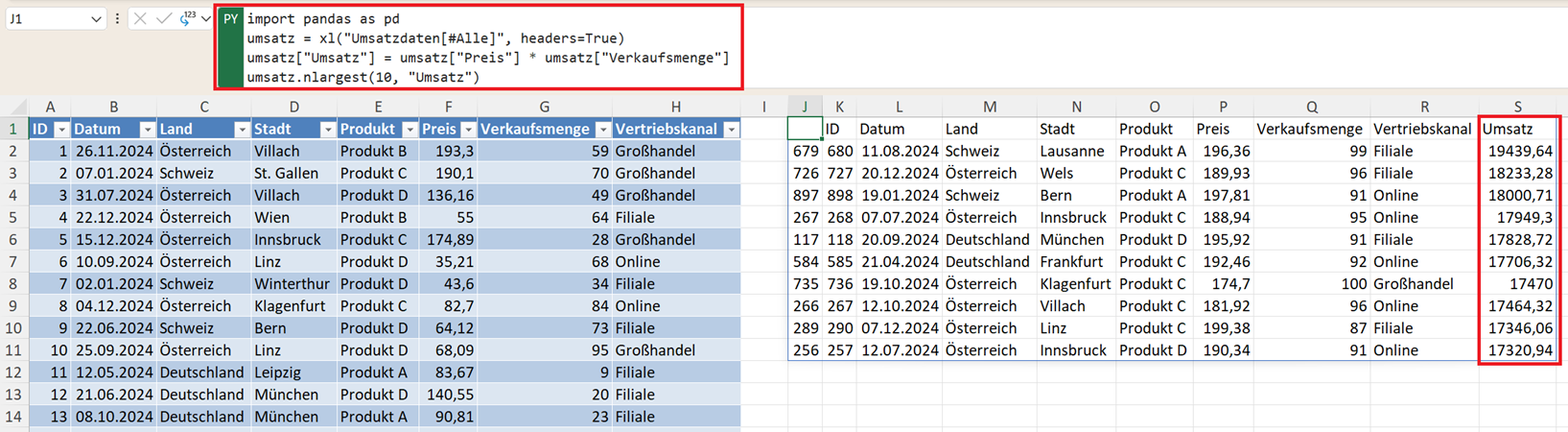
Variante B: Der spezialisierte Weg mit nlargest()
Pandas bietet für Ranglisten eine effizientere Funktion. nlargest() erledigt das Sortieren und das Begrenzen auf die Top-Werte in einem Schritt. So ermitteln Sie die 10 Datensätze mit dem größten Umsatz:
umsatz.nlargest(10, "Umsatz")
Für die kleinsten Werte nutzen Sie analog dazu nsmallest().
Tipp
nlargest() ist nicht nur bequemer, sondern bei großen Datensätzen (ab etwa 100.000 Zeilen) auch deutlich performanter als sort_values() + head(), da es nicht den gesamten DataFrame sortiert.
Gleichstände bei nlargest()
Was passiert, wenn mehrere Zeilen denselben Wert haben? Mit dem Parameter keep="all" werden alle Datensätze mit dem gleichen Wert in die Liste aufgenommen, auch wenn dadurch mehr als 10 Zeilen zurückgegeben werden:
umsatz.nlargest(10, "Umsatz", keep="all")
Vergleich mit Excel
In Excel würden Sie typischerweise Filter setzen, Spalten sortieren und die relevanten Zeilen manuell kopieren oder markieren. Das funktioniert gut, muss aber bei jeder Datenänderung wiederholt werden.
In Python definieren Sie die Logik einmal. Wenn sich Ihre Quelldaten in der Excel-Tabelle ändern, reicht ein Klick auf Alle aktualisieren, und Ihre Rangliste ist sofort wieder auf dem neuesten Stand.
Das spart Zeit und reduziert die Fehleranfälligkeit bei monatlichen Berichten.