Python in Excel für die DatenanalyseGruppierungen mit Pandas – Daten zusammenfassen und auswerten mit Python in Excel
- Warum Gruppierungen wichtig sind
- Datensatz laden und Umsatz berechnen
- So funktioniert groupby()
- Umsatz pro Land analysieren
- Mehrere Kennzahlen gleichzeitig berechnen (Named Aggregation)
- Gruppierung nach mehreren Dimensionen
- Top-Analysen erstellen
- Prozentuale Anteile berechnen
- Gruppierung nach Datum
- Vergleich mit Excel
- Die wichtigsten Aggregationen auf einen Blick
- Fazit
Warum Gruppierungen wichtig sind
In der Praxis der Datenanalyse stellt sich oft die Frage: Wie lassen sich Daten sinnvoll zusammenfassen? Typische „Fragen an die Daten“ sind:
- Wie hoch ist der Umsatz pro Land?
- Welche Produkte verkaufen sich am häufigsten?
- Welche Städte generieren den meisten Umsatz?
In Excel würden Sie dafür meist Pivot-Tabellen verwenden. In Pandas übernimmt diese Aufgabe die Funktion groupby().
Datensatz laden und Umsatz berechnen
Wir arbeiten für die folgenden Beispiele wieder mit einem Datensatz und laden diesen in den DataFrame.
umsatz = xl("Umsatzdaten_Filter[#Alle]", headers=True)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
umsatz
Hinweis zu den Spalten: Die folgenden Beispiele setzen Spalten wie „Land“, „Produkt“, „Stadt“, „Kunde“ und „Vertriebskanal“ voraus. Falls Ihr Datensatz diese nicht enthält, passen Sie die Spaltennamen einfach an.
So funktioniert groupby()
Die Logik hinter groupby() folgt dem sogenannten Split-Apply-Combine-Prinzip:
- Split: Die Daten werden nach einem Kriterium (zum Beispiel Land) in Gruppen geteilt.
- Apply: Auf jede Gruppe wird eine Funktion angewendet (zum Beispiel Summe oder Mittelwert).
- Combine: Die Ergebnisse werden wieder in einer Tabelle zusammengeführt.
Beispiel: Umsatz pro Land:
umsatz.groupby("Land")["Umsatz"].sum()
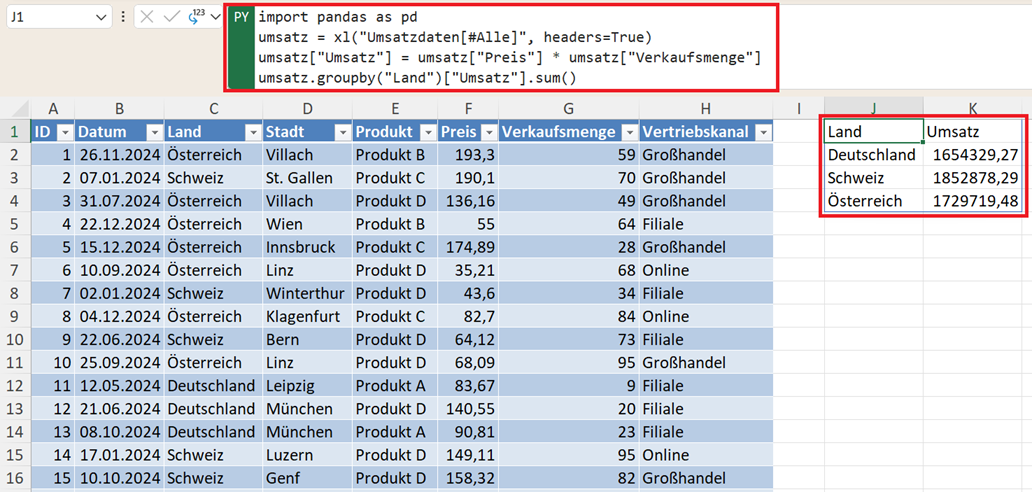
Umsatz pro Land analysieren
Wenn Sie das Ergebnis direkt als Tabelle in Excel weiterverwenden möchten, empfiehlt sich der Zusatz as_index=False. Ohne diesen Zusatz wird das „Land“ als fett gedruckte Zeilenüberschrift (Index) formatiert, was die Weiterverarbeitung in Excel erschweren kann.
umsatz.groupby("Land", as_index=False)["Umsatz"].sum()
Damit sehen Sie sofort:
- welches Land den höchsten Umsatz erzielt
- wie sich der Umsatz verteilt
Tipp zum Umgang mit leeren Werten (NaN): Standardmäßig ignoriert groupby() fehlende Werte in der Gruppenspalte. Wenn Sie auch NaN als eigene Gruppe anzeigen möchten, nutzen Sie:
umsatz.groupby("Land", dropna=False)["Umsatz"].sum()
Mehrere Kennzahlen gleichzeitig berechnen (Named Aggregation)
Sehr häufig möchte man mehrere Kennzahlen gleichzeitig analysieren. In Pandas können Sie die neuen Spalten dabei direkt benennen, damit die Tabelle sofort reporting-fähig ist.
Der entsprechende Befehl lautet:
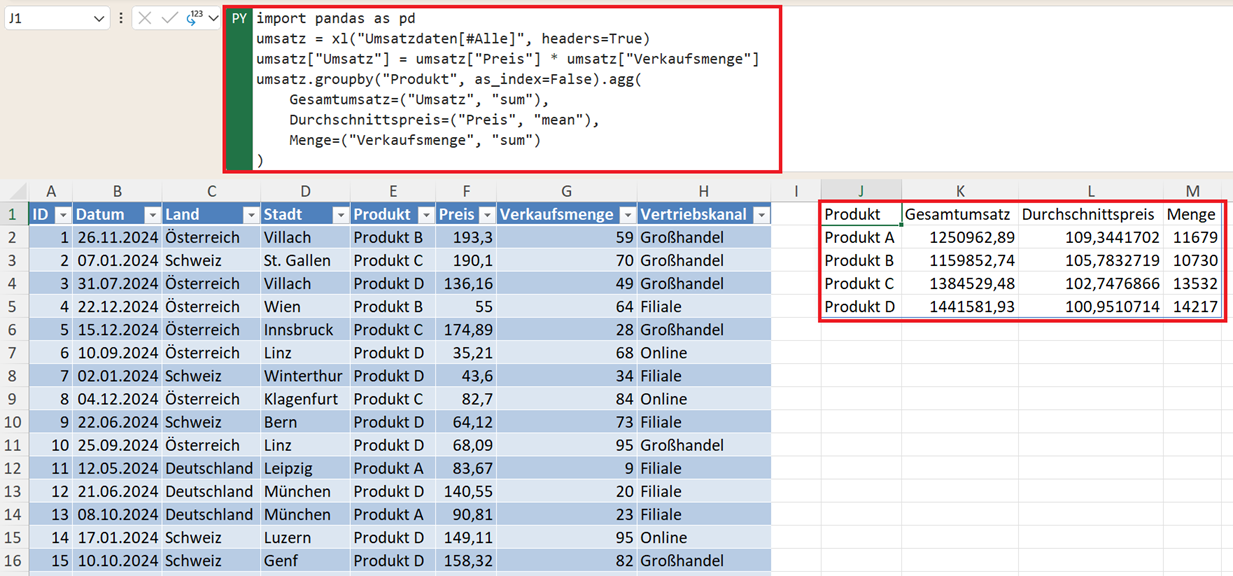
umsatz.groupby("Produkt", as_index=False).agg(
Gesamtumsatz=("Umsatz", "sum"),
Durchschnittspreis=("Preis", "mean"),
Menge=("Verkaufsmenge", "sum")
)
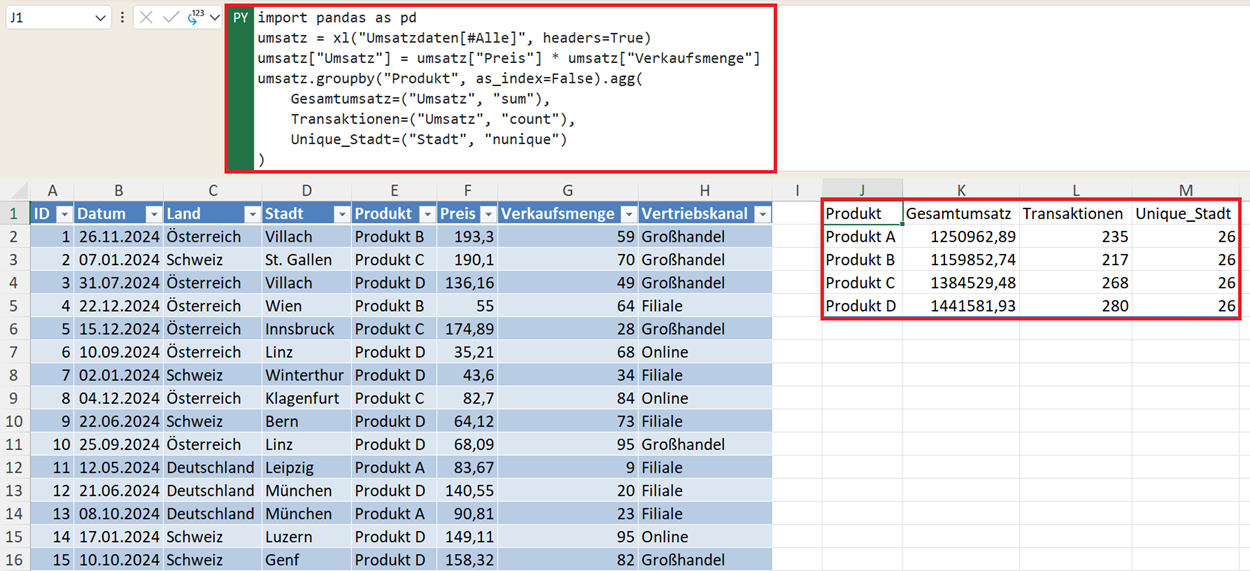
Das ist eine typische Controlling-Auswertung. Es wird nach Produkten gruppiert und der Gesamtumsatz, Durchschnittspreis und Menge werden als Aggregationen angezeigt.
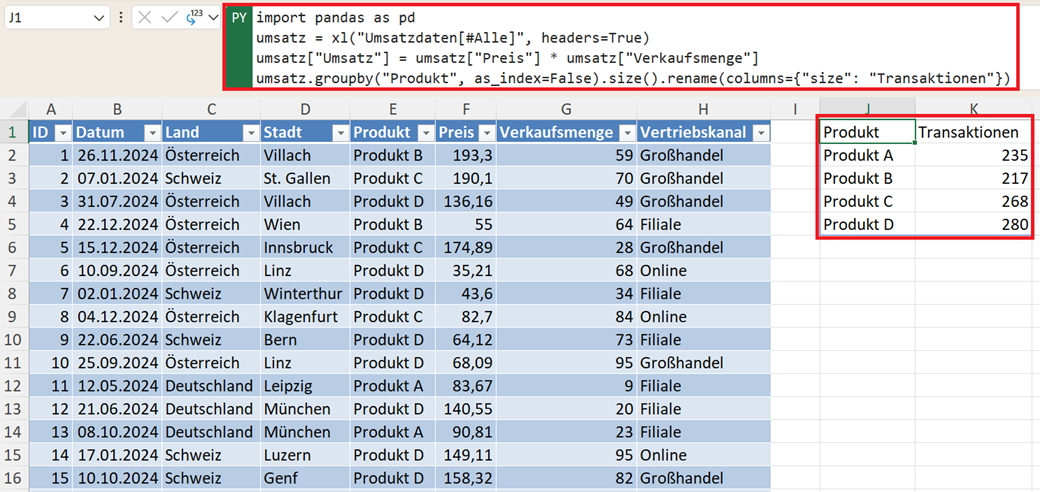
Weitere häufige Aggregationen
Neben Summe und Mittelwert sind oft auch die Anzahl der Zeilen pro Gruppe oder die Anzahl eindeutiger Werte nützlich:
umsatz.groupby("Produkt", as_index=False).size().rename(columns={"size": "Transaktionen"})
Oder direkt in Named Aggregation integriert für die Anzahl der Städte (eindeutige Werte):
umsatz.groupby("Produkt", as_index=False).agg(
Gesamtumsatz=("Umsatz", "sum"),
Transaktionen=("Umsatz", "count"),
Unique_Kunden=("Kunde", "nunique")
)
Gruppierung nach mehreren Dimensionen
Im nächsten Schritt können Sie – wie bei einer Pivot-Tabelle mit mehreren Zeilenfeldern – Daten auch nach mehreren Kriterien gruppieren.
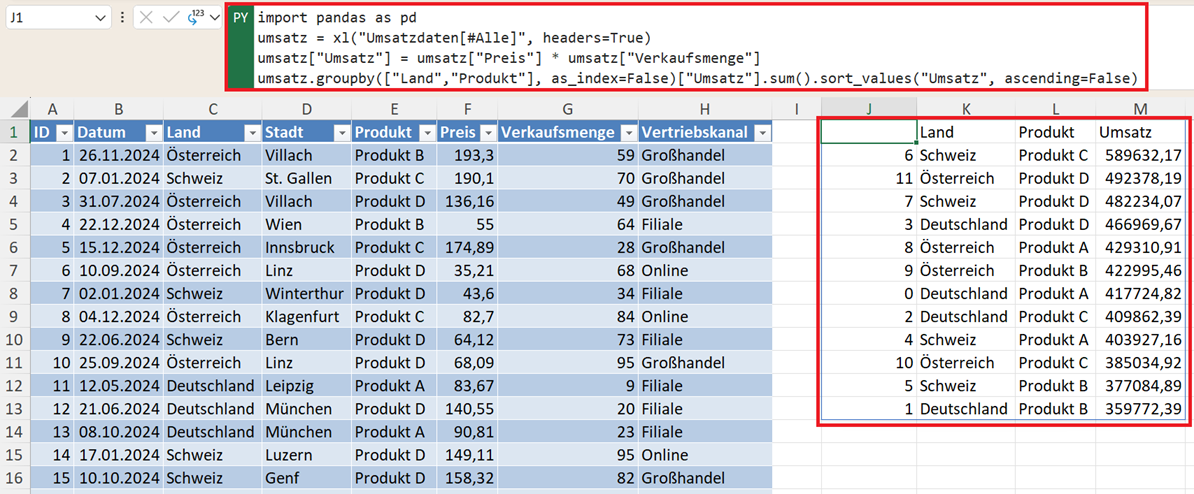
Beispiel: Umsatz pro Land und Produkt:
umsatz.groupby(["Land", "Produkt"], as_index=False)["Umsatz"].sum() .sort_values("Umsatz", ascending=False)
Das Ergebnis ist eine mehrdimensionale Analyse in Tabellenform – und durch das direkte Sortieren erhalten Sie sofort eine Rangliste.
Top-Analysen erstellen
Die Ergebnisse lassen sich direkt sortieren und auf die wichtigsten Einträge mit der Funktion head() reduzieren.
Beispiel: Top-5-Produkte nach Umsatz:
umsatz.groupby("Produkt", as_index=False)["Umsatz"].sum() \
.sort_values("Umsatz", ascending=False) \
.head(5)
Damit erhalten Sie eine Rangliste der Produkte – und mit .head(5) direkt die fünf stärksten.
Tipp: Möchten Sie nur Gruppen berücksichtigen, die eine Mindestbedingung erfüllen, nutzen Sie filter(). Damit lassen sich zum Beispiel nur Länder anzeigen, die einen Gesamtumsatz von mehr als 10.000 EUR erreichen:
umsatz.groupby("Land").filter(lambda x: x["Umsatz"].sum() > 10000)
Prozentuale Anteile berechnen
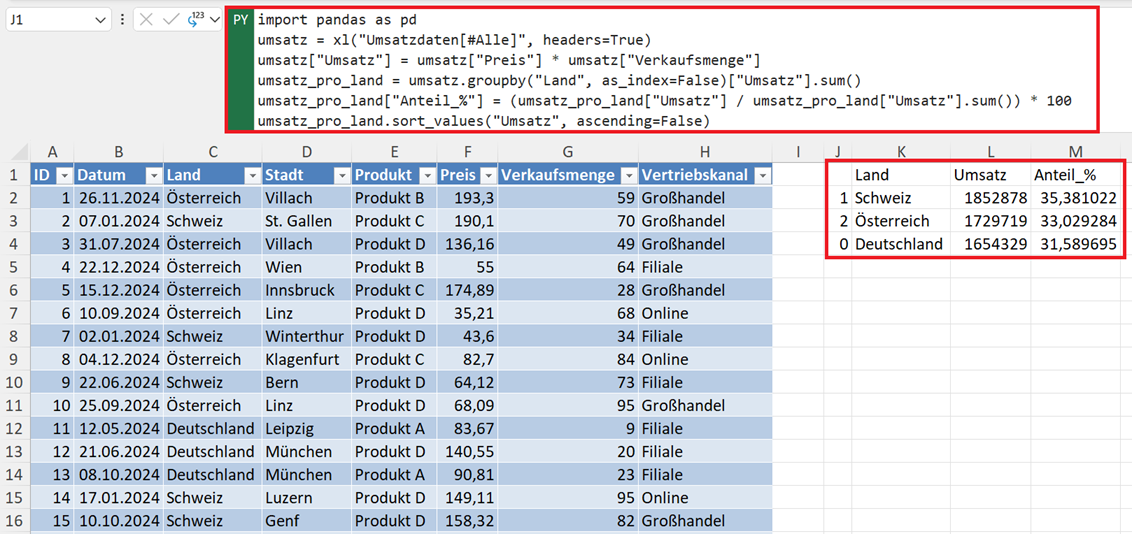
Excel-Nutzer fragen oft nach Anteilen an der Gesamtsumme. So berechnen Sie Prozentwerte in Pandas:
umsatz_pro_land = umsatz.groupby("Land", as_index=False)["Umsatz"].sum()
umsatz_pro_land["Anteil_%"] = (umsatz_pro_land["Umsatz"] /
umsatz_pro_land["Umsatz"].sum()) * 100
umsatz_pro_land.sort_values("Umsatz", ascending=False)
Prozentualer Anteil auf Zeilenebene mit transform()
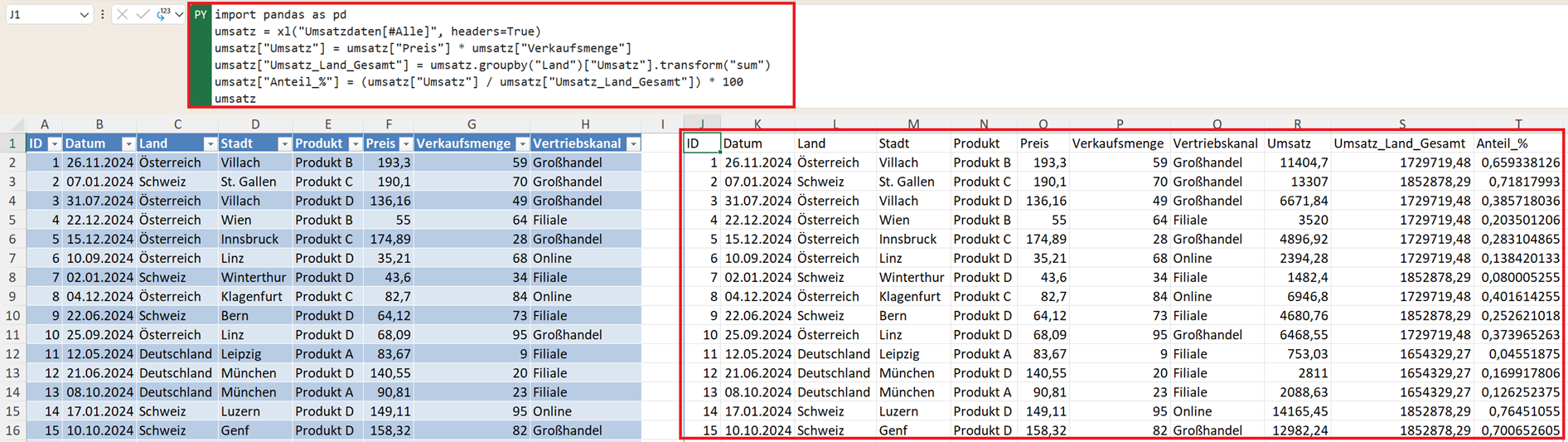
Möchten Sie den prozentualen Anteil nicht als separate Tabelle, sondern direkt als neue Spalte im ursprünglichen Datensatz hinzufügen, verwenden Sie transform(). Damit wird der Gruppengesamtwert auf jede einzelne Zeile zurückgeschrieben:
umsatz["Umsatz_Land_Gesamt"] = umsatz.groupby("Land")["Umsatz"].transform("sum")
umsatz["Anteil_%"] = (umsatz["Umsatz"] / umsatz["Umsatz_Land_Gesamt"]) * 100
umsatz
Der Vorteil: Jede Zeile enthält direkt ihren prozentualen Anteil am Umsatz des jeweiligen Landes – praktisch für detaillierte Berichte.
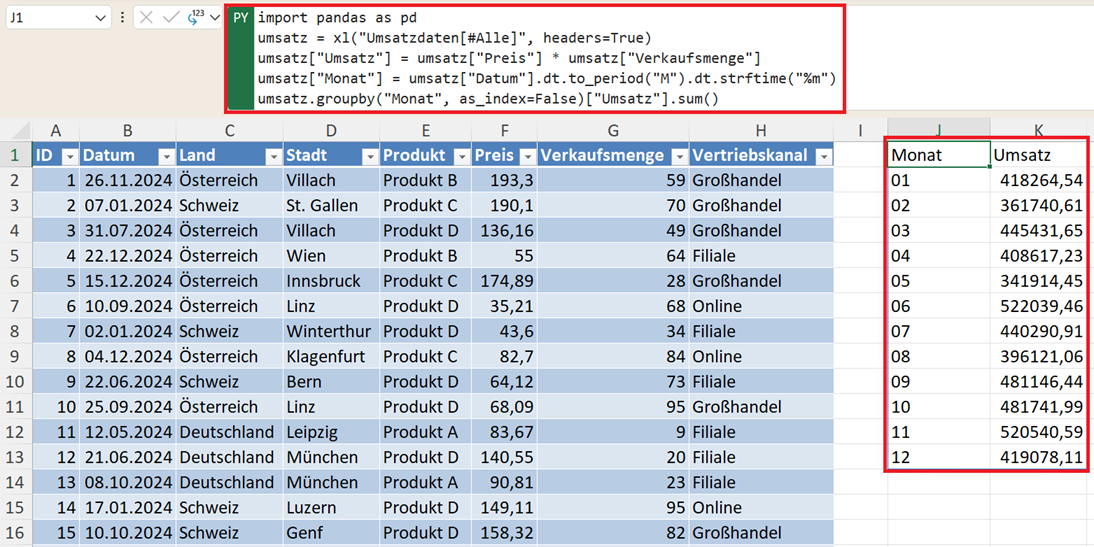
Gruppierung nach Datum
Zeitliche Auswertungen sind in der Praxis sehr häufig. Pandas bietet flexible Möglichkeiten, Daten nach verschiedenen Zeitperioden zu gruppieren:
Voraussetzung: Es gibt eine Spalte „Datum“ im Datentyp datetime.
So gruppieren Sie nach Monat:
umsatz["Monat"] = umsatz["Datum"].dt.to_period("M").dt.strftime("%m")
umsatz.groupby("Monat", as_index=False)["Umsatz"].sum()
Weitere nützliche Gruppierungen nach Zeitperioden
Nach Quartal gruppieren:
umsatz["Quartal"] = umsatz["Datum"].dt.to_period("Q").dt.strftime("%q")
Nach Jahr gruppieren:
umsatz["Jahr"] = umsatz["Datum"].dt.to_period("Y").dt.strftime("%y")
Nach Wochentag gruppieren:
umsatz["Wochentag"] = umsatz["Datum"].dt.day_name()
So lassen sich Saisonalitäten, Wachstumstrends oder Wochentag-Muster mit minimalem Aufwand aufdecken.
Vergleich mit Excel
In Excel würden Sie:
- Pivot-Tabelle erstellen
- Felder ziehen
- Werte aggregieren
Mit Pandas: eine Zeile Code. Das spart Zeit, ist weniger fehleranfällig bei neuen Daten und vollständig reproduzierbar.
Wichtiger Tipp für die Ausgabe: Damit die Ergebnisse in Ihren Excel-Zellen erscheinen, klicken Sie mit der rechten Maustaste auf die Ausgabezelle und wählen Sie "Als Excel-Wert anzeigen" (statt "Python-Objekt"). Alternativ finden Sie diese Option im Excel-Menü unter Formeln → Python → Wert zurückgeben.
Die wichtigsten Aggregationen auf einen Blick
Hier eine Übersicht mit wichtigen Aggregations-Funktionen in Pandas und ihre Bedeutung:
- sum(): Summe
- mean(): Durchschnitt
- count(): Anzahl der Zeilen (NaN wird ignoriert)
- size(): Anzahl der Zeilen (NaN wird mitgezählt)
- nunique(): Anzahl eindeutiger Werte
- min() / max(): Minimum / Maximum
- std(): Standardabweichung
- transform(): Gruppenkenngröße auf Zeilenebene zurückschreiben
- filter(): Gruppen nach Bedingung ein- oder ausschließen
Fazit
Die Funktion groupby() ist eines der wichtigsten Werkzeuge in Pandas. Sie ermöglicht es:
- Daten blitzschnell zusammenzufassen
- Kennzahlen präzise zu berechnen
- komplexe Business-Analysen mit minimalem Aufwand durchzuführen
Die Grundstruktur lautet immer:
df.groupby(["Gruppenspalte(n)"], as_index=False)["Kennzahl"].Aggregation()
Oder mit Named Aggregation:
df.groupby("Gruppenspalte", as_index=False).agg(NeueSpalte=("Kennzahl", "sum"))