Python in Excel für die DatenanalyseKennzahlen der explorativen Datenanalyse mit Pandas
- Warum explorative Datenanalyse wichtig ist
- Struktur eines DataFrames untersuchen – die info()-Funktion
- Erklärung der wichtigsten Datentypen
- Datentypen anzeigen – dtypes
- Statistische Kennzahlen berechnen – describe()
- Fehlende Werte schnell erkennen – isna().sum()
- Vergleich mit klassischen Excel-Formeln
- Analyse übersichtlicher darstellen – transpose()
- Wann ist eine transponierte Darstellung sinnvoll?
Warum explorative Datenanalyse wichtig ist
Für die Datenanalyse und das Erstellen von Reports braucht es zunächst ein Verständnis dafür, wie die Daten strukturiert sind. In der Datenanalyse spricht man dabei von explorativer Datenanalyse (englisch: Exploratory Data Analysis, kurz EDA).
Typische Fragen dabei sind:
- Welche Spalten enthält mein Datensatz?
- Welche Datentypen liegen vor?
- Wie viele Datensätze sind vorhanden?
- Wie verteilen sich die Werte?
- Gibt es Ausreißer oder fehlende Werte?
Gerade in der Praxis stammen Daten häufig aus verschiedenen Quellen, zum Beispiel aus ERP-Systemen, CRM-Systemen oder anderen Datenbanken. Beim Export nach Excel können dabei Datentypen falsch interpretiert werden oder Daten enthalten unerwartete Werte. Eine standardisierte, explorative Analyse hilft, typische Probleme frühzeitig zu erkennen.
In Excel lassen sich viele der genannten Fragen beantworten – allerdings meist nur mit mehreren Formeln oder manuellen Zwischenschritten.
Python und die Bibliothek Pandas bieten hierfür einige sehr leistungsfähige Funktionen. Mit wenigen Befehlen lassen sich Struktur, Datentypen und statistische Kennzahlen eines Datensatzes schnell ermitteln.
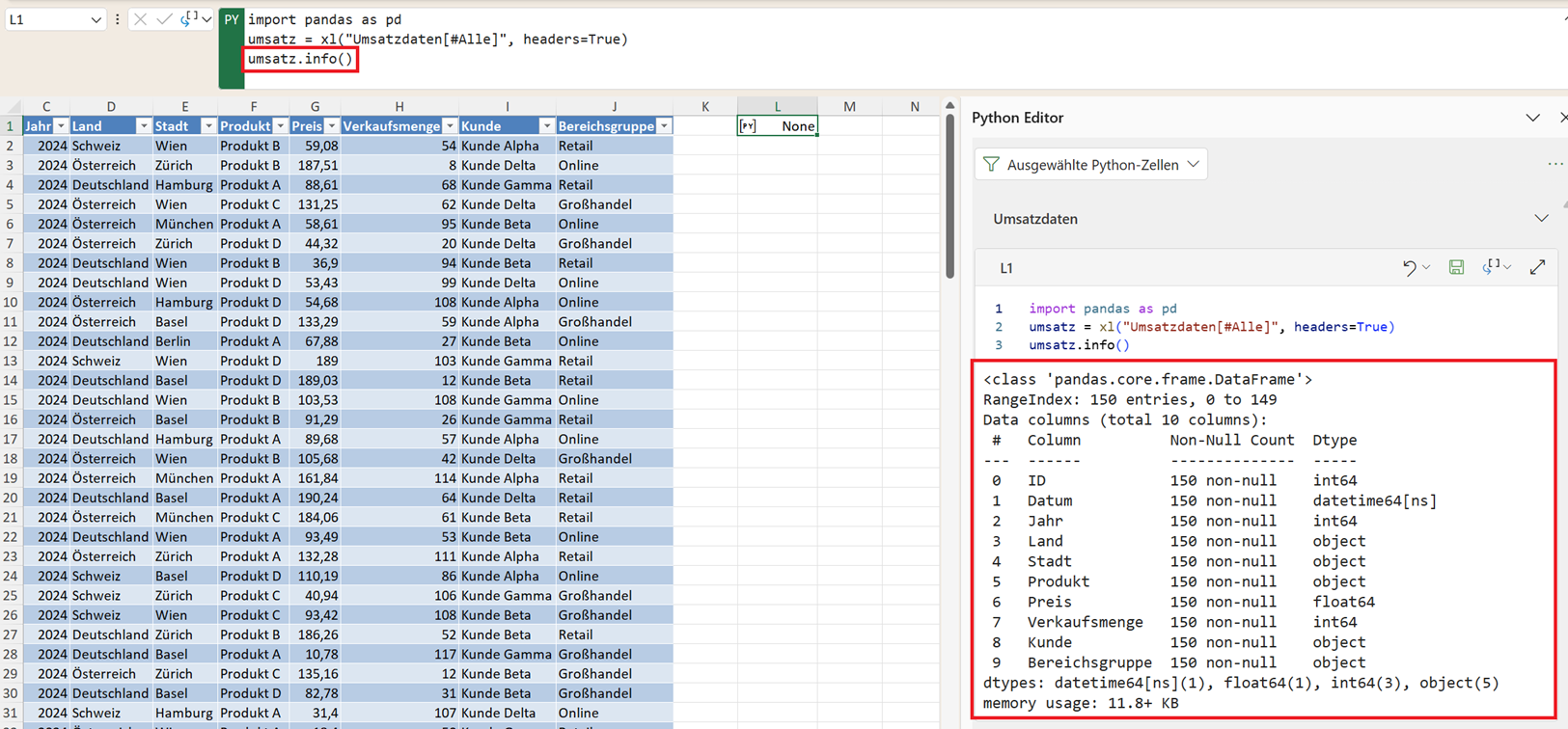
Struktur eines DataFrames untersuchen – die info()-Funktion
Angenommen, Ihr DataFrame heißt umsatz. Dann können Sie sich zunächst grundlegende Informationen über diesen Datensatz anzeigen lassen. Dazu verwenden Sie die Funktion info():
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz.info()
Nach dem Ausführen erscheint im Diagnosefenster (Aufgabenbereich) von Python in Excel eine Übersicht über den DataFrame. Diese Übersicht enthält unter anderem:
- den Objekttyp (pandas DataFrame)
- die Anzahl der Datensätze
- die Spaltennamen
- die Datentypen jeder Spalte
- die Anzahl der nicht-leeren Werte je Spalte
Damit erhalten Sie einen schnellen Überblick über die Struktur Ihrer Daten.
Erklärung der wichtigsten Datentypen
- int64 Ganzzahl (Integer): Dieser Datentyp wird typischerweise für Zählwerte oder IDs verwendet.
- float64 Fließkommazahl: Dieser Datentyp wird häufig für Preise, Umsätze oder andere numerische Werte mit Dezimalstellen verwendet.
- object Text oder Zeichenkette: In Pandas werden viele Textfelder zunächst als „object“ klassifiziert.
- datetime64 Datumswert: Dieser Datentyp ermöglicht später Zeitreihenanalysen oder Datumsberechnungen.
Gerade bei Datenimporten ist diese Übersicht extrem hilfreich. Sie erkennen sofort, ob Datentypen korrekt interpretiert wurden oder ob beispielsweise eine Zahlenspalte versehentlich als Text eingelesen wurde.
Das spart später viel Zeit bei der Datenanalyse.
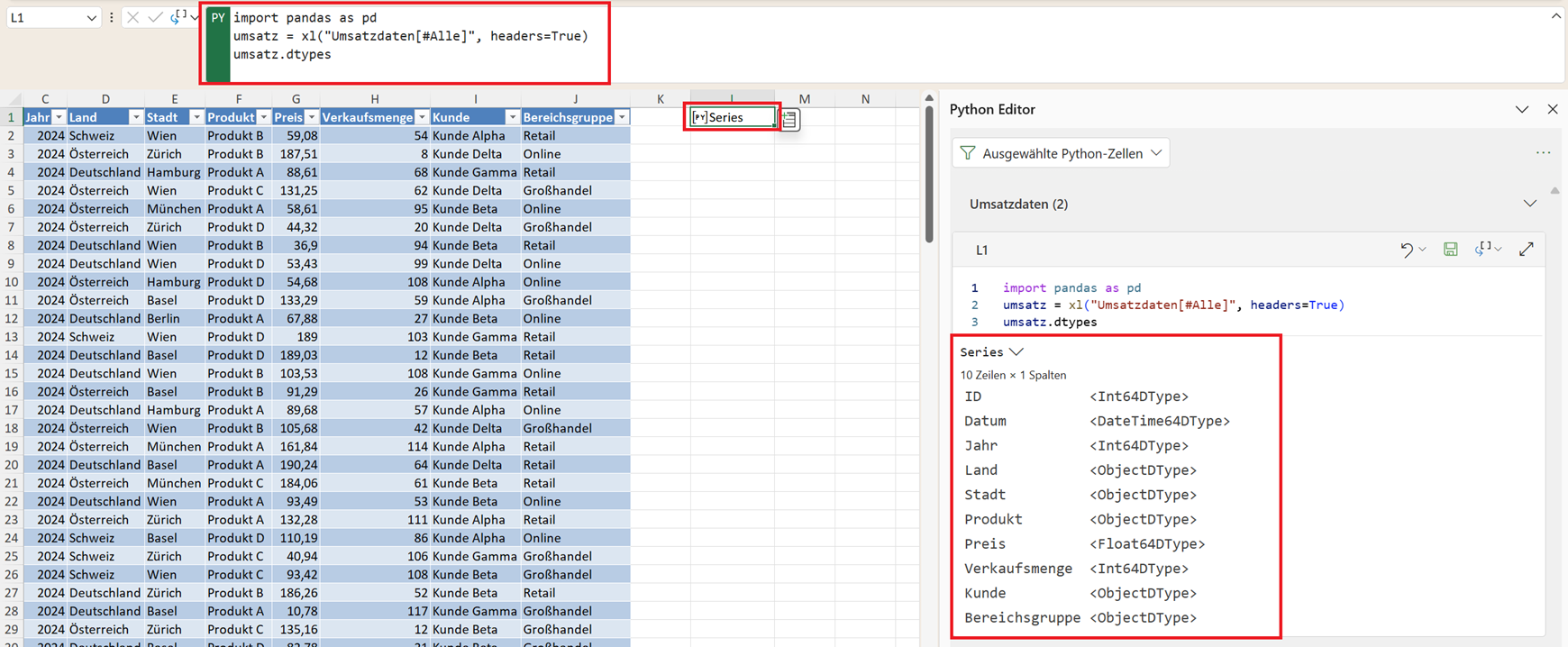
Datentypen anzeigen – dtypes
Während die Funktion info() einen allgemeinen Überblick über die Struktur eines DataFrames liefert, kann es manchmal hilfreich sein, sich gezielt nur die Datentypen der einzelnen Spalten anzeigen zu lassen.
Dafür stellt Pandas die Eigenschaft dtypes bereit.
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz.dtypes
Nach der Ausführung erhalten Sie eine Übersicht, in der jede Spalte ihres DataFrames einem bestimmten Datentyp zugeordnet wird.
Warum werden bei dtypes keine runden Klammern verwendet?
Ein wichtiger Unterschied zu info() besteht darin, dass dtypes keine Funktion, sondern eine Eigenschaft des DataFrames ist. Deshalb schreiben Sie: umsatz.dtypes und nicht umsatz.dtypes()
Dieser Unterschied wirkt für Einsteiger zunächst ungewohnt, ist aber in Pandas sehr üblich.
Das Ergebnis ist eine Pandas Series
Technisch gesehen ist das Ergebnis von dtypes eine sogenannte Pandas Series. Eine Series ist eine eindimensionale Datenstruktur in Pandas, die man sich ähnlich wie eine einzelne Spalte einer Tabelle vorstellen kann.
In diesem Fall enthält die Series:
- die Spaltennamen als Index
- den jeweiligen Datentyp als Wert
Damit sehen Sie sofort, welche Datentypen in Ihrem Datensatz vorkommen.
Warum Datentypen für die Datenanalyse wichtig sind
Datentypen bestimmen, welche Operationen mit einer Spalte möglich sind. Beispiele:
- Numerische Spalten können summiert oder gemittelt werden.
- Datumsfelder ermöglichen Zeitreihenanalysen.
- Textfelder können nach Kategorien ausgewertet werden.
Wenn ein Datentyp falsch erkannt wird, kann dies zu Problemen führen. Ein klassisches Beispiel ist eine Zahlenspalte, die versehentlich als Text importiert wurde. Dann funktionieren Berechnungen wie Mittelwerte oder Summen nicht korrekt.
Deshalb gehört die Überprüfung der Datentypen zu den ersten Schritten jeder Datenanalyse.
Statistische Kennzahlen berechnen – describe()
Im nächsten Schritt verschaffen Sie sich einen ersten statistischen Überblick über Ihre Daten. Eine der wichtigsten Funktionen in Pandas für diesen Zweck ist describe().
Mit dieser Funktion lassen sich zentrale statistische Kennzahlen eines Datensatzes automatisch berechnen.
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz.describe()
Nach der Ausführung erstellt Pandas eine statistische Zusammenfassung aller numerischen Spalten des DataFrames. Im Beispiel betrifft das die Spalten:
- Preis
- Verkaufsmenge
- Jahr
Damit erhalten Sie mit einem einzigen Befehl eine umfassende statistische Analyse Ihres Datensatzes. Das Ergebnis könnte beispielsweise so aussehen:
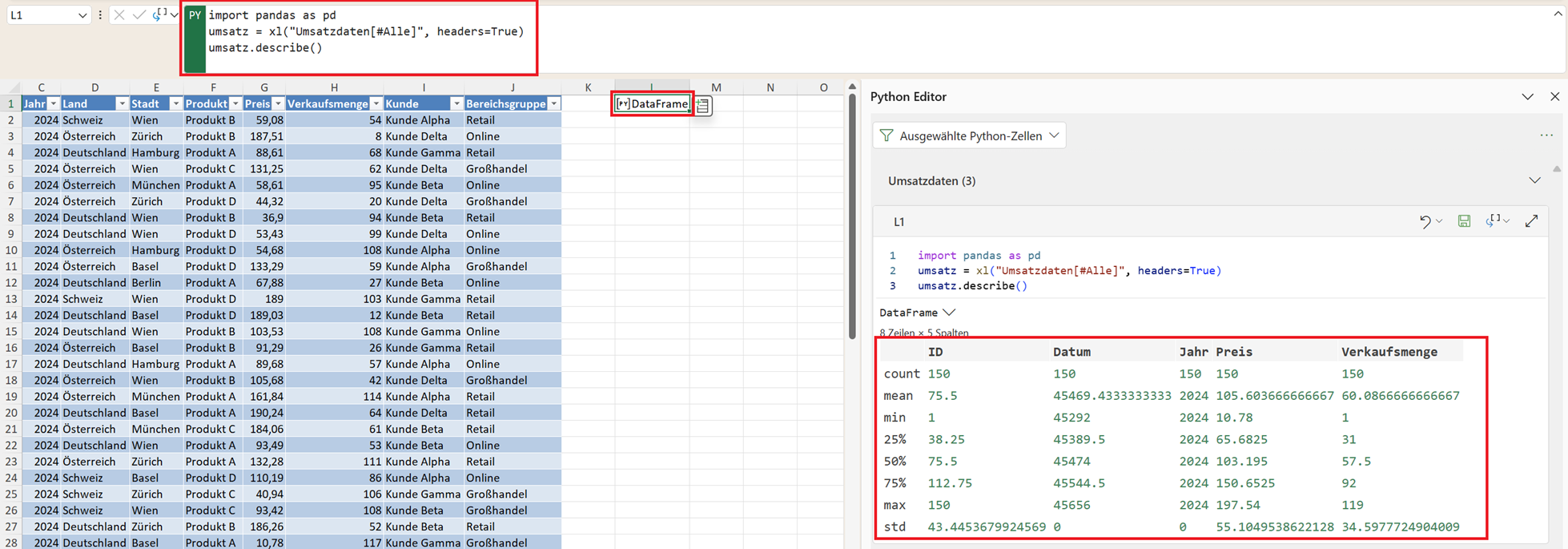
Bedeutung der einzelnen Kennzahlen von describe()
- count: Zeigt an, wie viele Werte in der jeweiligen Spalte vorhanden sind. Damit lassen sich fehlende Werte schnell erkennen.
- mean: Der Durchschnitt oder Mittelwert aller Werte in der Spalte.
- std: Die Standardabweichung misst, wie stark die Werte um den Durchschnitt streuen. Eine hohe Standardabweichung bedeutet, dass die Werte stark variieren.
- min: Der kleinste Wert im Datensatz.
- max: Der größte Wert im Datensatz.
- 25%: Das erste Quartil bedeutet, 25 % der Werte liegen unterhalb dieses Wertes.
- 50%: Der Median teilt die Daten in zwei gleich große Hälften. Er ist robuster gegenüber Ausreißern als der Durchschnitt.
- 75%: Das dritte Quartil bedeutet, 75 % der Werte liegen unterhalb dieses Wertes.
Die Kennzahlen helfen dabei, einen ersten Überblick über die Verteilung der Daten zu bekommen.
Warum die Funktion describe() so hilfreich ist
Viele dieser Kennzahlen sind auch in Excel verfügbar. Allerdings müssten sie dort meist einzeln berechnet werden. Mit describe() erhalten Sie dagegen eine komplette statistische Analyse auf einen Blick.
Gerade bei größeren Datensätzen spart das viel Zeit und liefert schnell wertvolle Erkenntnisse über die Datenstruktur.
Standardmäßig analysiert describe() nur numerische Spalten (int64, float64, datetime64). Text- und Kategoriespalten (object) werden ignoriert. Wenn Sie alle Spalten auf einmal sehen möchten – auch die kategorischen –, nutzen Sie den Parameter include="all":
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
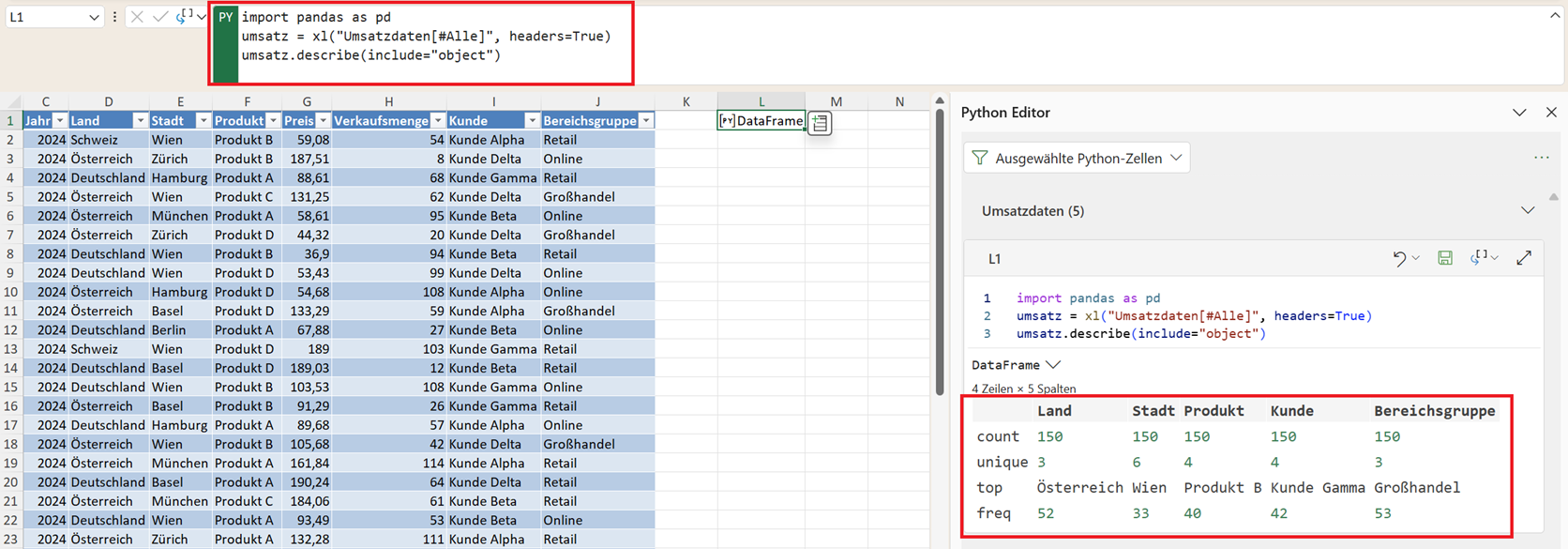
umsatz.describe(include="all")
Das Ergebnis enthält nun zusätzlich für Textspalten:
- unique: Anzahl unterschiedlicher Werte
- top: häufigster Wert
- freq: wie oft der häufigste Wert vorkommt
Alternativ können Sie auch nur die Kategorien anzeigen lassen:
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz.describe(include="object")
Das ist ein schneller Weg, um neben den Zahlen auch einen Überblick über die Textfelder zu bekommen – ohne extra value_counts() für jede Spalte aufrufen zu müssen.
Fehlende Werte schnell erkennen – isna().sum()
Fehlende Werte (leere Zellen, NaN in Python) gehören zu den häufigsten Problemen in Datensätzen – besonders wenn die Daten aus ERP-, CRM- oder anderen Quellen stammen.
In Excel können Sie mit ZÄHLENWENNS(), Suchen-Ersetzen oder bedingter Formatierung arbeiten, um fehlende Werte zu finden.
Pandas macht das mit einem einzigen Befehl extrem einfach:
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
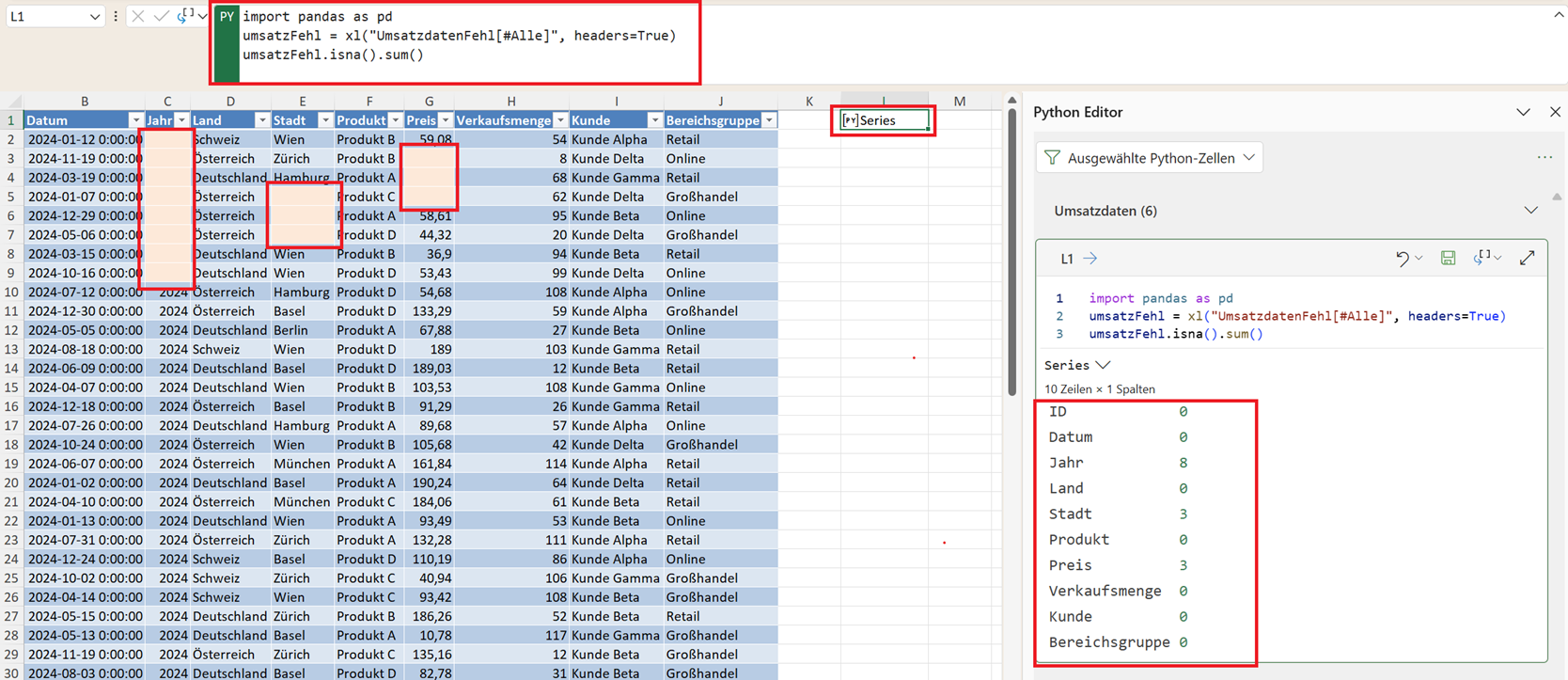
umsatz.isna().sum()
Alternativ funktioniert auch umsatz.isnull().sum() – beides ist identisch. Das Ergebnis ist eine Übersicht, wie viele Werte pro Spalte fehlen. Ein Beispiel könnte so aussehen:
Warum die Ausgabe von fehlenden Daten wichtig ist
Wenn viele Werte in einer wichtigen Spalte fehlen (zum Beispiel beim Preis oder beim Datum), sind spätere Berechnungen wie Mittelwerte oder Prognosen verzerrt oder gar nicht möglich. Deshalb gehört die Prüfung auf fehlende Werte zu den ersten Schritten jeder seriösen Datenanalyse.
Tipp für den nächsten Schritt: Wenn Sie die fehlenden Zeilen löschen möchten, dann verwenden Sie den folgenden Python-Code:
umsatzFehl.dropna()
Oder nur in bestimmten Spalten:
umsatzFehl.dropna(subset=["Preis", "Datum"])
Vergleich mit klassischen Excel-Formeln
Viele der Kennzahlen, die die Funktion describe() automatisch berechnet, lassen sich selbstverständlich auch direkt in Excel bestimmen. Allerdings erfordert dies meist mehrere unterschiedliche Formeln.
Nehmen Sie als Beispiel die Spalte Verkaufsmenge aus der Beispieldatei. Um die wichtigsten statistischen Kennzahlen in Excel zu berechnen, müssten Sie verschiedene Funktionen verwenden.
- Anzahl: ANZAHL2()
- Mittelwert: MITTELWERT()
- Standardabweichung: STABW.S()
- Minimum: MIN()
- Maximum: MAX()
Wenn Sie zusätzlich noch Quartile oder den Median berechnen möchten, kommen weitere Funktionen hinzu:
- Median: MEDIAN()
- Erstes Quartil: QUARTILE.INKL()
- Drittes Quartil: QUARTILE.INKL()
Damit benötigen Sie schnell eine ganze Reihe von Formeln, um eine vollständige statistische Übersicht zu erstellen. Mit Pandas genügt hingegen ein einziger Befehl: umsatz.describe()
Pandas berechnet damit automatisch alle wichtigen Kennzahlen für sämtliche numerische Spalten des DataFrames. Gerade bei größeren Datensätzen oder wiederkehrenden Analysen bietet diese Vorgehensweise einen großen Vorteil: Die komplette statistische Auswertung lässt sich mit nur einer einzigen Funktion durchführen.
Das spart Zeit und reduziert gleichzeitig die Gefahr von Fehlern, die bei vielen einzelnen Excel-Formeln entstehen können.
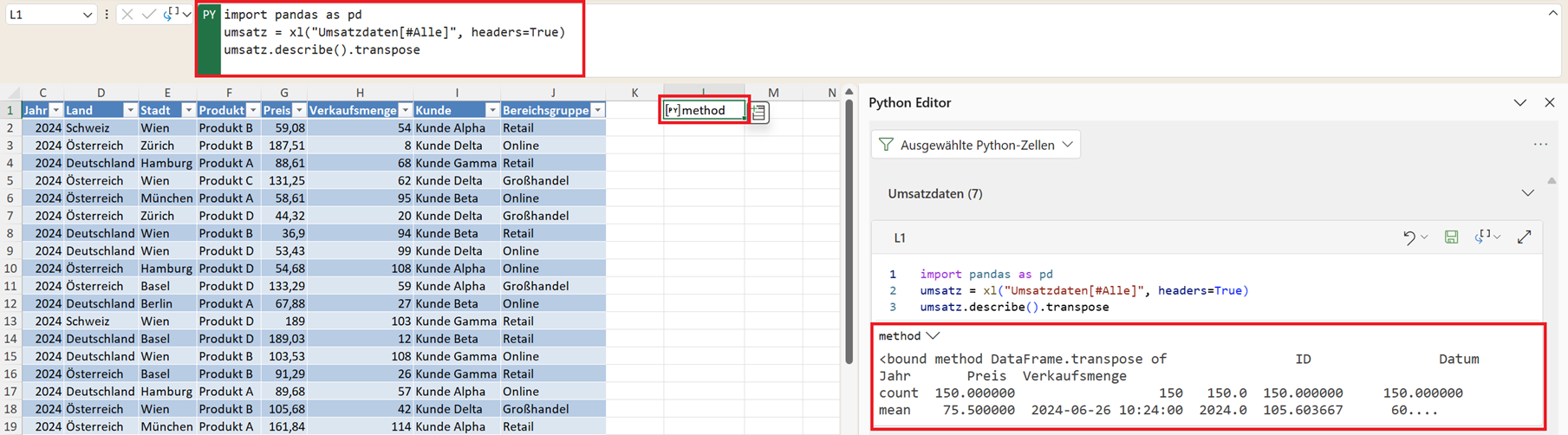
Analyse übersichtlicher darstellen – transpose()
Die Ausgabe der Funktion describe() liefert eine umfangreiche statistische Übersicht über die numerischen Spalten des DataFrames. Je nach Datensatz kann diese Darstellung jedoch etwas schwer zu lesen sein.
Der Grund liegt darin, dass die berechneten Kennzahlen standardmäßig untereinander in den Zeilen dargestellt werden, während die analysierten Variablen in den Spalten stehen. Bei vielen Variablen kann das schnell unübersichtlich werden.
Eine einfache Möglichkeit, die Darstellung zu verbessern, besteht darin, die Tabelle zu transponieren. Dabei werden Zeilen und Spalten vertauscht. In Pandas lässt sich das sehr einfach mit der Funktion transpose() umsetzen.
umsatz.describe().transpose()
Nach der Ausführung werden die Daten anders angeordnet:
- Die Variablen stehen nun in den Zeilen
- Die statistischen Kennzahlen erscheinen in den Spalten
Dadurch entsteht häufig eine deutlich übersichtlichere Darstellung.
Was bedeutet „transponieren“?
Der Begriff Transponieren stammt aus der Mathematik und bedeutet, dass eine Matrix gespiegelt wird. Dabei werden die Zeilen zu Spalten und die Spalten zu Zeilen.
Ein einfaches Beispiel:
A B
1 2
3 4
Nach der Transposition ergibt sich:
A 1 3
B 2 4
Das gleiche Prinzip wird auch bei der Analyse mit Pandas angewendet.
Wann ist eine transponierte Darstellung sinnvoll?
Die transponierte Darstellung ist besonders hilfreich, wenn:
- viele Variablen analysiert werden,
- man die Kennzahlen pro Variable schnell vergleichen möchte,
- die Ausgabe übersichtlicher strukturiert werden soll.
Gerade bei explorativen Analysen erleichtert eine gut strukturierte Darstellung das schnelle Verständnis der Daten.