Python in Excel für die DatenanalysePivot-Analysen und komplexe Auswertungen mit Pandas
Warum Pivot-Analysen wichtig sind
Pivot-Tabellen gehören zu den wichtigsten Werkzeugen in Excel. Typische Fragestellungen sind:
- Umsatz nach Land und Produkt
- Verkaufsmenge nach Stadt und Vertriebskanal
- Vergleich mehrerer Dimensionen gleichzeitig
Hier kommen Pivot-Analysen ins Spiel. Mit Pandas können Sie solche Auswertungen ebenfalls erstellen – oft sogar schneller und flexibler als in Excel.
Datensatz laden und vorbereiten
Die folgende Abbildung zeigt die Daten, die mit Pivot-Analysen ausgewertet werden sollen.
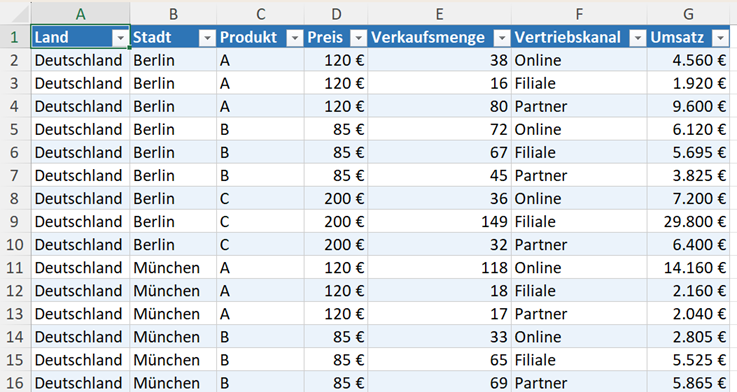
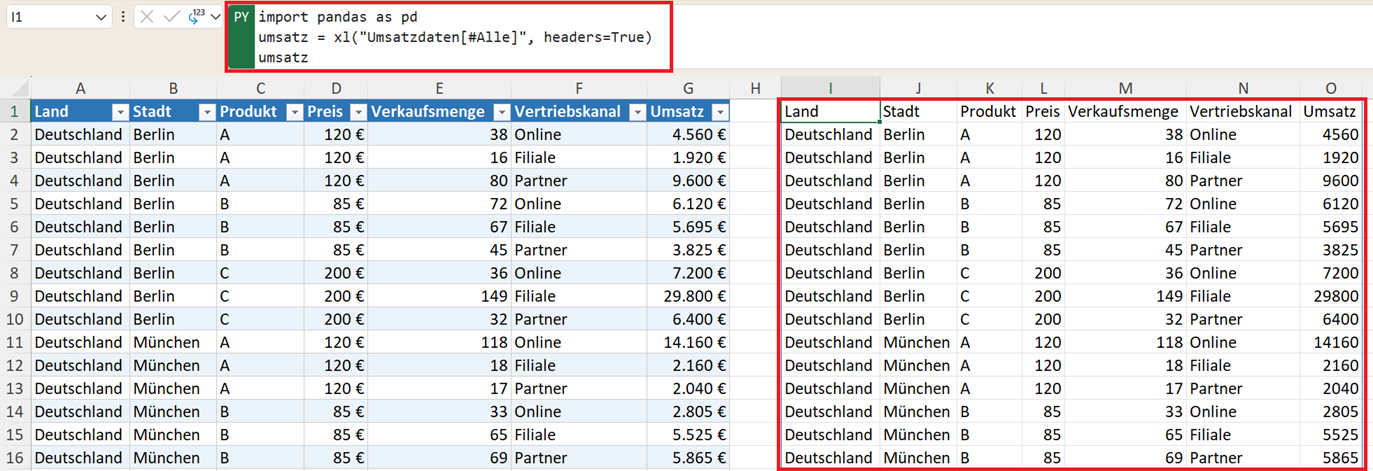
Die Daten liegen als intelligente Tabelle vor. Der Name der Tabelle ist Umsatzdaten. Mit den folgenden Python-Code können Sie die intelligente Tabelle in Python importieren:
import pandas as pd
umsatz = xl("Umsatzdaten_Filter[#Alle]", headers=True)
umsatz
Hinweis zur xl()-Funktion in Pandas
xl() ist eine spezielle Funktion von Python in Excel (Microsoft 365). Sie liest eine Excel-Tabelle direkt als DataFrame ein – das Äquivalent zu pd.read_excel(), aber noch enger in Excel integriert.
Falls Sie Pandas außerhalb von Excel nutzen, ersetzen Sie xl(…) einfach durch pd.read_excel("IhreDatei.xlsx", sheet_name="NameTabellenblatt").
Was ist eine Pivot-Analyse?
Eine Pivot-Tabelle besteht aus drei Elementen, die in Pandas direkt als Parameter angesprochen werden:
- Zeilen: index
- Spalten: columns
- Werte: values
- Zusammenfassen mit: aggfunc
Mit Pivot-Analysen fassen Sie Daten zusammen und vergleichen Kennzahlen (Werte).
Erste Pivot-Analyse erstellen
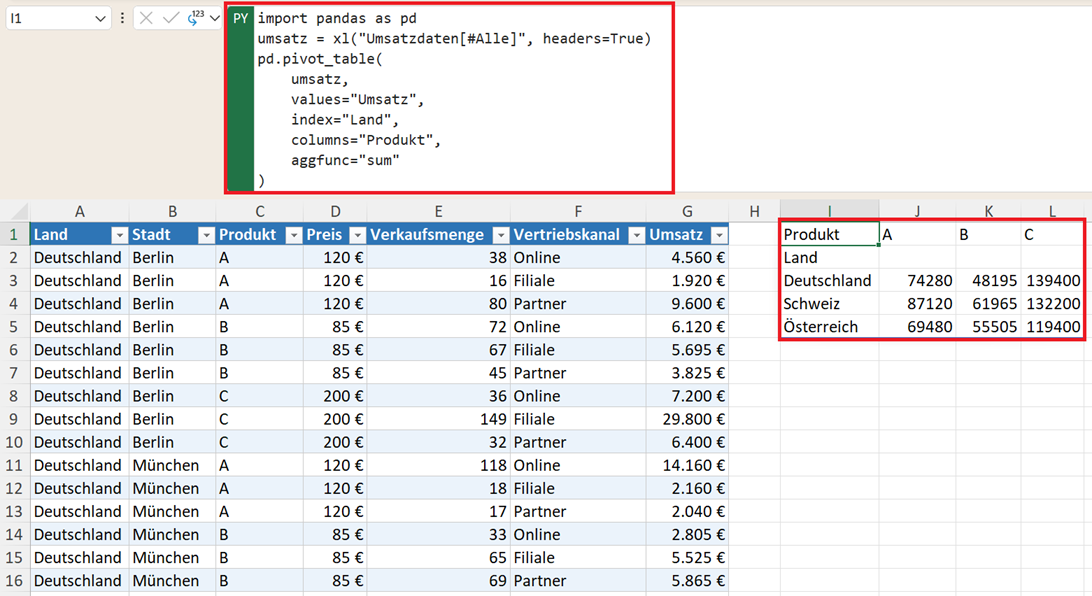
Zunächst wollen Sie eine einfache Pivot-Tabelle erstellen und damit den Umsatz nach Land und Produkt darstellen und auswerten. Der entsprechende Python-Code lautet:
pd.pivot_table(
umsatz,
values="Umsatz",
index="Land",
columns="Produkt",
aggfunc="sum"
)
Ergebnis: Damit sehen Sie sofort, welches Produkt in welchem Land stark ist und welche Unterschiede zwischen Regionen bestehen.
Tipp: Bei kategorialen Daten (zum Beispiel Produkt, Land) kann Pandas unnötige Kombinationen erzeugen. Mit observed=True vermeiden Sie leere Kombinationen und verbessern die Performance:
pd.pivot_table(
umsatz,
values="Umsatz",
index="Land",
columns="Produkt",
aggfunc="sum",
observed=True
)
Hinweis: pd.pivot() ist nur zum Umformen (reshape) ohne Aggregation – es funktioniert nur, wenn jede Kombination aus Index und Spalten genau einmal vorkommt. Für echte Analysen (wie in Excel Pivot-Tabellen) brauchen Sie immer pd.pivot_table().
Mehrere Kennzahlen in Pivot-Tabellen
Sie können auch mehrere Kennzahlen gleichzeitig berechnen und in der Pivot-Tabelle ausgeben. Zum Beispiel mit:
pd.pivot_table(
umsatz,
values=["Umsatz","Verkaufsmenge"],
index="Land",
columns="Produkt",
aggfunc="sum"
)
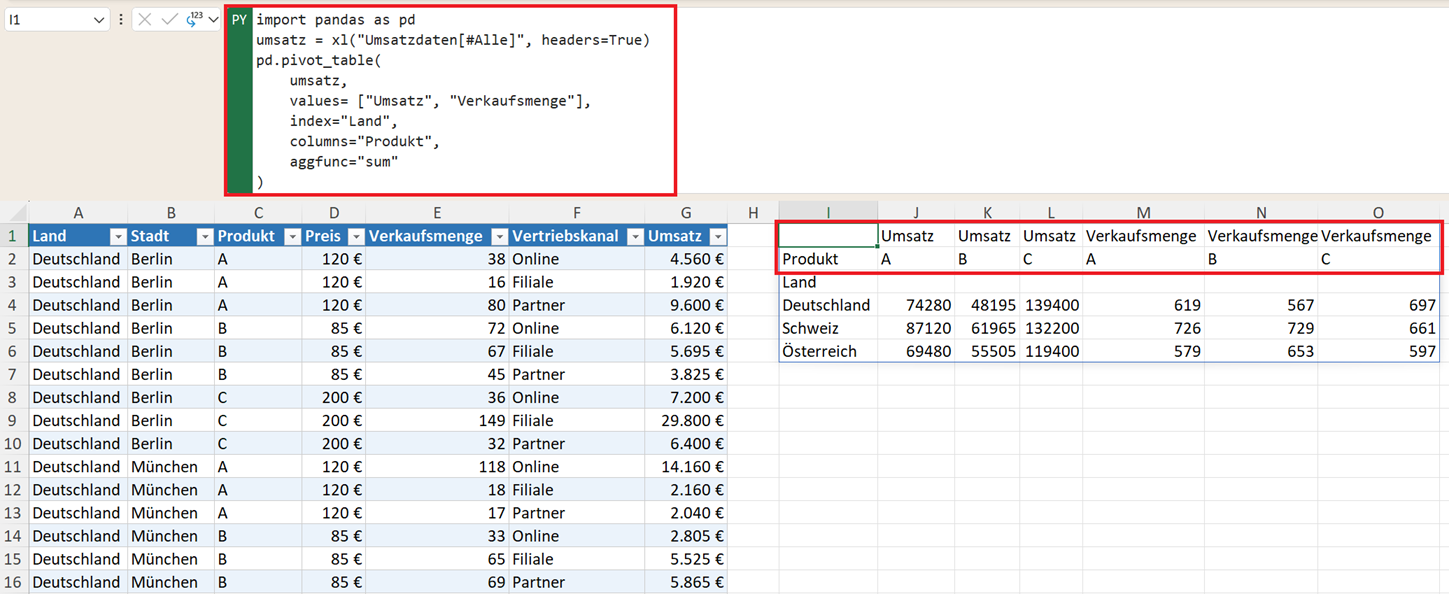
Ergebnis: Umsatz und Verkaufsmenge für jedes Produkt und Land – eine typische Business-Auswertung.
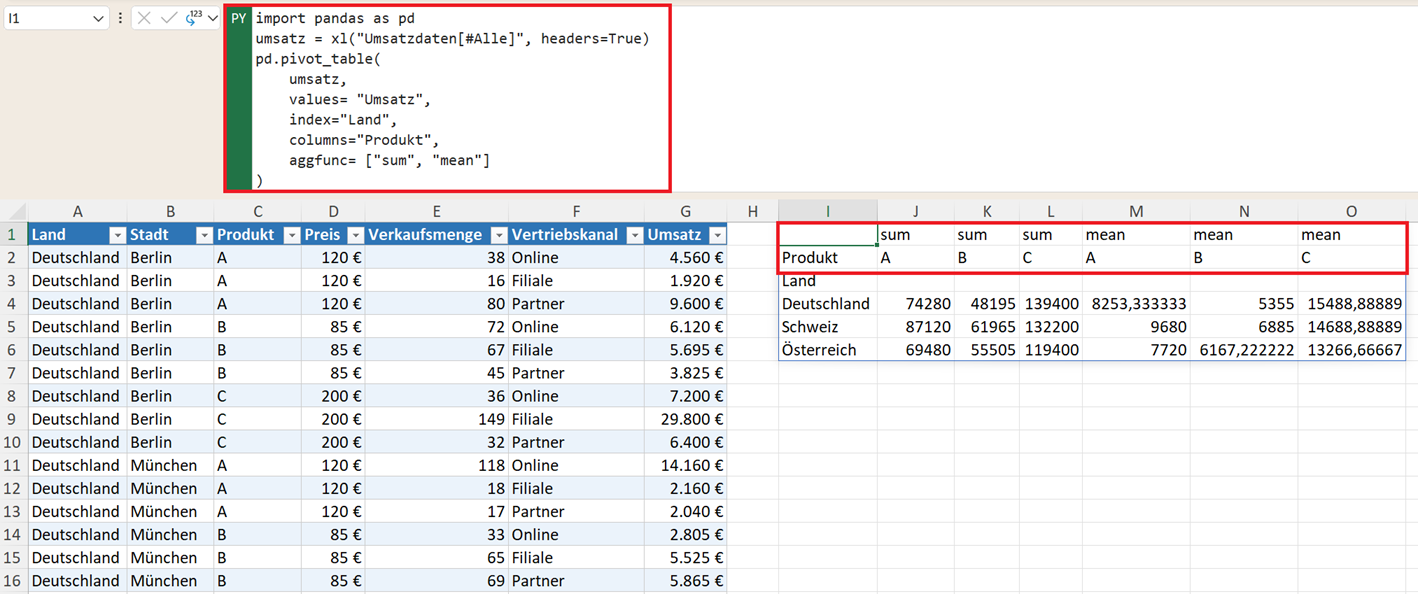
Entsprechend können auch mehrere Aggregationen (Kennzahlen) in der Pivot-Tabelle dargestellt werden. Das folgende Beispiel gibt für den Umsatz die Summe und den Mittelwert (Durchschnitt) pro Land und pro Produkt aus.
pd.pivot_table(
umsatz,
values="Umsatz",
index="Land",
columns="Produkt",
aggfunc=["sum", "mean"]
)
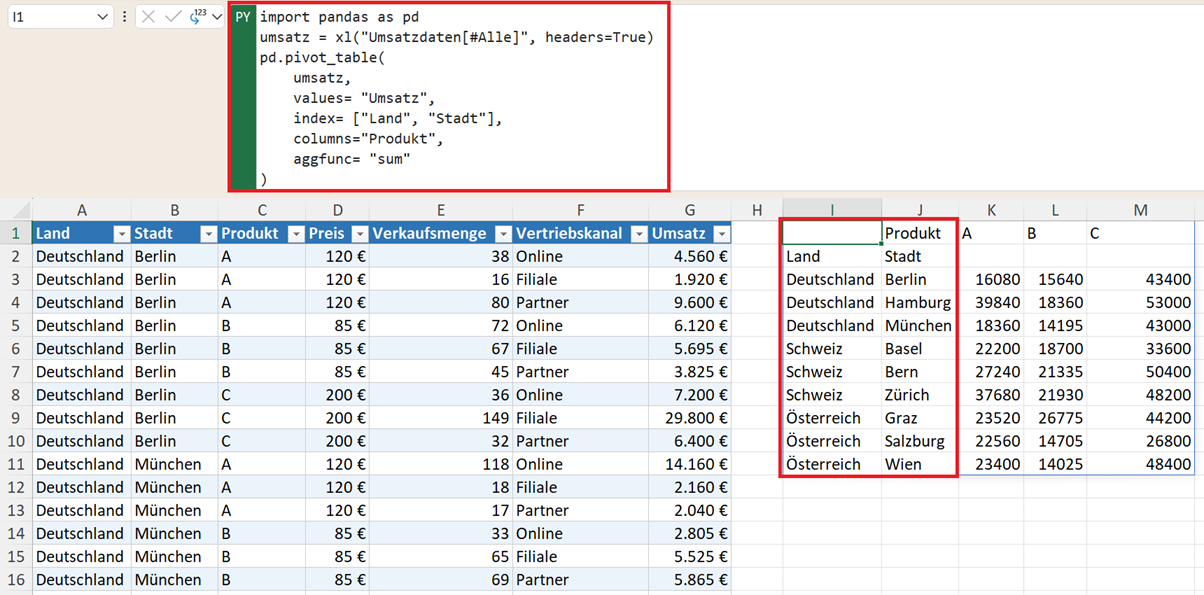
Pivot-Tabellen mit mehreren Ebenen
Die Pivot-Tabellen können in Pandas auch erweitert werden, indem mehrere Merkmale kombiniert werden. Sie führen mehrdimensionale Analysen (Hierarchien) durch, indem Sie beispielsweise zwei Merkmale als index definieren:
pd.pivot_table(
umsatz,
values="Umsatz",
index=["Land", "Stadt"],
columns="Produkt",
aggfunc="sum"
)
Die Analyse-Struktur folgt der Logik: Land → Stadt → Produkt.
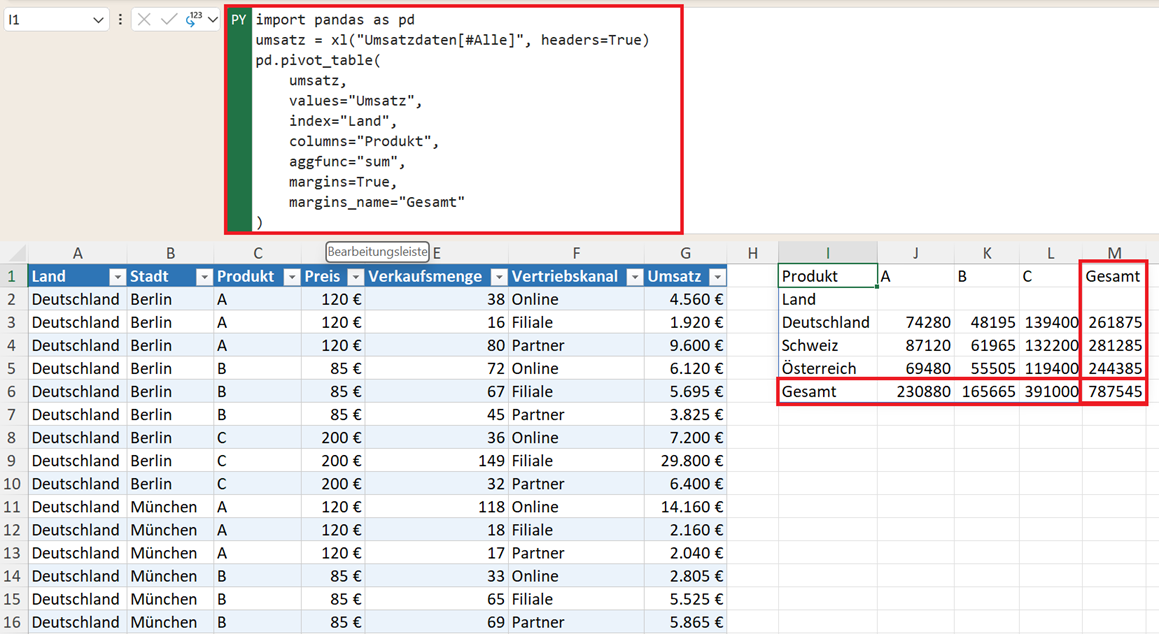
Gesamtsummen hinzufügen (Margins)
Mit dem folgenden Python-Code ergänzen Sie in Ihrer Pivot-Tabelle eine Spalte und eine Zeile mit der jeweiligen Gesamtsumme (Ergebnisspalte und Ergebniszeile):
pd.pivot_table(
umsatz,
values="Umsatz",
index="Land",
columns="Produkt",
aggfunc="sum",
margins=True,
margins_name="Gesamt"
)
Sie ergänzen dazu den Parameter margins=True und legen die Bezeichnung der Ergebnisspalte fest. Im Beispiel margins_Name="Gesamt".
Fehlende Werte in Pivot-Tabellen
Wenn im Datensatz einzelne Werte fehlen, kann es zu Lücken oder Fehleranzeigen in der Pivot-Tabelle kommen. Das vermeiden Sie mit der Angabe fill_value=0.
pd.pivot_table(
umsatz,
values="Umsatz",
index="Land",
columns="Produkt",
aggfunc="sum",
fill_value=0
)
Hinweis: fill_value=0 ersetzt nur Kombinationen ohne Daten. Echte NaN-Werte im Ursprungsdatensatz sollten vorher bereinigt werden.
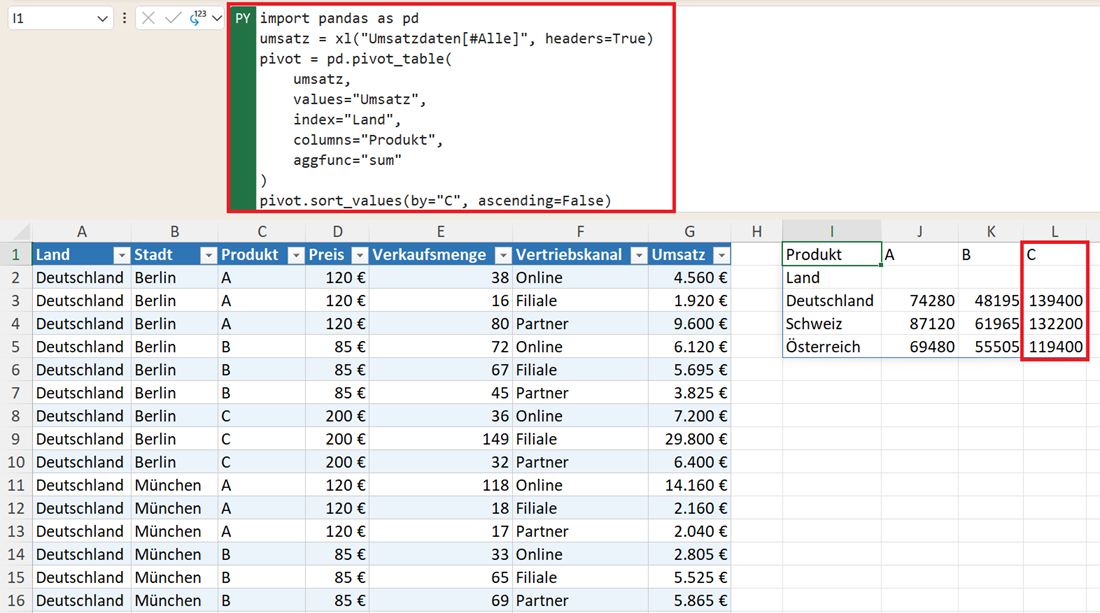
Pivot-Tabelle sortieren
Schließlich können Sie die Darstellung in Pivot-Tabellen auch sortieren. Beispielsweise können Sie die Umsatzwerte nach den Ergebnissen für Produkt C mit diesem Python-Code sortieren:
pivot = pd.pivot_table(
umsatz,
values="Umsatz",
index="Land",
columns="Produkt",
aggfunc="sum"
)
pivot.sort_values(by="C", ascending=False)
Weitere Varianten sind:
Nach der Gesamtsumme aller Produkte sortieren:
pivot.sort_values(by=pivot.sum(axis=1).name, ascending=False)
Eigene Summe berechnen und sortieren:
pivot.loc[pivot.sum(axis=1).sort_values(ascending=False).index]
Fazit
Pivot-Analysen gehören zu den mächtigsten Werkzeugen der Datenanalyse. Mit Pandas in Excel können Sie komplexe Analysen automatisieren, mehrere Kennzahlen flexibel kombinieren und professionelle Business-Reports erstellen.
Mit pd.pivot_table in Python kombinieren Sie die vertraute Pivot-Logik von Excel mit der Programmier-Power von Python – automatisiert, reproduzierbar und skalierbar.


