Python in Excel für die DatenanalyseZeitreihenanalyse mit Pandas, Umsatzverläufe und Trends
- Warum Zeitreihenanalyse wichtig ist
- Voraussetzungen für die Zeitreihenanalyse
- Monatliche Umsatzentwicklung
- Jahresvergleich – War dieses Jahr besser?
- Lücken im Zeitverlauf füllen (Resampling)
- Wochentags-Analyse
- Vergleich von Zeiträumen
- Gleitende Durchschnitte berechnen und Trends erkennen
- Wachstum und Veränderungen im Zeitverlauf ermitteln
- Kumulierter Umsatz (YTD) ermitteln
- Visualisierung mit Python als Diagramm
- Fazit
Warum Zeitreihenanalyse wichtig ist
Viele Fragen zum Unternehmenserfolg beziehen sich auf Zeitverläufe:
- Wie entwickelt sich der Umsatz über die Monate?
- Gibt es saisonale Schwankungen?
- Welche Trends sind erkennbar?
- War das aktuelle Jahr besser als das Vorjahr?
Damit kommt die Zeitreihenanalyse ins Spiel. Während Excel solche Analysen über Pivot-Tabellen oder Diagramme löst, bietet Pandas eine sehr flexible und leistungsfähige Alternative direkt in der Tabellenkalkulation.
Mit den folgenden Zeitreihenanalysen können Sie:
- Saisonale Effekte identifizieren
- Wachstum messen und Prognosen vorbereiten
- Datenlücken professionell handhaben
- Jahresvergleiche und Periodenauswertungen erstellen
Das ist besonders wichtig für Controlling, Vertrieb und Unternehmensplanung.
Voraussetzungen für die Zeitreihenanalyse
Bibliotheken importieren
Vorab müssen Sie sicherstellen, dass zwei Bibliotheken zur Verfügung stehen, damit alle folgenden Code-Beispiele funktionieren.
import pandas as pd
import matplotlib.pyplot as plt
Hinweis: Standardmäßig werden diese beiden Bibliotheken immer von Excel automatisch importiert.
Datensatz laden und vorbereiten
Anschließend laden Sie die Ausgangsdaten, die Sie analysieren wollen. Für die folgenden Beispiele ist dies eine Excel-Tabelle mit Umsatzdaten.
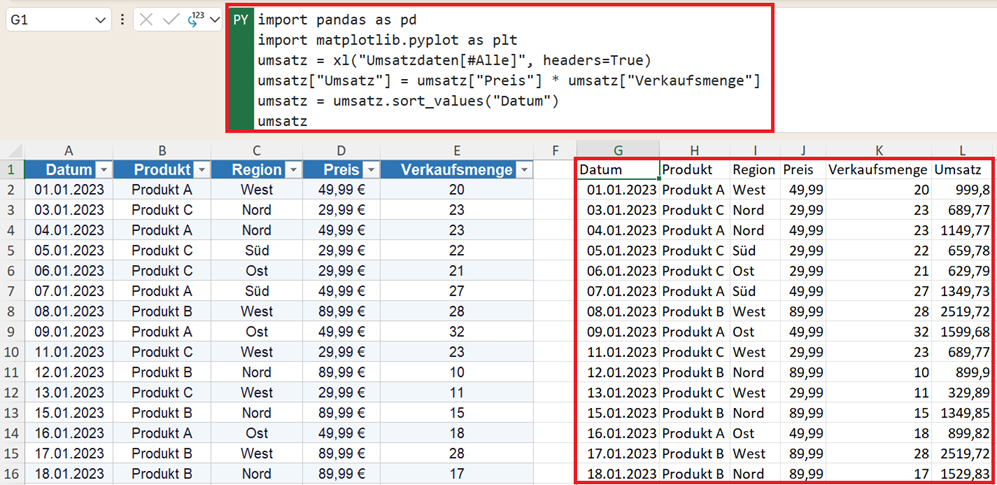
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
Wichtig: Sortieren Sie die Daten nach Datum. Das ist die Grundlage für Zeitreihenanalyse.
umsatz = umsatz.sort_values("Datum")
umsatz
Datumsfeld richtig vorbereiten
Für Zeitanalysen ist es wichtig, dass das Datum korrekt interpretiert wird.
umsatz["Datum"] = pd.to_datetime(umsatz["Datum"], errors='coerce')
Datensätze mit ungültigem Datum werden zu NaT. Diese filtern Sie anschließend aus.
umsatz = umsatz.dropna(subset=["Datum"])
Durch errors='coerce' wird verhindert, dass das ganze Skript wegen eines falsch formatierten Datums abstürzt. Anschließend wird das Datum als echtes Datumsformat erkannt. Viele Zeitfunktionen in Pandas arbeiten am zuverlässigsten, wenn das Datum als Index gesetzt ist.
Excel übergibt Datumsangaben manchmal als Integer (zum Beispiel 45000 statt "01.01.2023"). In diesem Fall hilft:
pd.to_datetime(umsatz["Datum"], origin="1899-12-30", unit="D")
Hinweis: Diese Aufbereitungen sind für unsere Datenquelle im Beispiel nicht notwendig. Aus Gründen der Übersichtlichkeit lassen wir diese Aufbereitungen im Python-Code weg.
Monatliche Umsatzentwicklung
Nun wollen Sie den Umsatz pro Monat aus Ihrer Verkaufsliste ermitteln. Dazu werden alle Umsätze nach Monaten gruppiert.
umsatz["Monat"] = umsatz["Datum"].dt.to_period("M").dt.to_timestamp()
monatsumsatz = umsatz.groupby("Monat")["Umsatz"].sum().sort_index()
Hinweis: In neueren Pandas-Versionen wurden "M" und "Q" durch "ME" bzw. "QE" ersetzt – bei einer Warnung einfach anpassen.
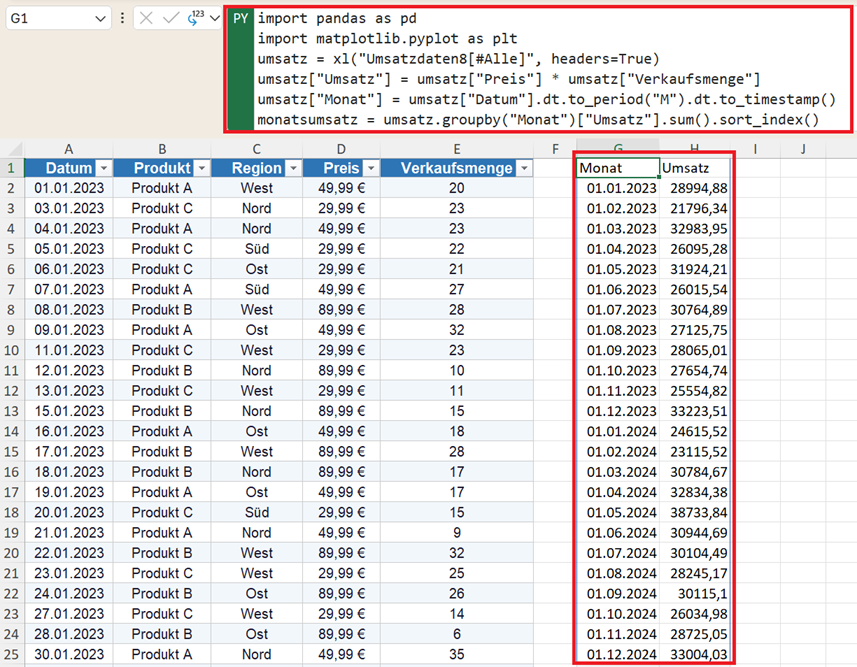
Warum dt.to_timestamp()? Damit die Daten optimal für Excel-Diagramme sortierbar bleiben, wird die Periode „Monat“ zurück in einen Zeitstempel (Angabe des 1. eines Monats) verwandelt.
Excel kann mit dem Pandas-eigenen Period-Objekt nichts anfangen. Ein Timestamp wird dagegen als normales Excel-Datum erkannt und kann in Diagrammen oder Formeln verwendet werden. Damit erkennen Sie:
- Umsatzverlauf über die Zeit
- Starke und schwache Monate
Tipps:
- Wenn Sie die Ergebnisse in Excel weiterverarbeiten möchten, dann nutzen Sie am Ende des Python-Codes .reset_index(), damit die Datumsspalten als normale Excel-Spalten ausgegeben werden.
- Python-Zellen in Excel werden nicht immer automatisch wie klassische Formeln neu berechnet. Aktualisieren Sie diese bei Bedarf manuell mit F9.
Jahresvergleich – War dieses Jahr besser?
Eine der häufigsten Praxisfragen: Wie hat sich der Umsatz im Jahresvergleich entwickelt?
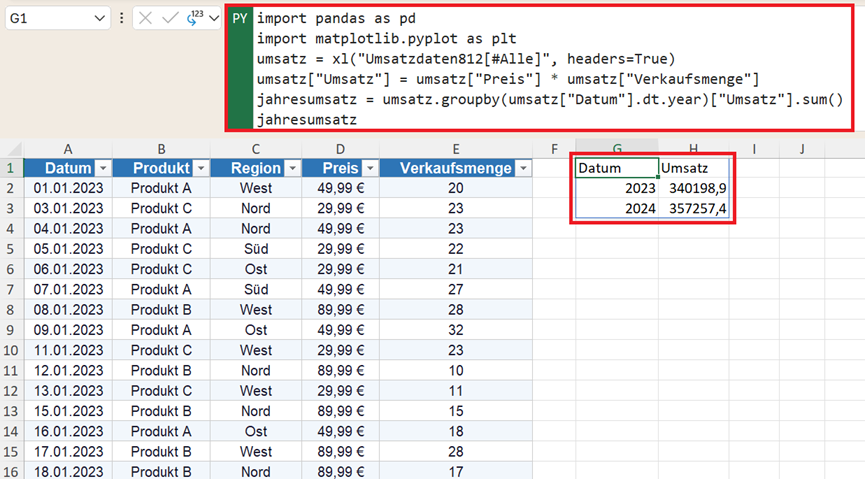
jahresumsatz = umsatz.groupby(umsatz["Datum"].dt.year)["Umsatz"].sum()
jahresumsatz
Das Ergebnis zeigt den Gesamtumsatz pro Kalenderjahr – ideal für Jahresberichte oder als Grundlage für Wachstumsraten.
Lücken im Zeitverlauf füllen (Resampling)
In der Praxis gibt es oft Tage ohne Verkäufe. Damit Trends korrekt berechnet werden, können Sie diese Lücken mit Nullwerten füllen. Dazu müssen Sie:
Datum als Index setzen (notwendig für resample).
umsatz_daily = umsatz.set_index("Datum")
Auf Tagesbasis aggregieren und fehlende Tage mit 0 füllen.
umsatz_daily = umsatz_daily.resample("D")["Umsatz"].sum().fillna(0)
umsatz_daily
Statt "D" können Sie auch "W" (Wochen), "ME" (Monate), "QE" (Quartale) oder "YE" (Jahre) verwenden.
fillna(0) ist ideal für fehlende Umsatzdaten (kein Umsatz = 0). Bei echten Fehlwerten (zum Beispiel: keine Messung durchgeführt) kann es besser sein, die Lücken zu interpolieren mit
umsatz.interpolate()
oder einen vorherigen Wert zu übernehmen:
.ffill()
Wochentags-Analyse
Besonders für E-Commerce oder Retail ist interessant: An welchen Wochentagen wird am meisten verkauft? Dazu ermitteln Sie die Umsätze für die einzelnen Wochentage mit der Angabe von dt.day_name:
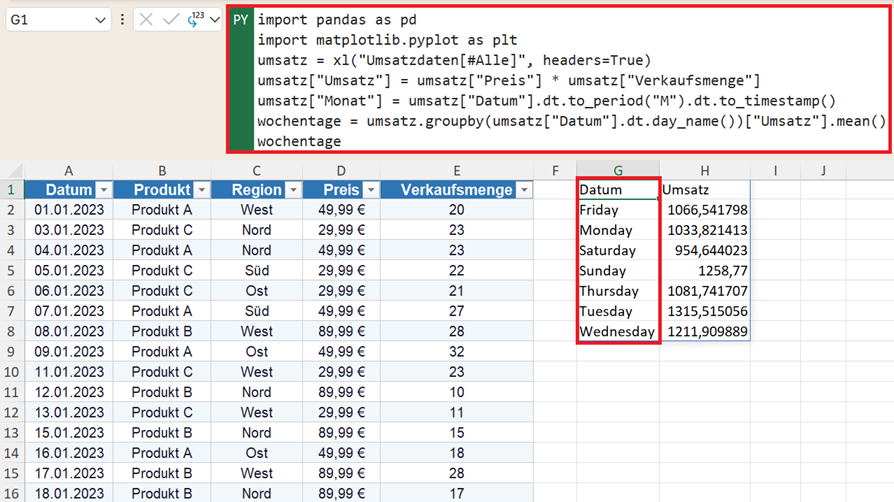
wochentage = umsatz.groupby(umsatz["Datum"].dt.day_name())["Umsatz"].mean()
wochentage
So erkennen Sie auf einen Blick, ob der Umsatz etwa am Montag einbricht oder ob das Wochenende besonders stark ist.
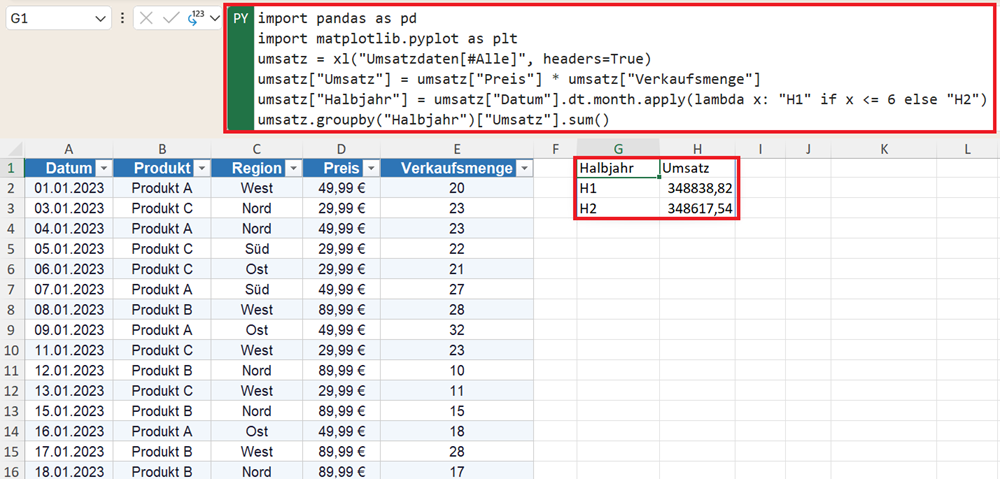
Vergleich von Zeiträumen
Schließlich wollen Sie die Umsätze für zwei Perioden direkt miteinander vergleichen. Mit diesem Python-Code ermitteln Sie den jeweiligen Umsatz im ersten und im zweiten Halbjahr.
umsatz["Halbjahr"] = umsatz["Datum"].dt.month.apply(lambda x: "H1" if x <= 6 else "H2")
umsatz.groupby("Halbjahr")["Umsatz"].sum()
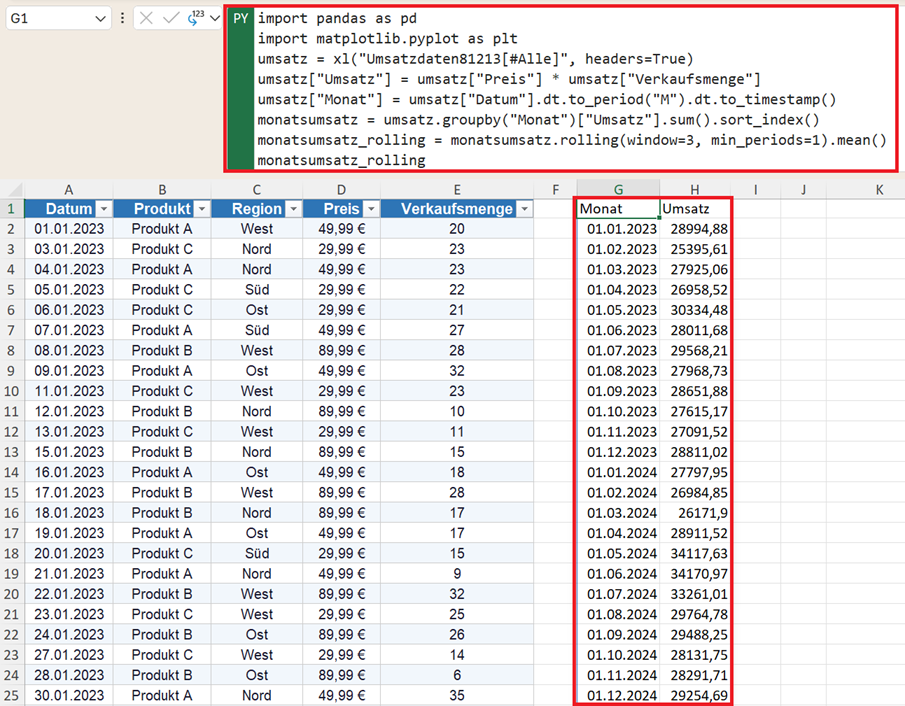
Gleitende Durchschnitte berechnen und Trends erkennen
Ein wichtiges Werkzeug der Zeitreihenanalyse ist der gleitende Durchschnitt, um starke Schwankungen zu entfernen und Trends besser sichtbar zu machen.
Beispiel: 3-Monats-Durchschnitt
monatsumsatz_rolling = monatsumsatz.rolling(window=3, min_periods=1).mean()
monatsumsatz_rolling
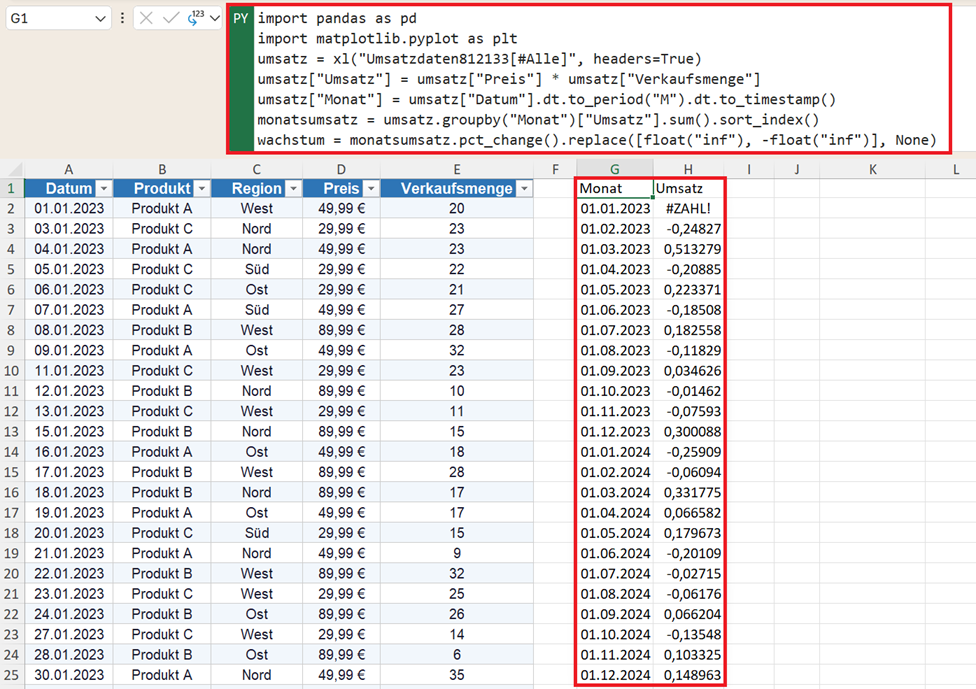
Wachstum und Veränderungen im Zeitverlauf ermitteln
Im nächsten Schritt wollen Sie wissen: Wie stark wächst der Umsatz und wo stehen wir im aktuellen Jahr insgesamt?
Dazu berechnen Sie die prozentuale Veränderung zum Vormonat.
wachstum = monatsumsatz.pct_change().replace([float("inf"), -float("inf")], None)
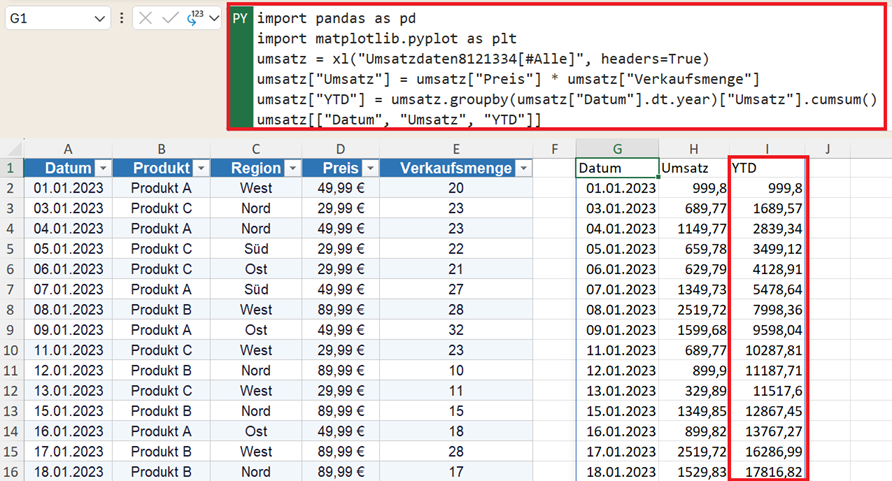
Kumulierter Umsatz (YTD) ermitteln
Den kumulierten Umsatz (Year-to-Date) berechnen Sie mit:
umsatz = umsatz.sort_values("Datum")
umsatz["YTD"] = umsatz.groupby(umsatz["Datum"].dt.year)["Umsatz"].cumsum()
umsatz[["Datum", "Umsatz", "YTD"]]
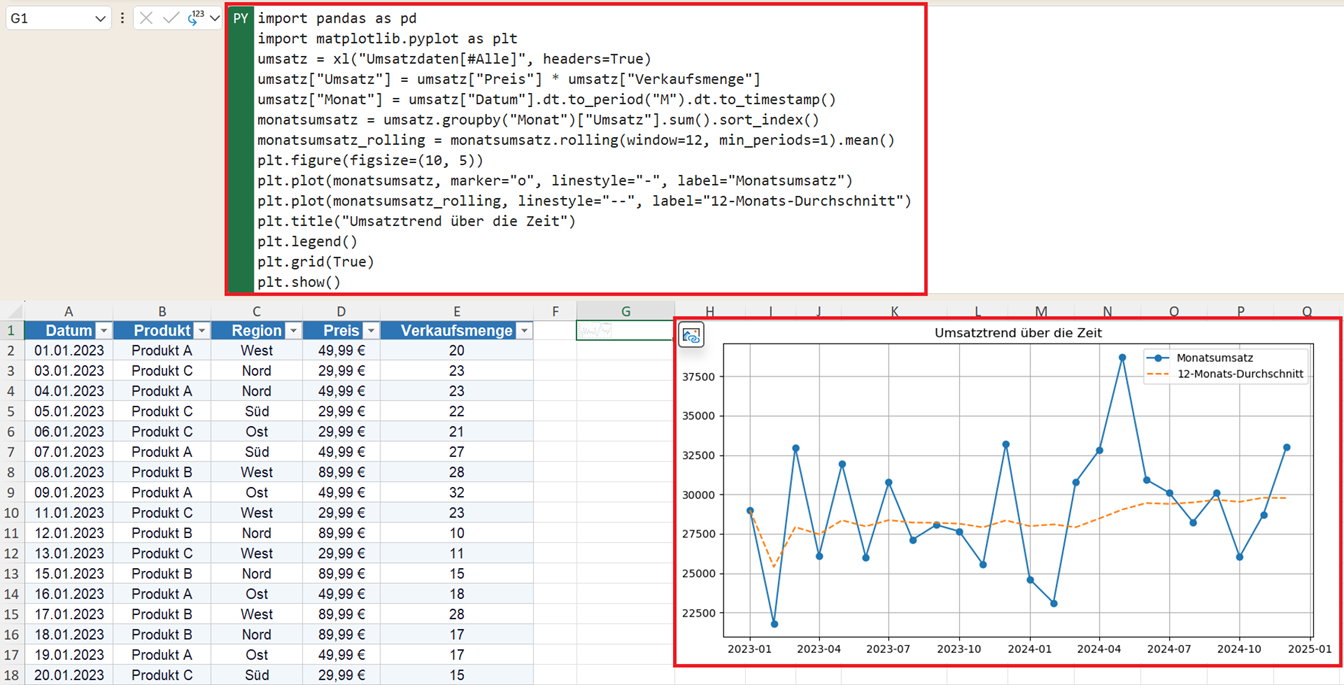
Visualisierung mit Python als Diagramm
Der größte Vorteil von Python in Excel ist die integrierte Grafikbibliothek. So können Sie den Trend sofort visualisieren. Mit dem folgenden Python-Code stellen Sie den Umsatz pro Monat sowie den Umsatztrend als gleitenden Durchschnitt aus 12 Monaten dar.
Zunächst werden der Monatsumsatz sowie der gleitende Umsatz für 12 Monate berechnet:
import pandas as pd
import matplotlib.pyplot as plt
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
umsatz["Monat"] = umsatz["Datum"].dt.to_period("M").dt.to_timestamp()
monatsumsatz = umsatz.groupby("Monat")["Umsatz"].sum().sort_index()
monatsumsatz_rolling = monatsumsatz.rolling(window=12, min_periods=1).mean()
Dann werden diese Liste der Monatsumsätze sowie der 12-Monats-Trend in ein Diagramm überführt:
plt.figure(figsize=(10, 5))
plt.plot(monatsumsatz, marker="o", linestyle="-", label="Monatsumsatz")
plt.plot(monatsumsatz_rolling, linestyle="--", label="3-Monats-Durchschnitt")
plt.title("Umsatztrend über die Zeit")
plt.legend()
plt.grid(True)
plt.show()
Die Grafik wird direkt im Excel-Arbeitsblatt angezeigt. Ein separates Fenster wird in der Regel nicht geöffnet.
Fazit
Die Zeitreihenanalyse ist ein zentraler Bestandteil moderner Datenanalysen. Mit Pandas in Excel können Sie Daten nach Zeit aggregieren, Trends visualisieren und Veränderungen präzise messen – alles innerhalb deiner gewohnten Arbeitsumgebung.
Wer über einfache gleitende Durchschnitte hinausgehen möchte, kann mit der Bibliothek statsmodels auch saisonale Zerlegungen, Trendkomponenten und Konfidenzintervalle für Prognosen berechnen.


