Python in Excel für die DatenanalyseHilfreiche Funktionen in Python für die explorative Beschreibung eines Datensatzes
- Einzelne Spalten einer Datentabelle analysieren
- Häufigkeitsverteilung von Kategorien – value_counts()
- Mehrere Spalten gleichzeitig analysieren
- Spaltennamen anzeigen – columns
- Weitere grundlegende Informationen über einen DataFrame
- Werte eines DataFrames anzeigen – values
- Struktur eines DataFrames anzeigen – shape
- Anzahl von Zeilen und Spalten bestimmen – len()
- Zufällige Stichproben aus einem Datensatz ziehen – sample()
Einzelne Spalten einer Datentabelle analysieren
In vielen Fällen interessiert man sich bei der Datenanalyse nicht für den gesamten Datensatz, sondern nur für bestimmte Variablen. Beispielsweise möchte man vielleicht nur untersuchen, wie sich die Verkaufsmenge oder der Preis verteilt.
Mit Pandas lassen sich einzelne Spalten eines DataFrames sehr einfach auswählen und anschließend analysieren.
Angenommen, Sie möchten nur die Spalte Verkaufsmenge statistisch untersuchen. Dann können Sie diese Spalte gezielt auswählen und anschließend die Funktion describe() darauf anwenden.
Es gibt zwei Möglichkeiten, eine Spalte auszuwählen.
1. Punktnotation
Die gewählte Spalte wird zwischen zwei Punkte (.) gesetzt:
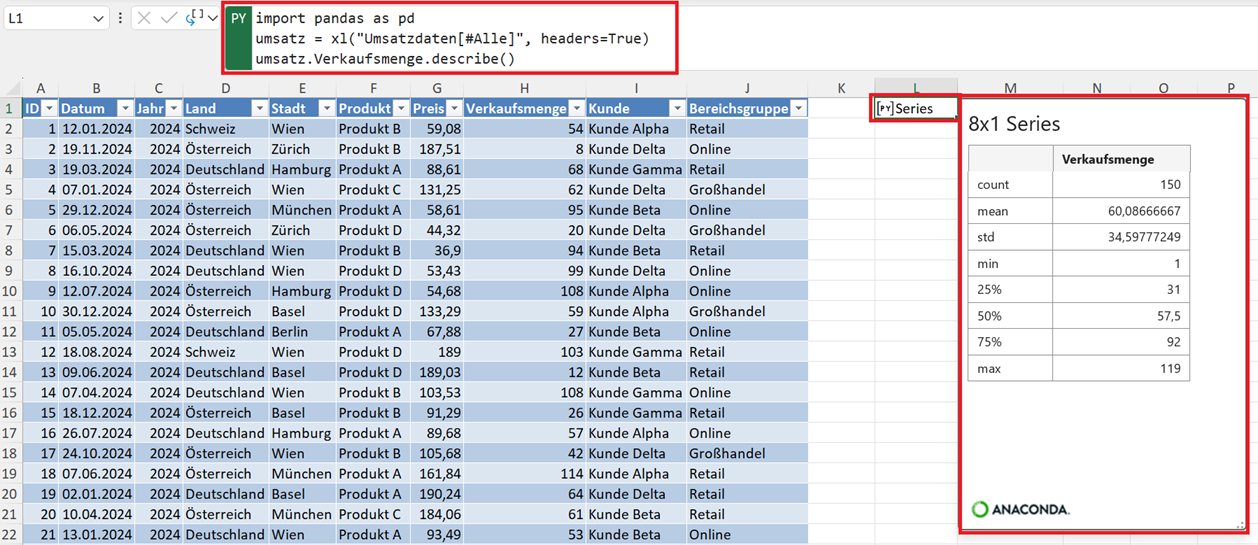
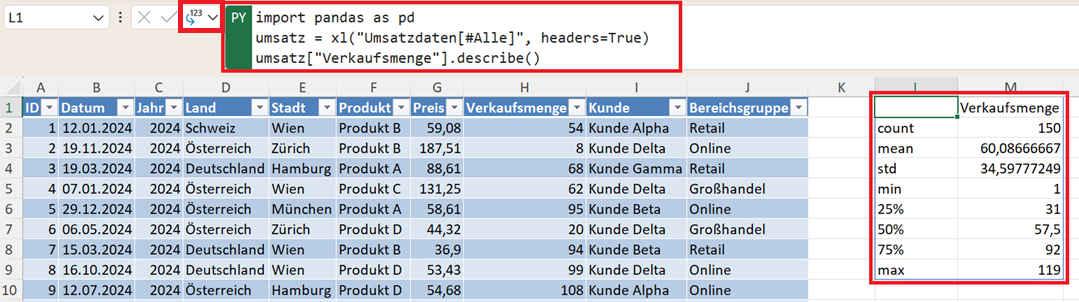
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz.Verkaufsmenge.describe()
Hier greifen Sie direkt auf die Spalte zu.
2. Eckklammernotation
Sie können die gewünschte Spalte auch in Eckklammern ([]) mit Anführungszeichen ("") setzen.
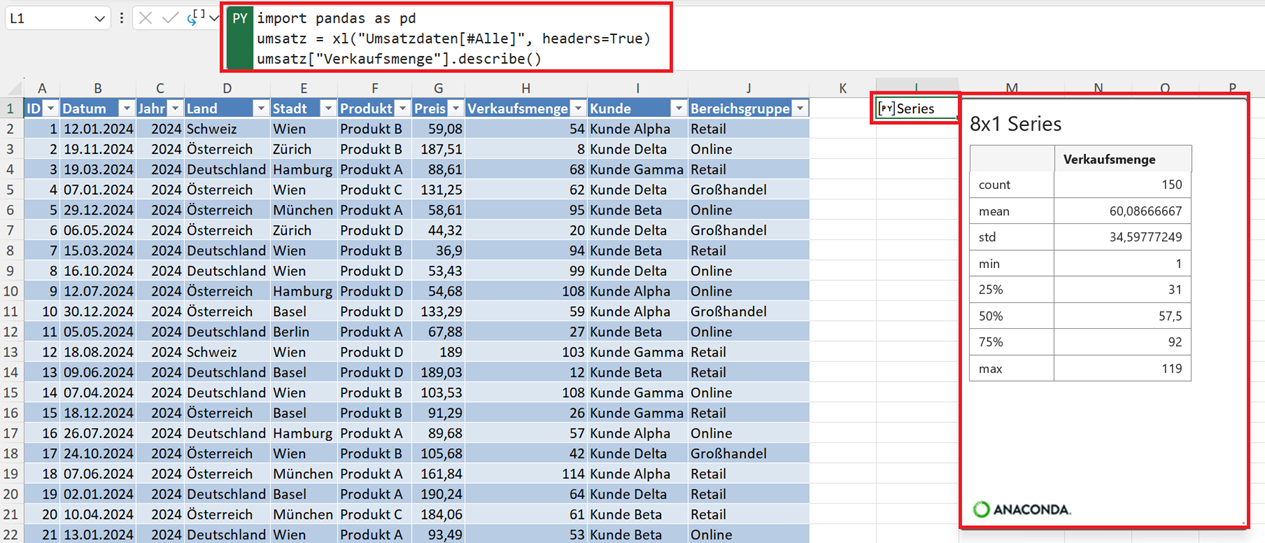
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz["Verkaufsmenge"].describe()
Diese Schreibweise ist besonders robust und wird häufig in professionellen Anwendungen verwendet.
Unterschied zwischen beiden Varianten
Beide Methoden liefern das gleiche Ergebnis. Dennoch gibt es kleine Unterschiede.
Die Punktnotation funktioniert nur, wenn:
- der Spaltenname keine Leerzeichen enthält und
- der Spaltenname keine Sonderzeichen enthält.
Die Eckklammernotation funktioniert hingegen immer, auch wenn Spaltennamen beispielsweise Leerzeichen enthalten. Deshalb wird sie häufig als allgemeinere und sicherere Variante empfohlen.
Tipp: Ausgabe auf dem Excel-Arbeitsblatt
Diese Python-Analyse können Sie sich auch in das Excel-Blatt ausgeben lassen, um die Daten direkt mit Formeln weiterverarbeiten zu können.
Ändern Sie hierzu einfach die Ausgabe, indem Sie mit der Maus auf das Ausgabesymbol links neben PY in der Bearbeitungsleiste klicken. Wählen Sie dann unter Python-Ausgabe den Eintrag Excel-Wert aus.
Ergebnis der Spaltenanalyse
Das Ergebnis der Analyse einer einzelnen Spalte ist eine statistische Übersicht über genau diese Variable. Damit können Sie beispielsweise schnell erkennen:
- wie hoch die durchschnittliche Verkaufsmenge ist,
- welche minimale und maximale Verkaufsmenge vorkommt oder
- wie stark die Werte streuen.
Gerade bei explorativen Analysen ist es häufig sinnvoll, einzelne Variablen gezielt zu untersuchen, bevor man komplexere Auswertungen erstellt.
Häufigkeitsverteilung von Kategorien – value_counts()
Die Funktion describe() ist hilfreich für Zahlen sowie bei Text- oder Kategoriespalten wie Land, Produkt, Kunde oder Bereichsgruppe. Sie liefert aber nur einige Informationen – wie beispielsweise Anzahl eindeutiger Werte, häufigster Wert etc.
Um mehr über den Datensatz oder eine Variable zu erfahren, kann describe() ergänzt werden um die Methode value_counts(). Sie zählt, wie oft jeder Wert vorkommt.
Beispiel für die Spalte „Land“:
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz["Land"].value_counts()

Sie sehen sofort: Die meisten Umsätze kommen aus Österreich – das ist eine wichtige Erkenntnis für regionale Analysen.
Noch praktischer sind relative Anteile in Prozent:
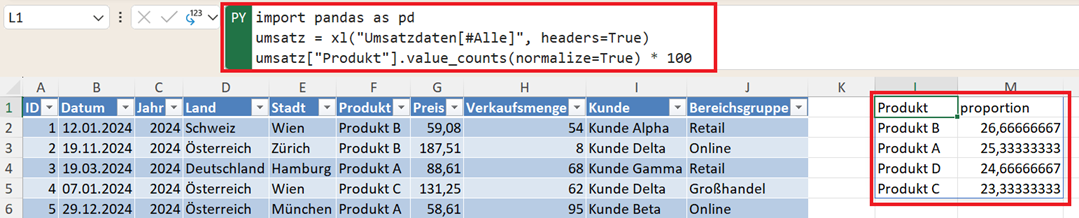
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz["Produkt"].value_counts(normalize=True) * 100
Mit normalize=True werden keine absoluten Zahlen, sondern Anteile berechnet. Durch die Multiplikation mit 100 erhalten Sie die Prozentzahl als Dezimalwert dargestellt.
Vergleich zu Excel
In Excel müssten Sie eine Pivot-Tabelle erstellen oder ZÄHLENWENNS() über alle einzigartigen Werte laufen lassen – das dauert deutlich länger. Mit value_counts() haben Sie die Top-Kategorien in Sekunden.
Mehrere Spalten gleichzeitig analysieren
In vielen Fällen möchten Sie nicht nur eine einzelne Variable analysieren, sondern mehrere zusammengehörige Variablen gleichzeitig untersuchen. Im Beispiel könnten beispielsweise die Spalten Preis und Verkaufsmenge besonders interessant sein, da sie beide numerische Werte enthalten und häufig gemeinsam analysiert werden.
Mit Pandas lassen sich mehrere Spalten eines DataFrames sehr einfach auswählen, indem man ihre Namen in einer Liste angibt.
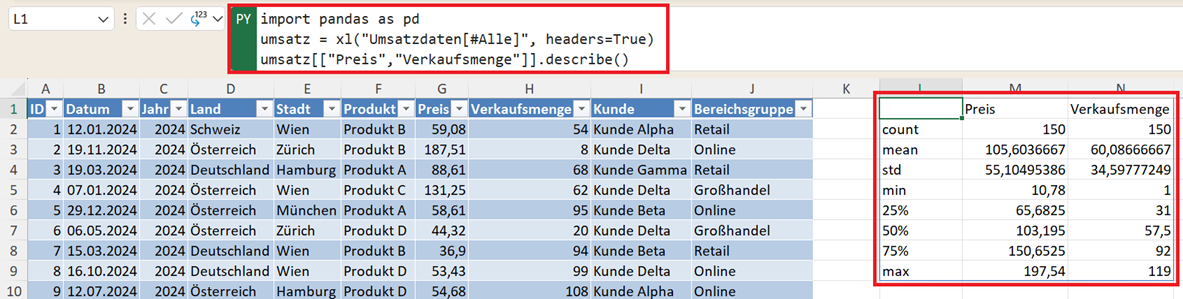
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz[["Preis","Verkaufsmenge"]].describe()
Dabei passiert Folgendes:
- Die doppelten Eckklammern ([[]]) wählen mehrere Spalten aus dem DataFrame aus.
- Pandas erstellt daraus einen neuen DataFrame, der nur diese beiden Spalten enthält.
- Anschließend wird auf diesen DataFrame die Funktion describe() angewendet.
Das Ergebnis ist eine statistische Analyse ausschließlich für die ausgewählten Variablen.
Warum werden hier doppelte Eckklammern verwendet?
Der Grund für die doppelte Verwendung der Eckklammern ist:
- Eine einzelne Spalte wird mit einer einzelnen Eckklammer ausgewählt.
- Mehrere Spalten müssen als Liste von Spaltennamen übergeben werden.
Beispiel:
- Eine Spalte: umsatz["Preis"]
- Mehrere Spalten: umsatz[["Preis","Verkaufsmenge"]]
Die innere Klammer enthält also eine Liste der gewünschten Spalten.
Vorteil dieser Methode
Diese Vorgehensweise ist besonders nützlich, wenn ein Datensatz viele Variablen enthält. Statt alle Spalten gleichzeitig auszuwerten, können Sie gezielt nur diejenigen analysieren, die für Ihre Fragestellung relevant sind.
Im Beispiel erhalten Sie so schnell einen Überblick über:
- die durchschnittlichen Preise
- die durchschnittliche Verkaufsmenge
- die Streuung der Werte
- die minimalen und maximalen Werte
Damit können Sie bereits erste Zusammenhänge in den Daten erkennen.
Spaltennamen anzeigen – columns
Bei der Arbeit mit Daten ist es häufig hilfreich, sich zunächst einen Überblick über alle vorhandenen Spalten eines DataFrames zu verschaffen. Gerade bei größeren Datensätzen kann es vorkommen, dass man den genauen Namen einer Spalte nicht kennt oder prüfen möchte, welche Variablen überhaupt zur Verfügung stehen.
In Pandas lässt sich diese Information sehr einfach anzeigen. Dafür verwendet man die Eigenschaft columns.
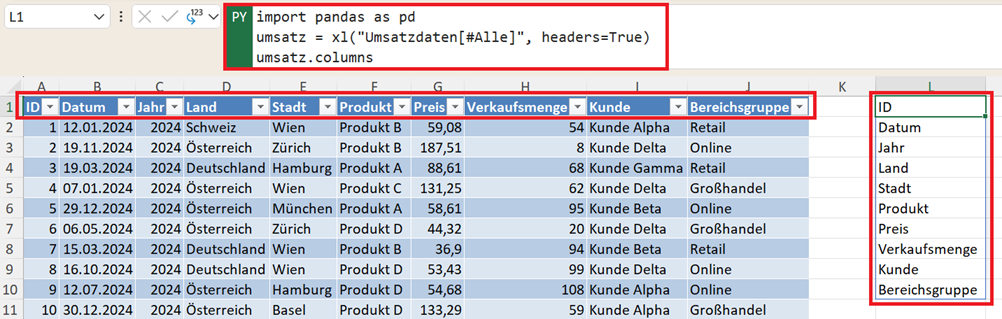
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz.columns
Nach der Ausführung gibt Pandas eine Liste aller Spaltennamen des DataFrames zurück.
Warum diese Übersicht hilfreich ist
Gerade bei größeren Datensätzen ist es nicht immer sofort ersichtlich, welche Variablen enthalten sind. Mit columns können Sie schnell überprüfen:
- welche Spalten verfügbar sind,
- wie die Spalten genau geschrieben werden und
- ob ein Datensatz möglicherweise zusätzliche Variablen enthält.
Das ist besonders wichtig, weil Pandas beim Zugriff auf Spalten exakte Schreibweisen erwartet. Schon kleine Unterschiede in Groß- und Kleinschreibung können dazu führen, dass eine Spalte nicht gefunden wird.
Die Anzeige der Spaltennamen ist vor allem dann hilfreich, wenn:
- Daten aus externen Systemen importiert wurden,
- viele Variablen vorhanden sind oder
- der Datensatz zum ersten Mal untersucht wird.
Mit einem schnellen Blick auf die Spaltenübersicht können Sie anschließend gezielt entscheiden, welche Variablen für Ihre Analyse relevant sind.
Weitere grundlegende Informationen über einen DataFrame
Neben den bisher vorgestellten Funktionen bietet Pandas noch weitere Möglichkeiten, um einen schnellen Überblick über einen Datensatz zu erhalten. Diese Funktionen helfen dabei, grundlegende Eigenschaften eines DataFrames zu verstehen, und sie liefern zusätzliche Informationen über Struktur und Inhalt der Daten.
Gerade bei der explorativen Datenanalyse ist es hilfreich, möglichst schnell Antworten auf Fragen wie diese zu bekommen:
- Wie groß ist der Datensatz?
- Wie viele Zeilen und Spalten enthält die Tabelle?
- Welche Werte sind im DataFrame gespeichert?
- Wie kann man schnell zufällige Stichproben der Daten betrachten?
Pandas stellt dafür mehrere einfache Eigenschaften und Funktionen bereit, mit denen sich diese Fragen schnell beantworten lassen. Dazu gehören unter anderem:
- values
- shape
- len()
- sample()
Diese Funktionen ergänzen die bisher vorgestellten Analysewerkzeuge wie info(), dtypes und describe() und helfen dabei, einen Datensatz noch besser zu verstehen.
Werte eines DataFrames anzeigen – values
Neben den Spaltennamen oder statistischen Kennzahlen kann es interessant sein, sich die reinen Datenwerte eines DataFrames anzeigen zu lassen.
Dafür stellt Pandas die Eigenschaft values zur Verfügung.
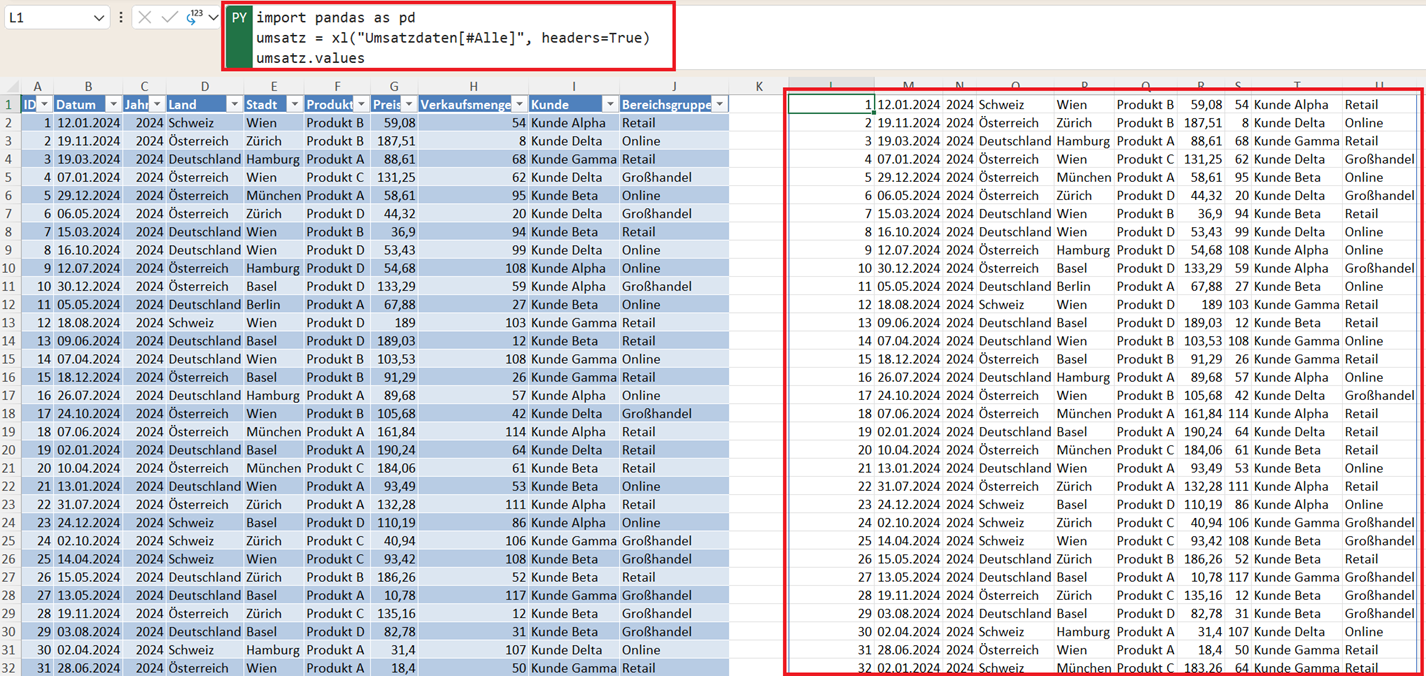
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz.values
Nach der Ausführung gibt Pandas alle Datenwerte des DataFrames zurück. Das Ergebnis ist jedoch keine Tabelle im klassischen Sinne, sondern ein sogenanntes NumPy-Array.
Ein NumPy-Array ist eine spezielle Datenstruktur aus der Python-Bibliothek NumPy, die besonders für numerische Berechnungen optimiert ist.
Unterschied zum normalen DataFrame
Im Gegensatz zur normalen DataFrame-Darstellung enthält das Ergebnis von values nur die reinen Datenwerte. Das bedeutet:
- keine Spaltennamen
- keine Indexinformationen
- nur die tatsächlichen Daten
Die Ausgabe stellt also lediglich die Datenmatrix dar, die im Hintergrund des DataFrames gespeichert ist.
Wann ist values hilfreich?
In der Praxis wird values vor allem dann verwendet, wenn man die Daten eines DataFrames direkt weiterverarbeiten möchte, zum Beispiel für
- numerische Berechnungen
- mathematische Operationen
- Übergaben an andere Python-Bibliotheken
Für eine rein visuelle Analyse innerhalb von Excel ist diese Darstellung meist weniger relevant, da hier wichtige Kontextinformationen wie Spaltennamen fehlen. Dennoch hilft values dabei, zu verstehen, wie ein DataFrame intern aufgebaut ist.
Struktur eines DataFrames anzeigen – shape
Eine besonders hilfreiche Methode in Pandas ist shape. Mit ihr lässt sich feststellen, wie groß ein DataFrame ist. Die Eigenschaft shape gibt die Dimensionen des DataFrames zurück, also die Anzahl der Zeilen und Spalten.
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz.shape
Nach der Ausführung erhalten Sie eine Ausgabe in Form eines Tupels wie (150, 10). Diese beiden Werte haben folgende Bedeutung:
- 150 → Anzahl der Zeilen (Datensätze)
- 10 → Anzahl der Spalten (Variablen)
Damit erkennen Sie sofort, wie viele Beobachtungen und Variablen Ihr Datensatz enthält.

Warum ist shape so nützlich?
Gerade bei der Arbeit mit größeren Datenmengen ist es wichtig zu wissen, wie groß ein Datensatz tatsächlich ist. Die Funktion shape hilft zum Beispiel bei folgenden Fragestellungen:
- Wurden alle Daten korrekt importiert?
- Wie viele Datensätze sind vorhanden?
- Wie viele Variablen enthält der Datensatz?
Diese Information ist besonders hilfreich, wenn Daten aus externen Quellen wie Datenbanken, ERP-Systemen oder CSV-Dateien importiert wurden. Mit einem einzigen Befehl können Sie sofort überprüfen, ob der Datensatz vollständig geladen wurde.
Unterschied zu anderen Analysefunktionen
Während Funktionen wie info() oder describe() detaillierte Informationen über den Datensatz liefern, konzentriert sich shape ausschließlich auf die Größe des DataFrames.
Gerade deshalb wird diese Eigenschaft oft verwendet, da sie schnell einen ersten Überblick über den Datensatz liefert.
Anzahl von Zeilen und Spalten bestimmen – len()
Neben der Eigenschaft shape gibt es in Python noch eine weitere Möglichkeit, die Größe eines DataFrames zu bestimmen. Dafür kann die allgemeine Python-Funktion len() verwendet werden.
Die Funktion len() wird in Python häufig genutzt, um die Länge eines Objekts zu bestimmen. In unserem Fall kann sie beispielsweise eingesetzt werden, um die Anzahl der Spalten oder Zeilen eines DataFrames zu ermitteln.
Wenn Sie wissen möchten, wie viele Spalten ein DataFrame enthält, können Sie len() auf die Eigenschaft columns anwenden.
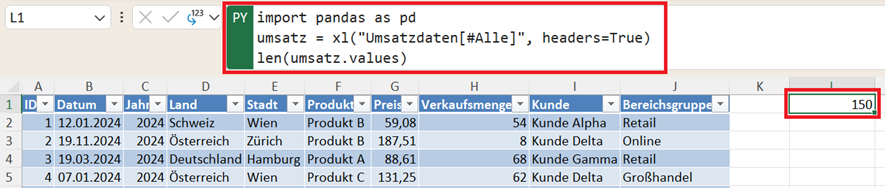
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
len(umsatz.columns)
Das Ergebnis ist eine Zahl, die angibt, wie viele Spalten im DataFrame vorhanden sind. Im Beispiel ist das Ergebnis 10, weil der Datensatz zehn Variablen enthält.

Auch die Anzahl der Datensätze in den Zeilen lässt sich bestimmen. Dafür kann len() auf die Werte, values, des DataFrames angewendet werden.
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
len(umsatz.values)
Das Ergebnis zeigt die Anzahl der Zeilen im DataFrame, also die Anzahl der vorhandenen Datensätze. Im Beispiel sind das 150 Einträge.
Warum ist diese Methode nützlich?
Die Funktion len() ist besonders hilfreich, wenn man schnell eine einzelne Kennzahl über die Größe eines Datensatzes benötigt.
Während shape gleichzeitig Zeilen und Spalten zurückgibt, liefert len() jeweils nur eine einzelne Zahl. Das kann in manchen Fällen praktischer sein, beispielsweise wenn man diese Zahl direkt in weiteren Berechnungen verwenden möchte.
Zufällige Stichproben aus einem Datensatz ziehen – sample()
Bei der Arbeit mit größeren Datensätzen ist es hilfreich, sich zunächst nur einen kleinen zufälligen Ausschnitt der Daten anzusehen. Dadurch kann man schnell einen ersten Eindruck von der Struktur und den Inhalten des Datensatzes gewinnen.
In Excel würde man dafür häufig eine zusätzliche Spalte mit Zufallszahlen erzeugen und anschließend den Datensatz nach dieser Spalte sortieren. Anschließend könnte man beispielsweise die ersten zehn Zeilen auswählen.
Mit Pandas lässt sich dieser Vorgang deutlich einfacher umsetzen. Die Funktion sample() erzeugt eine zufällige Stichprobe aus einem DataFrame.
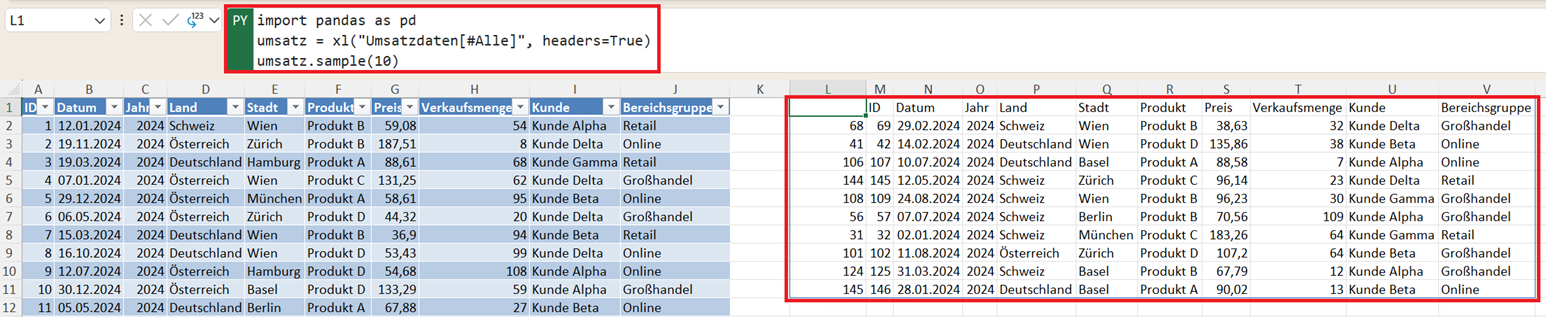
Wenn Sie beispielsweise zehn zufällige Datensätze auswählen möchten, können Sie folgenden Befehl verwenden:
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz.sample(10)
Pandas wählt daraufhin zehn zufällige Zeilen aus dem DataFrame aus und gibt diese zurück.
Wenn Sie den Befehl erneut ausführen, werden in der Regel andere zufällige Datensätze ausgewählt. Dadurch lässt sich schnell ein Überblick über unterschiedliche Teile des Datensatzes gewinnen.
Einen prozentualen Anteil der Daten auswählen
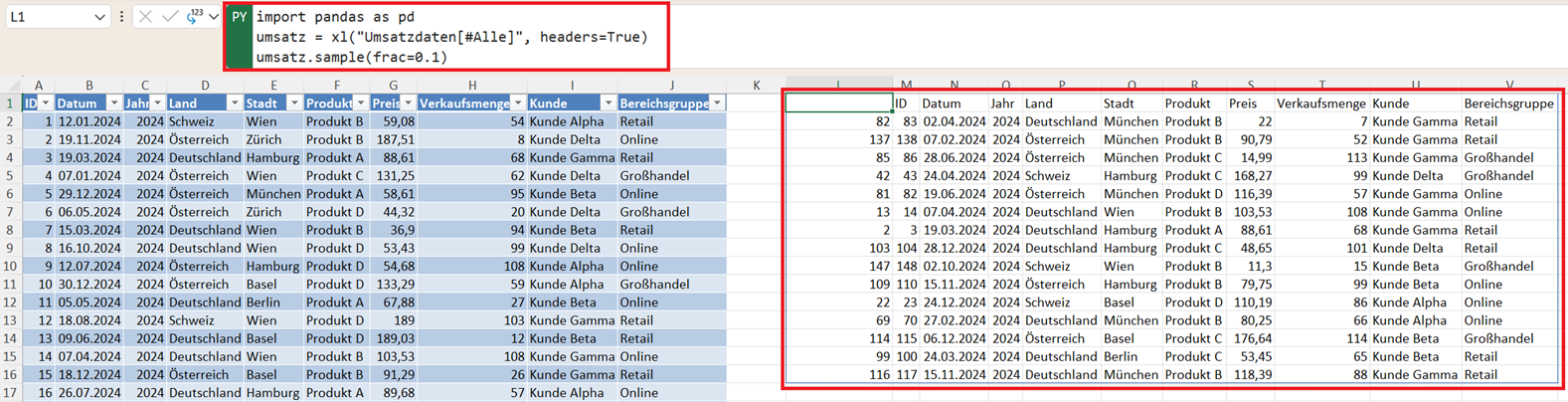
Neben einer festen Anzahl von Zeilen können Sie auch einen bestimmten Anteil des Datensatzes auswählen. Dafür wird der Parameter frac verwendet (Abkürzung für fraction).
Beispiel: Sie wollen für Ihre Zufallsziehung 10 % der Daten auswählen.
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz.sample(frac=0.1)
Angenommen, Ihr Datensatz enthält 150 Einträge, dann würden in diesem Fall 15 zufällige Zeilen ausgewählt.
Diese Methode ist besonders nützlich, wenn Sie mit sehr großen Datensätzen arbeiten und zunächst nur einen kleinen Teil der Daten betrachten möchten.
Typische Anwendungsfälle
Die Funktion sample() wird häufig eingesetzt, um:
- schnell einen Eindruck von einem großen Datensatz zu erhalten,
- Stichproben für Analysen zu erzeugen oder
- zufällige Datensätze für Tests oder Demonstrationen auszuwählen.
Gerade bei explorativen Analysen kann eine zufällige Stichprobe sehr hilfreich sein, um typische Datenwerte und mögliche Auffälligkeiten im Datensatz zu erkennen.


