Python in Excel für die DatenanalyseKorrelationen und Zusammenhänge analysieren
- Warum Zusammenhänge in Daten wichtig sind
- Datensatz laden und vorbereiten
- Qualitätscheck der Daten
- Fehlende Werte behandeln
- Was bedeutet Korrelation?
- Welche Methoden gibt es für die Berechnung von Korrelationen?
- Erste Korrelation berechnen
- Mehrere Kennzahlen gleichzeitig analysieren
- Korrelationen mit einer Heatmap visualisieren
- Streudiagramm zur Visualisierung
- Vorsicht bei der Interpretation von Korrelationen
- Fazit
Warum Zusammenhänge in Daten wichtig sind
In vielen Analysen reicht es nicht aus, einzelne Kennzahlen isoliert zu betrachten. Oft stellen sich weiterführende Fragen wie:
- Gibt es einen Zusammenhang zwischen Preis und Verkaufsmenge?
- Verkaufen sich günstige Produkte besser?
- Steigen Umsätze mit höheren Preisen?
- Welche Kennzahlen beeinflussen sich gegenseitig?
Solche Fragestellungen untersuchen Sie mit Korrelationen. Eine Korrelation beschreibt, wie stark zwei Variablen miteinander zusammenhängen. Das ist besonders wichtig für:
- Controlling
- Vertriebsanalysen
- Forecasting
- Datenanalysen
- Business Intelligence
Datensatz laden und vorbereiten
Grundlage für das folgende Beispiel und die Erläuterungen ist ein Datensatz mit Verkäufen und den Angaben zu Produkt, Kategorie, Preis und Verkaufsmenge.
Zusätzlich wird die Kennzahl Umsatz berechnet, damit Sie mehrere numerische Variablen vergleichen können.
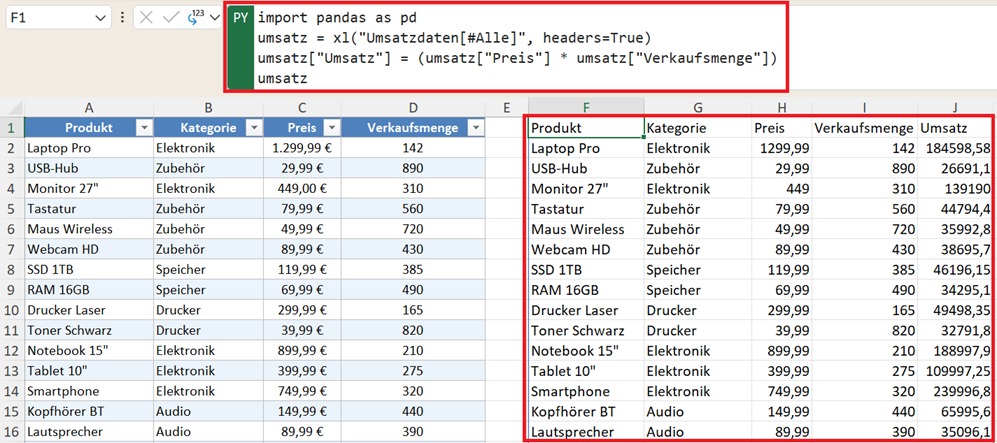
Zunächst werden diese Daten in den DataFrame von Python importiert.
import pandas as pd
umsatz = xl("Umsatzdaten_Filter[#Alle]", headers=True)
umsatz["Umsatz"] = (umsatz["Preis"] * umsatz["Verkaufsmenge"])
umsatz
Qualitätscheck der Daten
Gerade bei Analysen mit Korrelationen ist ein Qualitätscheck der Daten wichtig, da fehlerhafte Datentypen oder fehlende Werte die Ergebnisse verfälschen können.
Mit wenigen Zeilen Python-Code erhalten Sie bereits einen sehr guten ersten Überblick über die Struktur Ihrer Daten.
print(umsatz.head())
Mit head() werden standardmäßig die ersten fünf Zeilen des DataFrames ausgegeben.
Dadurch können Sie schnell prüfen:
- Wurden die Daten korrekt eingelesen?
- Stimmen die Spaltennamen?
- Sind die Werte plausibel?
- Gibt es offensichtliche Fehler?
print(umsatz.dtypes)
Korrelationen funktionieren nur mit numerischen Werten sinnvoll. Deshalb sollten Sie mit .dtypes unbedingt kontrollieren, ob Zahlen tatsächlich als Zahlen erkannt wurden.
Typische Datentypen sind beispielsweise:
- int64 → ganze Zahlen
- float64 → Dezimalzahlen
- object → Textwerte
- datetime64[ns] → Datumswerte
Ein häufiger Fehler: Excel-Spalten mit Zahlen werden manchmal als Text (object) importiert – etwa durch Leerzeichen, Sonderzeichen oder gemischte Inhalte. In solchen Fällen funktionieren mathematische Auswertungen nicht korrekt.
Hinweis: Sollten Sie bei einer Korrelationsanalyse Textspalten versehentlich einbeziehen, kommt es zu Fehlern. Wählen Sie deshalb nur die numerischen Spalten aus mit:
umsatz.select_dtypes(include='number')
In Pandas ergänzen Sie bei .corr() den Parameter numeric_only=True, damit Textspalten sicher ignoriert werden.
print(umsatz.isnull().sum())
Mit .isnull().sum() zählen Sie die fehlenden Werte je Spalte. Das ist besonders wichtig für Korrelationsanalysen, denn fehlende Werte können:
- Berechnungen verfälschen
- Zeilen ausschließen
- Fehlermeldungen verursachen
- statistische Ergebnisse beeinflussen
Typische Ursachen für fehlende Werte:
- leere Excel-Zellen
- fehlerhafte Importe
- unvollständige Datensätze
- Tippfehler oder falsche Formate
Viele Probleme in Python entstehen nicht bei der eigentlichen Analyse, sondern bereits beim Import der Daten. Deshalb gilt: Ein Datencheck nach dem Import spart später viel Zeit bei der Fehlersuche.
Stellen Sie vor der Berechnung sicher, dass:
- die relevanten Spalten numerisch sind,
- keine unerwarteten Textwerte enthalten sind,
- fehlende Werte bekannt sind,
- und die Daten grundsätzlich plausibel wirken.
Fehlende Werte behandeln
Bevor Sie eine Korrelation berechnen, sollten Sie sich noch um fehlende Werte kümmern. Gerade bei statistischen Analysen ist das wichtig, denn fehlende Werte (NaN) können das Ergebnis verfälschen oder sogar dazu führen, dass Berechnungen fehlschlagen.
Pandas in Python bietet hierfür verschiedene Möglichkeiten.
Variante 1: Betroffene Zeilen entfernen
Wenn nur wenige Datensätze betroffen sind, ist das Entfernen der Zeilen oft die einfachste Lösung.
umsatz = umsatz.dropna(subset=["Preis", "Verkaufsmenge", "Umsatz"])
Mit dropna() werden alle Zeilen gelöscht, in denen mindestens einer der angegebenen Werte fehlt. Die Angabe: subset=["Preis", "Verkaufsmenge", "Umsatz"] bedeutet:
- Prüfe nur diese drei Spalten
- Entferne Zeilen mit fehlenden Werten in diesen Spalten
- Der ursprüngliche DataFrame wird dabei direkt überschrieben.
Diese Variante eignet sich besonders dann, wenn:
- nur wenige Zeilen fehlen,
- genügend Daten vorhanden sind,
- die fehlenden Werte zufällig auftreten,
- kein wichtiger Informationsverlust entsteht.
Variante 2: Fehlende Werte ersetzen
Bei kleinen Datensätzen oder vielen fehlenden Werten kann es sinnvoller sein, die fehlenden Werte zu ersetzen, statt ganze Zeilen zu löschen. Ein häufiger Ansatz ist die Ersetzung durch den Mittelwert.
umsatz['Preis'] = umsatz['Preis'].fillna(umsatz['Preis'].mean())
Die Methode umsatz['Preis'].mean() berechnet zunächst den Durchschnitt der vorhandenen Werte. Mit fillna(…) werden anschließend alle fehlenden Werte durch diesen Durchschnitt ersetzt.
Dadurch verlieren Sie keine Datensätze. Das kann insbesondere bei kleineren Stichproben oder umfangreichen Analysen hilfreich sein.
Allerdings verändert diese Methode die Daten künstlich. Dadurch können:
- Durchschnittswerte beeinflusst werden,
- Streuungen kleiner wirken,
- Korrelationen leicht verfälscht werden.
Deshalb sollte man immer überlegen, welche Methode fachlich sinnvoller ist.
Was bedeutet Korrelation?
Die Korrelation misst die Stärke eines Zusammenhangs zwischen zwei Variablen. Die Werte, der sogenannte Korrelationskoeffizient, liegen immer zwischen -1 und +1:
- +1 = perfekter positiver Zusammenhang → steigt A, steigt auch B proportional.
- 0 = kein Zusammenhang → die Variablen beeinflussen sich gar nicht.
- -1 = perfekter negativer Zusammenhang → steigt A, sinkt B proportional.
Für die Praxis hilft folgende Daumenregel, um die Werte dazwischen einzuschätzen:
- 0,0 bis 0,2: sehr schwache oder keine Korrelation
- 0,2 bis 0,5: schwache bis mittlere Korrelation
- 0,5 bis 0,7: moderate bis starke Korrelation
- 0,7 bis 1,0: sehr starke Korrelation
Beispiele:
- Höhere Marketingausgaben → höhere Besucherzahlen auf der Website.
- Höherer Produktpreis → geringere Nachfrage.
Welche Methoden gibt es für die Berechnung von Korrelationen?
Standardmäßig berechnet die Funktion .corr() die Pearson-Korrelation (linearer Zusammenhang). Für nichtlineare, aber monotone Zusammenhänge können Sie auch Spearman verwenden.
Wollen Sie den Zusammenhang zwischen Preis und Verkaufsmenge ermitteln, lautet der entsprechende Python-Code:
umsatz[["Preis", "Verkaufsmenge"]].corr(method="spearman", numeric_only=True)
Wann nimmt man Spearman statt Pearson?
Pearson erfasst nur lineare Zusammenhänge. Spearman arbeitet mit Rängen (ordinale Skala der Daten) und ist robuster bei nichtlinearen, aber monotonen Beziehungen – zum Beispiel, wenn der Preis sinkt und die Nachfrage steigt, aber nicht proportional. Auch bei starken Ausreißern ist Spearman oft die bessere Wahl.
Für sehr kleine Stichproben gibt es noch Kendall-Tau: method="kendall".
Welche Methode ist besser für das Ersetzen fehlender Daten?
Das hängt stark von den Daten ab. Zeilen entfernen ist gut geeignet bei:
- wenigen fehlenden Werten
- großen Datensätzen
- zufälligen Ausfällen
Werte ersetzen ist gut geeignet bei:
- vielen fehlenden Werten
- kleinen Datensätzen
- wenn möglichst keine Daten verloren gehen sollen
Bei professionellen statistischen Analysen werden fehlende Werte dagegen oft deutlich genauer untersucht und mit komplexeren Verfahren behandelt.
Erste Korrelation berechnen
Die zentrale Pandas-Funktion lautet: .corr(). Für den hier verwendeten Beispieldatensatz lautet dann der Pandas-Befehl:
umsatz[["Preis","Verkaufsmenge"]].corr(numeric_only=True)
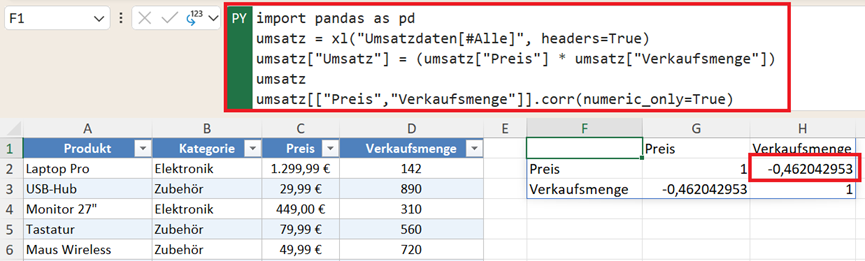
Die Korrelation zwischen Preis und Verkaufsmenge beträgt hier -0,46. Das bedeutet:
- mittlerer negativer Zusammenhang
- höhere Preise führen tendenziell zu weniger Verkaufsmenge
- der Zusammenhang ist nach der oben genannten Daumenregel nicht besonders stark
Mehrere Kennzahlen gleichzeitig analysieren
Interessanter wird es, wenn mehrere Variablen gleichzeitig untersucht werden:
umsatz[["Preis", "Verkaufsmenge", "Umsatz"]].corr(numeric_only=True)
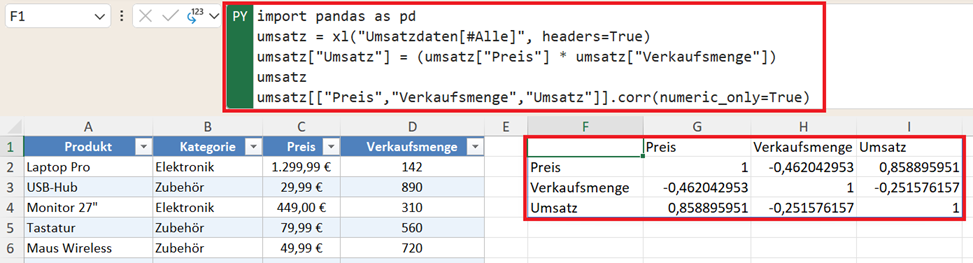
Damit erkennen Sie:
- welche Variablen zusammenhängen; zum Beispiel haben Preis und Umsatz mit 0,85 eine starke positive Korrelation
- welche kaum Einfluss aufeinander haben, wie im Beispiel die Verkaufsmenge und der Umsatz (Korrelationskoeffizient = -0,25).
Korrelationen mit einer Heatmap visualisieren
Eine reine Tabelle ist bei vielen Kennzahlen oft schwer zu interpretieren. Deshalb werden Korrelationsmatrizen häufig als Heatmap dargestellt. Dafür nutzen Sie den folgenden Python-Code:
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(8,5))
korrelation = umsatz[[ "Preis", "Verkaufsmenge", "Umsatz"]].corr(numeric_only=True)
sns.heatmap(
korrelation,
annot=True,
fmt=".2f",
cmap="coolwarm",
vmin=-1, vmax=1, center=0
)
Stellen Sie die Zelle mit dem Python-Code auf Excel-Wert um. Excel bettet das Diagramm dann automatisch als Bild direkt in die Zelle ein. Sie können die Zelle danach einfach größer ziehen.
Sie können die Heatmap auch als Bild speichern. Sie steht dann als separates Bildobjekt zur Verfügung. Klicken Sie einfach auf die Schaltfläche Verweis erstellen, die am rechten Zellrand angezeigt wird.
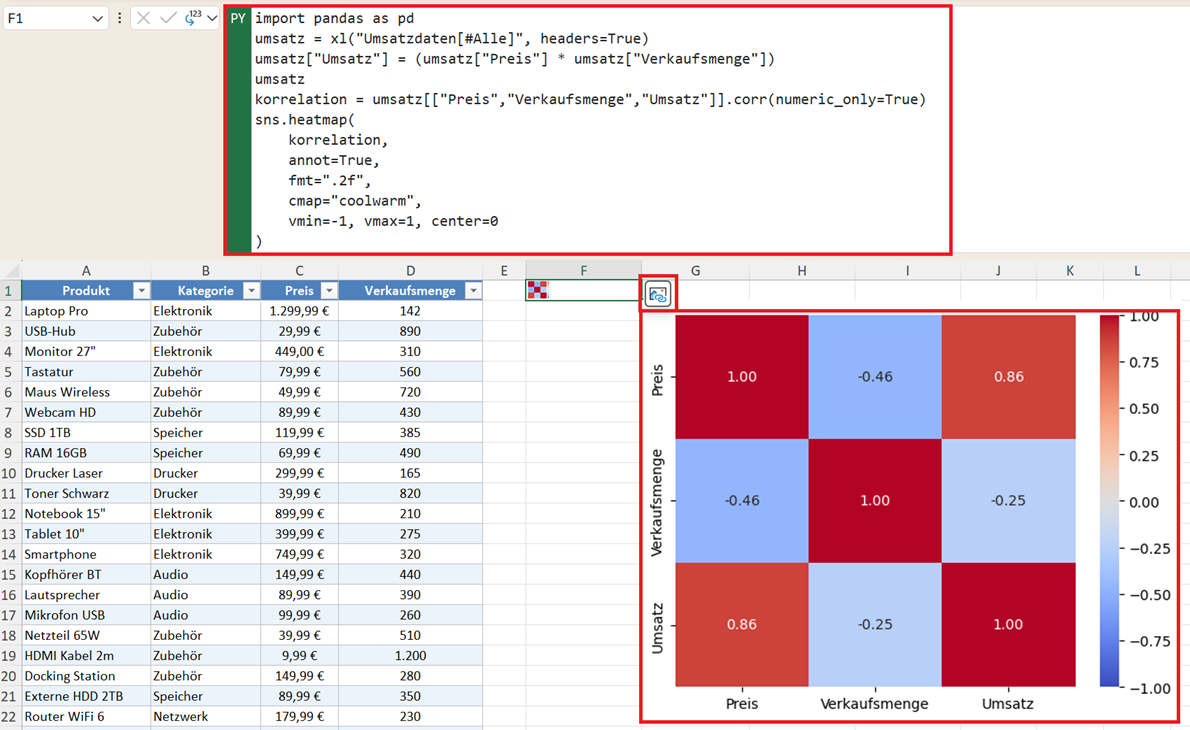
Mit einer Heatmap erkennen Sie sofort durch die farbliche Abstufung:
- starke Zusammenhänge
- schwache Zusammenhänge
- positive oder negative Beziehungen
Gerade bei größeren Datensätzen mit vielen Kennzahlen ist das wesentlich übersichtlicher als eine reine Zahlentabelle.
Streudiagramm zur Visualisierung
Neben Heatmaps eignet sich auch ein Streudiagramm (Scatterplot) hervorragend, um die Rohdaten zu betrachten. Mit diesem Python-Code erstellen Sie ein Streudiagramm:
sns.scatterplot(
data=umsatz,
x="Preis",
y="Verkaufsmenge"
)
plt.title("Zusammenhang zwischen Preis und Verkaufsmenge")
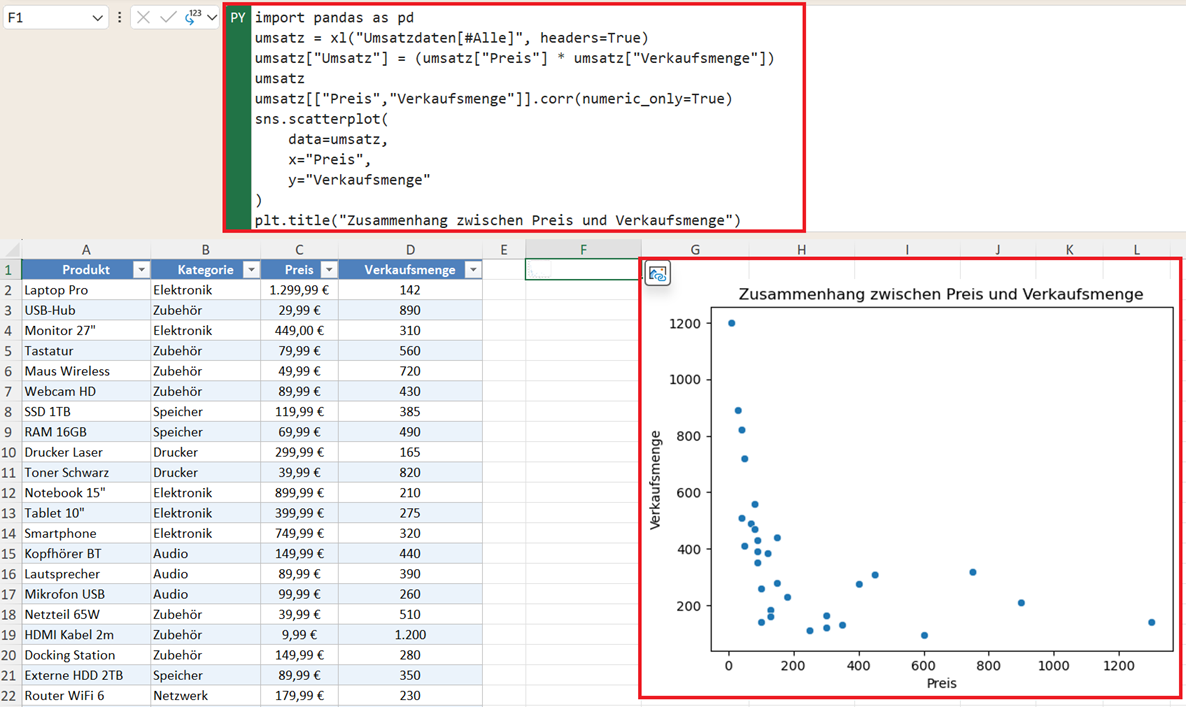
Ein Streudiagramm zeigt:
- Muster
- Cluster (Datenwolken)
- Ausreißer (extreme Datenpunkte)
- Trends
Oft erkennt man visuell durch die Verteilung der Punkte mehr als über reine, nackte Kennzahlen.
Vorsicht bei der Interpretation von Korrelationen
Korrelation bedeutet nicht automatisch Ursache (Kausalität). Nur weil zwei Datenreihen sich mathematisch ähnlich bewegen, muss die eine nicht der Grund für die andere sein.
Ein Beispiel: Ein Online-Shop stellt fest, dass die Verweildauer auf der Website stark mit den Umsätzen korreliert. Heißt das, man muss die Website absichtlich unübersichtlicher machen, damit die Kunden länger suchen müssen und dadurch mehr kaufen? Nein.
Eine dritte Variable – wie eine attraktive Rabattaktion oder die Vorweihnachtszeit – sorgt wahrscheinlich gleichzeitig dafür, dass Kunden länger stöbern und mehr kaufen.
Noch ein typisches Beispiel: Eisverkauf und Häufigkeit von Sonnenbrand korrelieren stark positiv. Nicht das Eis verursacht Sonnenbrand, sondern die dritte Variable Temperatur treibt beides nach oben.
Wenn beide Reihen über die Zeit steigen, messen Sie oft nur den gemeinsamen Trend. Entfernen Sie den Trend vorher oder arbeiten Sie mit Differenzen, sonst entsteht eine Scheinkorrelation.
Weitere Faktoren im Business sind immer relevant:
- Werbung und Marketing
- Saisonale Effekte
- Rabatte und Aktionen
- Allgemeine Marktbedingungen
Fazit
Die Korrelationsanalyse gehört zu den wichtigsten Methoden der Datenanalyse. Mit Pandas und Seaborn in Excel können Sie:
- Zusammenhänge schnell erkennen
- Kennzahlen nachvollziehbar vergleichen
- Beziehungen professionell visualisieren
- Trends frühzeitig identifizieren
- Strategische Entscheidungen fundierter treffen


