Python in Excel für die DatenanalyseSpalten gezielt analysieren und Kennzahlen ermitteln
- Warum Spaltenanalysen wichtig sind
- Durchschnittswerte berechnen – mean()
- Häufigste Werte ermitteln – mode()
- Eindeutige Werte in einer Spalte ermitteln – unique()
- Anzahl eindeutiger Werte bestimmen – nunique()
- Gesamtumsatz berechnen
- Durchschnittlicher Umsatz pro Transaktion berechnen
- Größte Werte finden – nlargest()
- Kleinste Werte finden – nsmallest()
Warum Spaltenanalysen wichtig sind
In vielen praktischen Analysen interessiert man sich nicht für alle Variablen gleichzeitig. Häufig stehen einzelne Kennzahlen im Mittelpunkt, zum Beispiel:
- Preis eines Produkts
- verkaufte Stückzahl
- Umsatz einer Transaktion
- geografische Informationen wie Land oder Stadt
Mit Pandas lassen sich solche Spalten sehr einfach auswählen und analysieren. Dadurch können Sie schnell wichtige Kennzahlen berechnen und interessante Muster in den Daten erkennen.
Durchschnittswerte berechnen – mean()
Eine häufige Fragestellung bei der Analyse von Daten lautet: Wie hoch ist der durchschnittliche Wert einer Variablen?
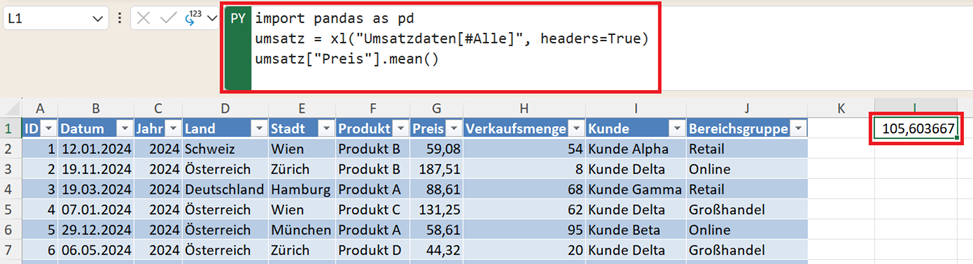
In Pandas lässt sich der Mittelwert mit der Funktion mean() berechnen. Beispiel: durchschnittlicher Preis:
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz["Preis"].mean()
Das Ergebnis zeigt den durchschnittlichen Preis aller Transaktionen. Der Mittelwert ist eine der wichtigsten Kennzahlen in der Datenanalyse und wird häufig für erste Einschätzungen verwendet.
Häufigste Werte ermitteln – mode()
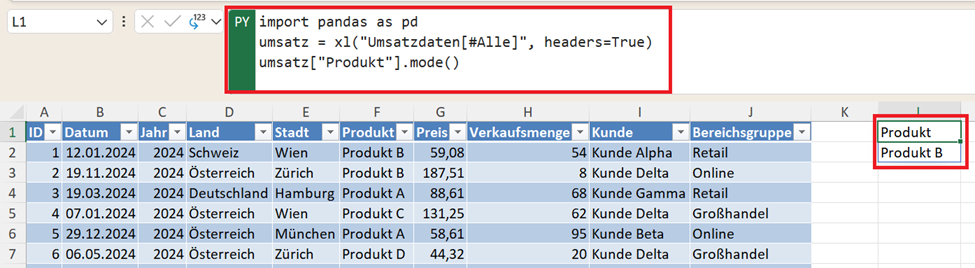
Neben Durchschnittswerten kann auch der häufigste Wert einer Spalte interessant sein. Diese Kennzahl nennt man Modus. Beispiel: häufigstes Produkt
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz["Produkt"].mode()
Das Ergebnis zeigt den Wert, der im Datensatz am häufigsten vorkommt. Diese Kennzahl wird häufig verwendet, um typische Kategorien oder dominante Werte zu erkennen.
Eindeutige Werte in einer Spalte ermitteln – unique()
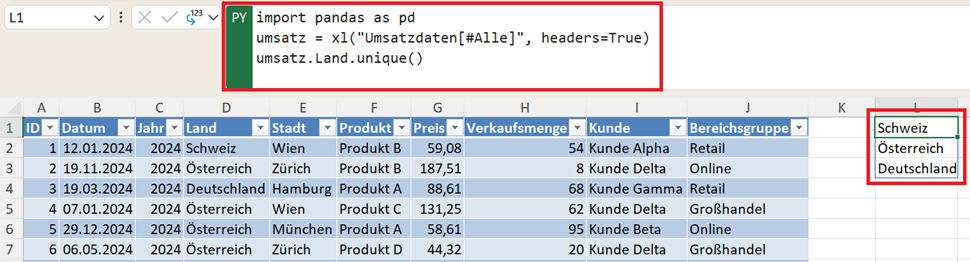
Eine weitere wichtige Frage bei der Analyse lautet: Welche Merkmalsausprägungen für eine Variable existieren überhaupt im Datensatz? Diese Information lässt sich mit der Funktion unique() ermitteln. Beispiel:
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz.Land.unique()
Das Ergebnis ist eine Liste aller einzigartigen Werte in dieser Spalte. Damit können Sie beispielsweise erkennen, in welchen Ländern Verkäufe stattgefunden haben.
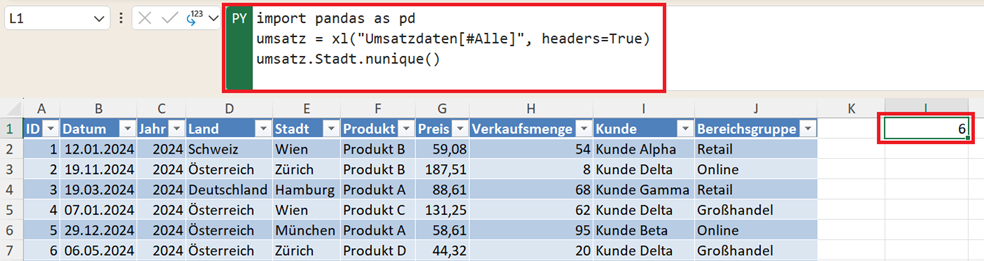
Anzahl eindeutiger Werte bestimmen – nunique()
Manchmal interessiert nicht der konkrete Wert, sondern nur die Anzahl der unterschiedlichen Einträge. Dafür gibt es die Funktion nunique().
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz.Stadt.nunique()
Das Ergebnis könnte zum Beispiel zeigen, dass Verkäufe in 6 verschiedenen Städten stattgefunden haben.
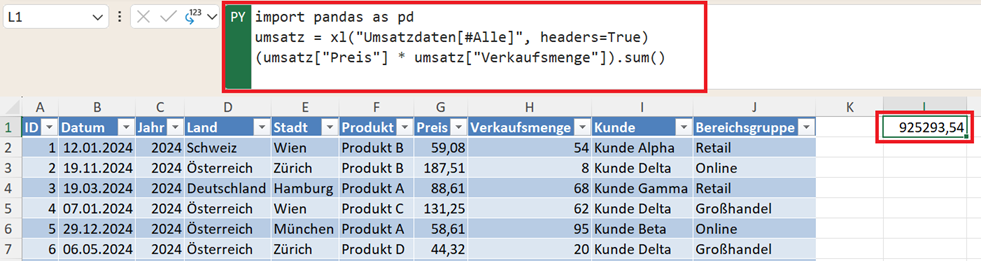
Gesamtumsatz berechnen
Eine besonders wichtige Kennzahl für viele Business-Analysen ist der Gesamtumsatz. Der Umsatz ergibt sich aus:
Preis × Verkaufsmenge
Mit Pandas lässt sich diese Kennzahl sehr einfach berechnen, indem eine Summe mit sum() gebildet wird.
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
(umsatz["Preis"] * umsatz["Verkaufsmenge"]).sum()
Hier passiert Folgendes:
- Preis und Verkaufsmenge werden für jede Zeile miteinander multipliziert
- Daraus entsteht der Umsatz pro Transaktion (Zeile)
- Anschließend werden alle Werte aufsummiert
Das Ergebnis ist der Gesamtumsatz des gesamten Datensatzes.
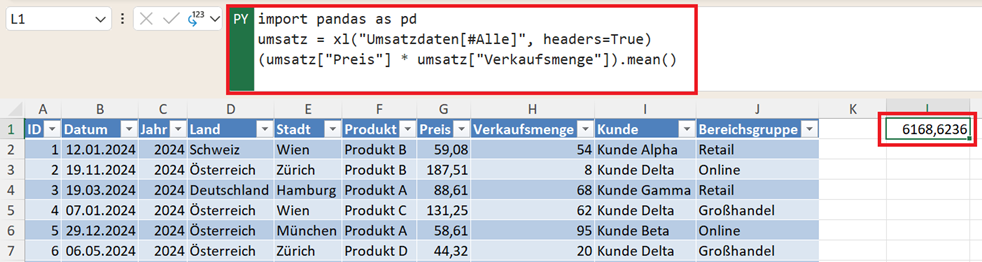
Durchschnittlicher Umsatz pro Transaktion berechnen
Neben dem Gesamtumsatz ist häufig auch der durchschnittliche Umsatz pro Transaktion interessant.
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
(umsatz["Preis"] * umsatz["Verkaufsmenge"]).mean()
Diese Kennzahl zeigt, wie hoch der Umsatz im Durchschnitt pro Verkauf ist. Sie wird häufig verwendet für:
- Vertriebsanalysen
- Performance-Messungen
- Vergleich unterschiedlicher Zeiträume
Die Berechnung des Gesamtumsatzes und des durchschnittlichen Umsatzes zeigt das Prinzip, nach dem Python und Pandas rechnen:
- Der Ausdruck in der Klammer (), hier Preis × Umsatz, wird zunächst für jeden einzelnen Datensatz aus den angegebenen Variablen (Preis und Umsatz) berechnet: hier: Multiplikation (*).
- Dann geben Sie an, was mit diesem berechneten Wert als Nächstes berechnet werden soll. Im ersten Fall die Summe sum() und im zweiten Fall der Mittelwert mean().
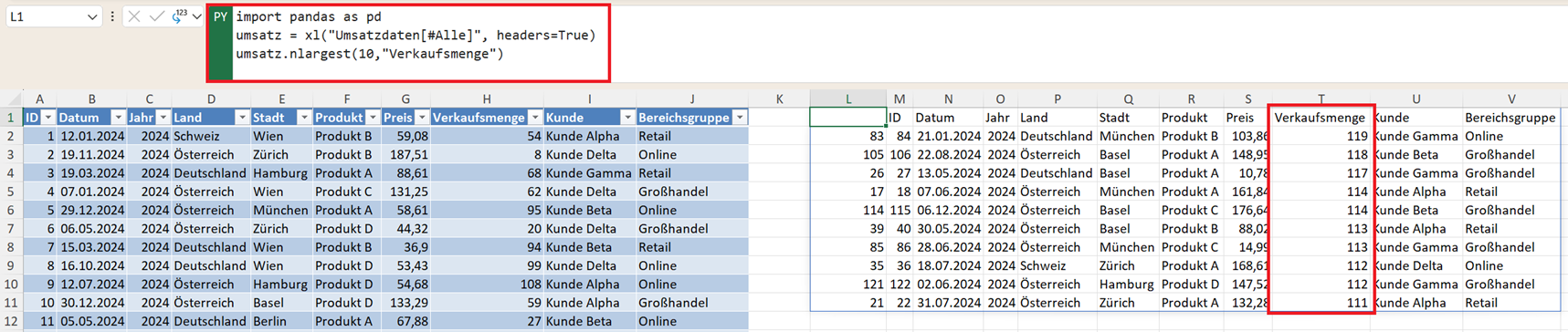
Größte Werte finden – nlargest()
Eine weitere sehr hilfreiche Funktion ist nlargest(). Damit lassen sich die größten Werte einer Spalte schnell ermitteln. Beispiel: die zehn größten Transaktionen mit der höchsten Verkaufsmenge:
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz.nlargest(10,"Verkaufsmenge")
Solche Analysen helfen beispielsweise dabei, besonders große Verkäufe oder wichtige Kunden zu identifizieren.
Kleinste Werte finden – nsmallest()
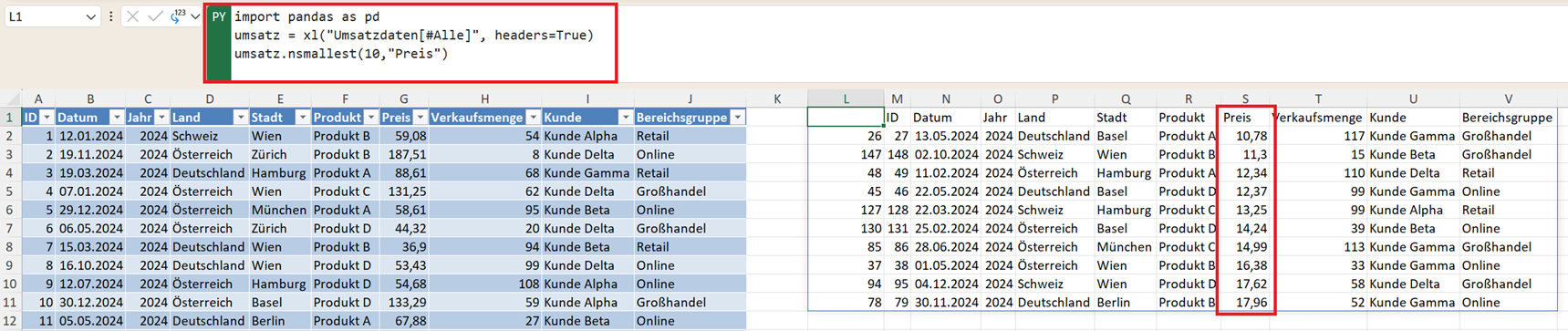
Analog dazu gibt es auch die Funktion nsmallest(), mit der sich die kleinsten Werte einer Spalte anzeigen lassen. Beispiel: die zehn niedrigsten Preise.
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz.nsmallest(10,"Preis")
Diese Funktion kann beispielsweise verwendet werden, um:
- besonders günstige Produkte zu identifizieren
- ungewöhnlich niedrige Werte zu finden
- mögliche Dateneingabefehler aufzudecken