Python in Excel für die DatenanalyseTextdaten verarbeiten mit Pandas in Python in Excel
- Warum Textdaten oft problematisch sind
- Datensatz laden
- Text suchen – str.contains()
- Einstellungen für str.contains()
- Text ersetzen – str.replace()
- Leerzeichen entfernen – str.strip()
- Fehlende Werte prüfen mit isnull().sum()
- Einheitliche Schreibweise herstellen
- Text aufteilen – str.split()
- Kategorien bereinigen
- Häufigkeiten von Texten analysieren
- Duplikate erkennen und entfernen
- Encoding-Probleme
Warum Textdaten oft problematisch sind
In vielen Datensätzen sind Textfelder eine große Herausforderung. Typische Probleme sind:
- unterschiedliche Schreibweisen ("Deutschland", "DE", "deutschland")
- Tippfehler
- zusätzliche Leerzeichen
- uneinheitliche Kategorien
Solche Probleme führen dazu, dass Auswertungen falsche Ergebnisse liefern.
Beispiel: Deutschland und deutschland werden als zwei unterschiedliche Werte behandelt.
Deshalb ist die Bereinigung von Textdaten ein wichtiger Schritt jeder Datenanalyse. Dazu gehen Sie folgendermaßen vor.
Datensatz laden
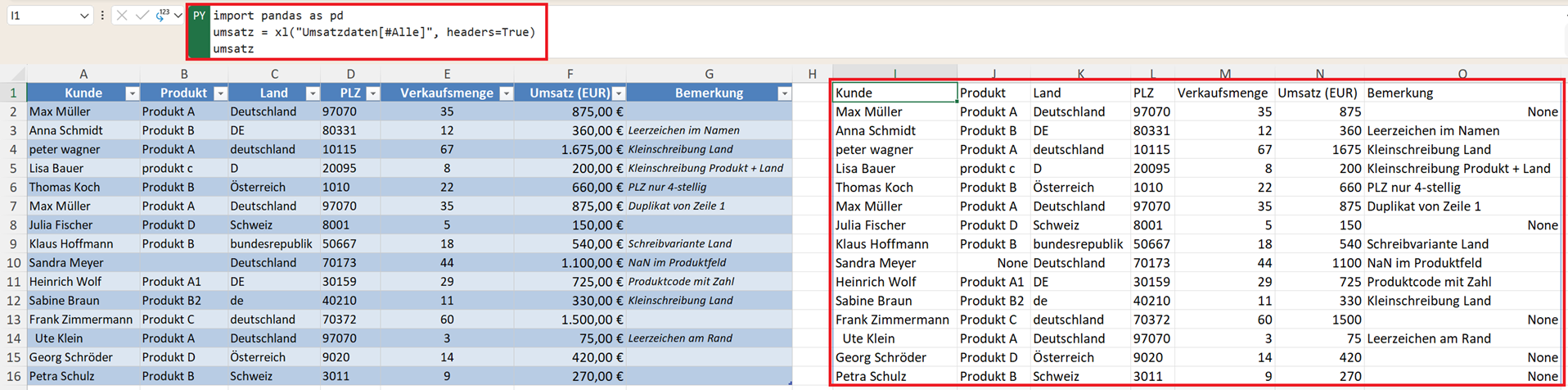
Zunächst laden Sie den Datensatz in Ihr DataFrame, den Sie überprüfen und bereinigen wollen:
import pandas as pd
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz
Text suchen – str.contains()
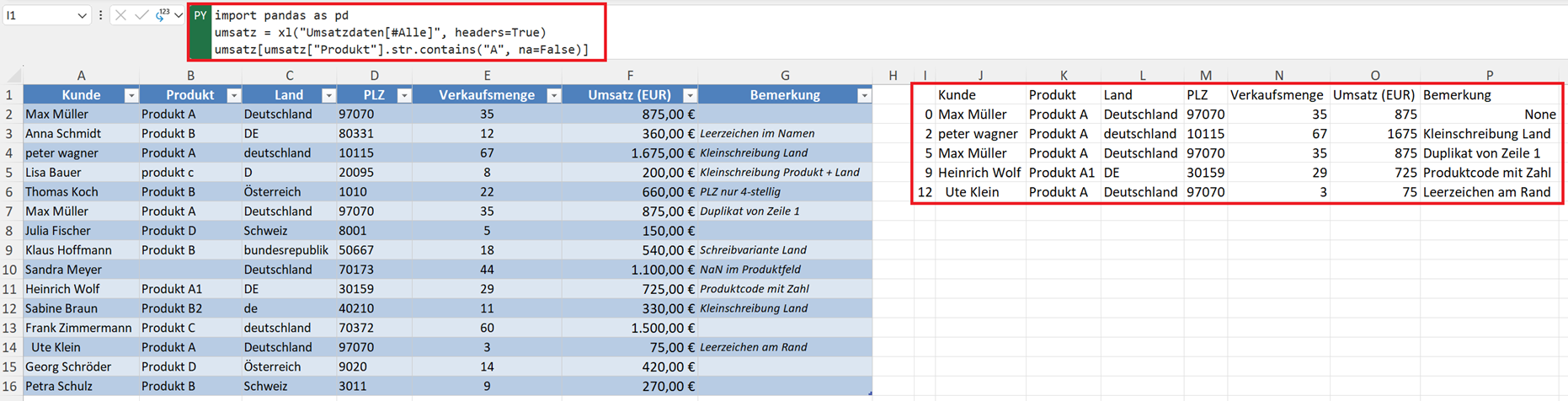
Eine der wichtigsten Funktionen für Textanalysen ist str.contains(). Damit können Sie prüfen, ob ein Text ein bestimmtes Wort enthält.
Beispiel: Alle Produkte mit "A".
umsatz[umsatz["Produkt"].str.contains("A", na=False)]
Ergebnis: Alle Zeilen, in denen "A" im Produktnamen vorkommt.
Einstellungen für str.contains()
na=False sorgt dafür, dass fehlende Werte beim Filtern nicht zu Problemen führen, sondern als False behandelt werden. Das ist besonders praktisch, wenn Ihr Datensatz leere Zellen enthält.
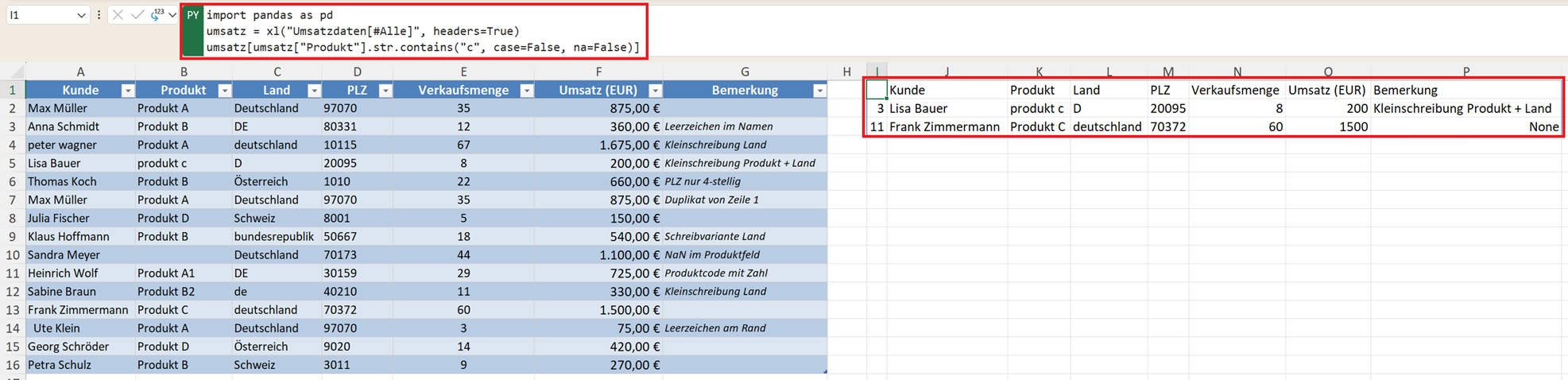
Mit der Einstellung case=False wird die Groß- oder Kleinschreibung ignoriert.
umsatz[umsatz["Produkt"].str.contains("c", case=False, na=False)]
Damit werden auch "c" und "C" gleichbehandelt.
Für komplexere Muster können Sie reguläre Ausdrücke nutzen, mit regex=True:
umsatz[umsatz["Produkt"].str.contains(r'A\d+', regex=True, na=False)]
Damit finden Sie zum Beispiel "Produkt A1", "Produkt A23" usw. – praktisch bei Produktcodes oder Seriennummern.
Tipp: Bei sehr großen Datensätzen (> 100.000 Zeilen) verzichten Sie auf regex=True, wenn ein einfaches contains("wort") reicht. Das ist oft deutlich schneller.
Text ersetzen – str.replace()
Eine sehr häufige Aufgabe ist das Bereinigen oder Ändern von Texten.
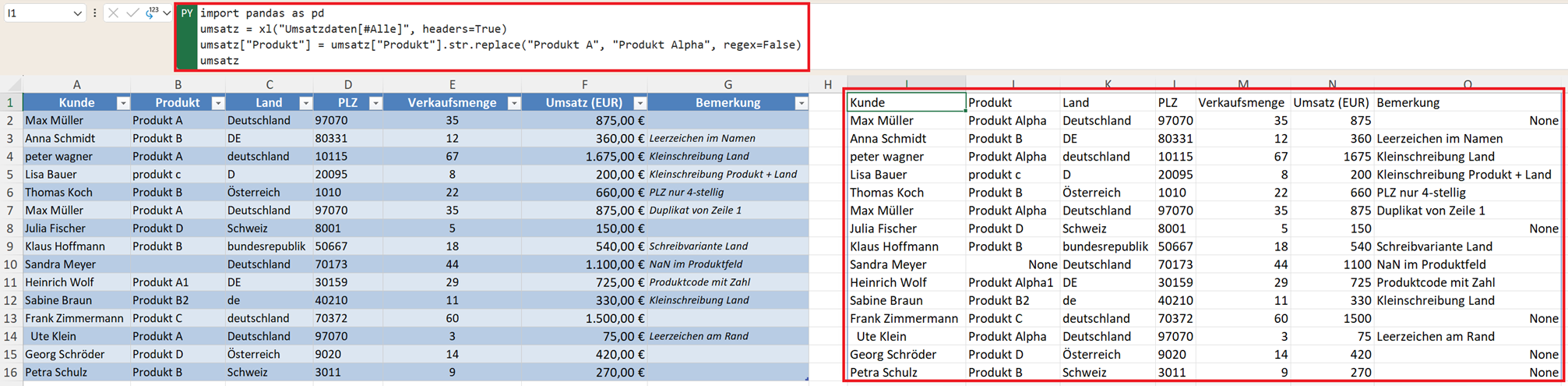
Beispiel: "Produkt A" in "Produkt Alpha" umbenennen
umsatz["Produkt"] = umsatz["Produkt"].str.replace("Produkt A", "Produkt Alpha", regex=False)
Damit werden alle Vorkommen von "Produkt A" durch "Produkt Alpha" ersetzt.
Hinweis: Ab Pandas 2.0 erwartet str.replace() einen expliziten Parameter regex=True oder regex=False. Ohne diesen Hinweis kann es zu einer Warnung kommen. Verwenden Sie daher immer regex=False, wenn Sie keinen regulären Ausdruck nutzen.
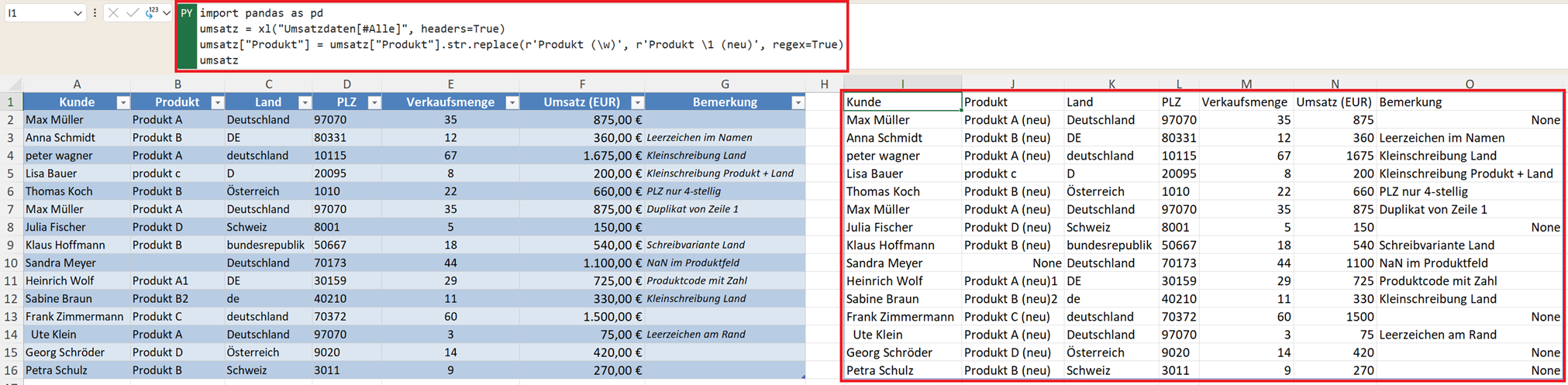
Auch str.replace() unterstützt reguläre Ausdrücke (mit regex=True):
umsatz["Produkt"] = umsatz["Produkt"].str.replace(r'Produkt (\w)', r'Produkt \1 (neu)', regex=True)
So können Sie Muster dynamisch ersetzen – ein echter Vorteil bei großen Datensätzen.
Leerzeichen entfernen – str.strip()
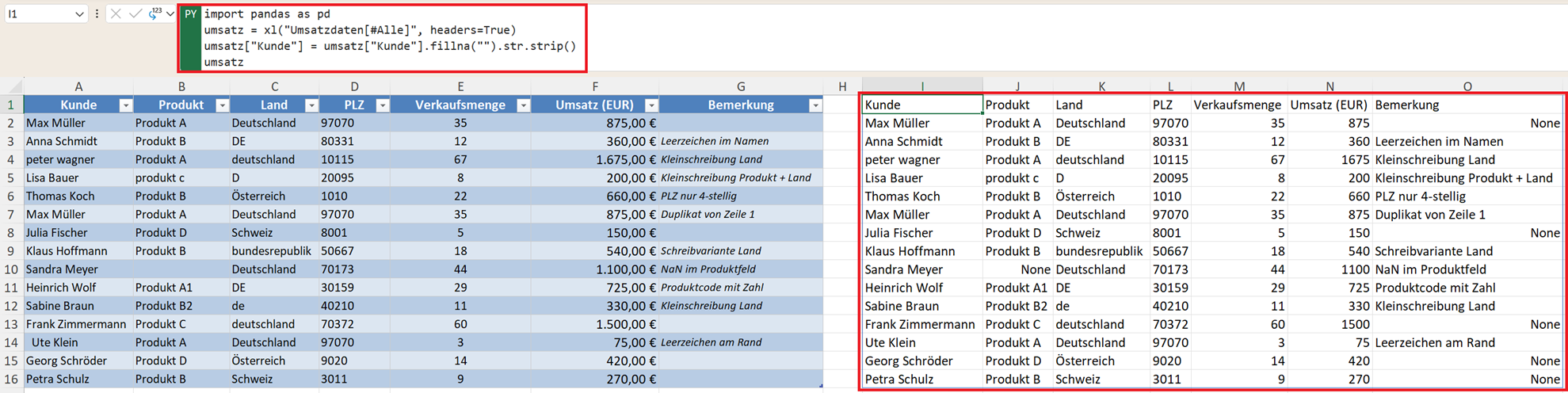
Ein klassisches Problem sind zusätzliche Leerzeichen. Mit diesem Befehl entfernen Sie führende und nachgestellte Leerzeichen.
umsatz["Produkt"] = umsatz["Produkt"].str.strip()
Tipp: Wenn Ihre Spalte NaN (leere Zellen) enthält, brechen str.strip(), str.replace() oder str.lower() manchmal ab. Sicherer ist es, vor der Bereinigung fillna("") zu verwenden:
umsatz["Produkt"] = umsatz["Produkt"].fillna("").str.strip()
Fehlende Werte prüfen mit isnull().sum()
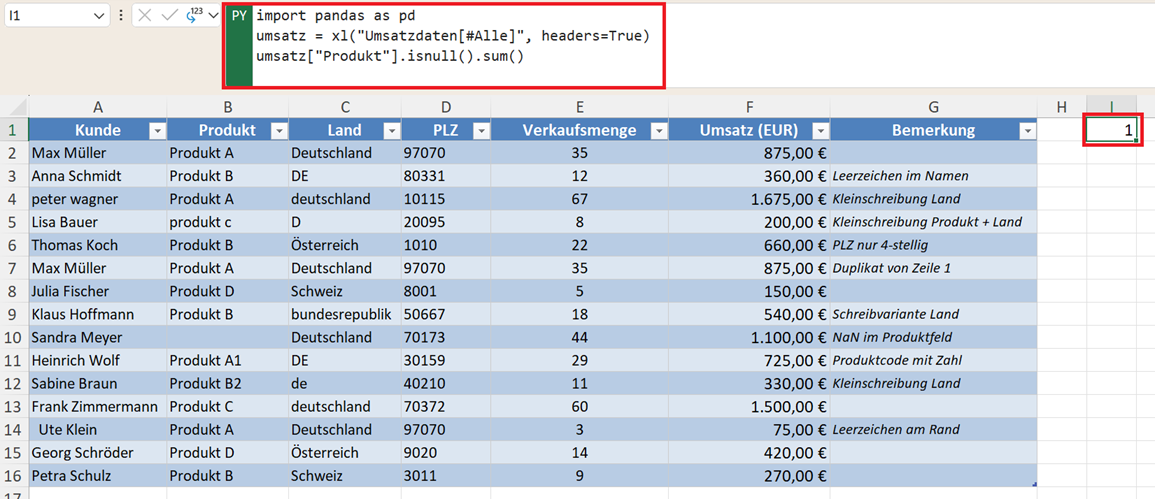
Immer sollten Sie prüfen, ob in Ihrem Datensatz Werte fehlen. Wie im folgenden Beispiel in der Spalte Produkt.
umsatz["Produkt"].isnull().sum()
So sehen Sie auf einen Blick, ob und wie viele NaN-Werte vorhanden sind – und können entscheiden, ob Sie diese mit fillna("") auffüllen oder gesondert behandeln möchten.
Hinweis: Mit isnull() ohne sum() erhalten Sie eine Liste mit WAHR- oder FALSCH-Angaben – je nachdem, wo Daten fehlen.
Einheitliche Schreibweise herstellen
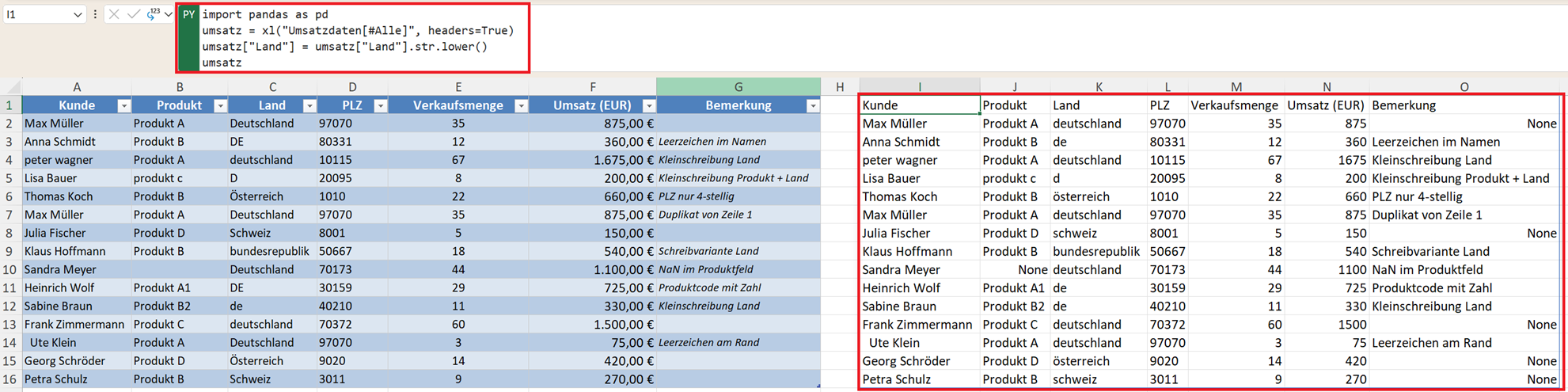
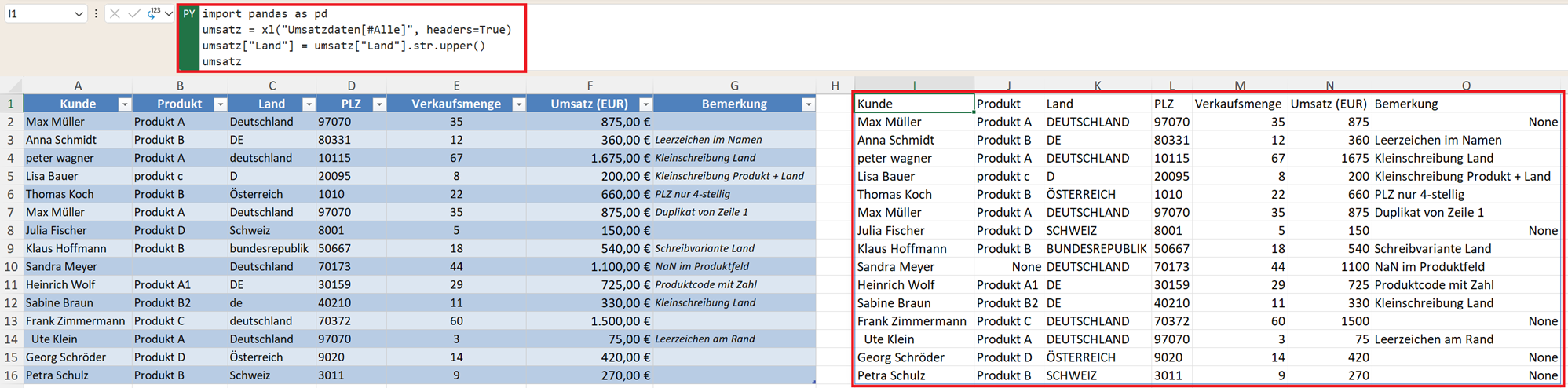
Oft müssen Texte vereinheitlicht werden. Mit str.lower() ändern Sie den Text vollständig in Kleinbuchstaben und mit str.upper() in Großbuchstaben.
umsatz["Land"] = umsatz["Land"].str.lower()
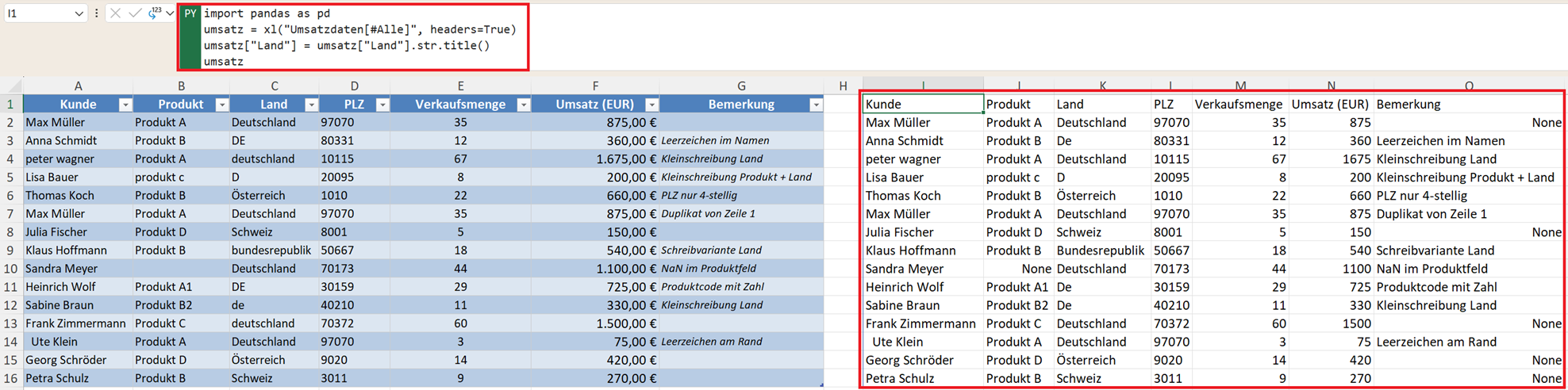
Mit str.title() formatieren Sie den Text so, dass der erste Buchstabe groß und die restlichen Buchstaben als Kleinbuchstaben ausgegeben werden. Damit vermeiden Sie doppelte Kategorien.
umsatz["Stadt"] = umsatz["Stadt"].str.title()
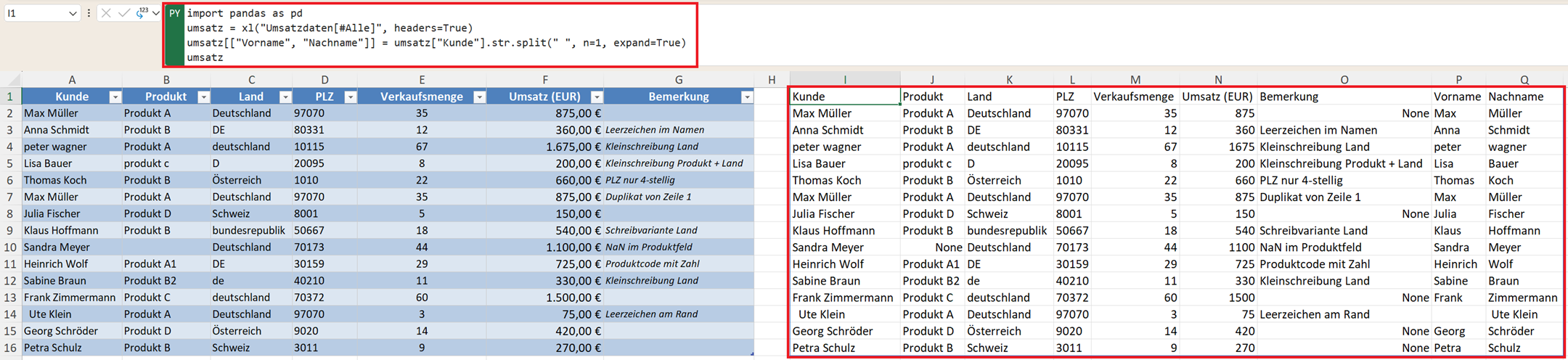
Text aufteilen – str.split()
Was in Excel Text in Spalten ist, erledigt Pandas mit str.split(). So können Sie beispielsweise Vorname und Nachname trennen.
umsatz[["Vorname", "Nachname"]] = umsatz["Kunde"].str.split(" ", n=1, expand=True)
Die Daten werden automatisch auf zwei neue Spalten verteilt. Der Parameter n=1 sorgt dafür, dass nur beim ersten Leerzeichen getrennt wird – das macht die Funktion robuster bei Doppelnamen oder mehreren Vornamen.
Hinweis: Achten Sie darauf, dass die Trennlogik eindeutig ist. Bei fehlenden Teilen kann das Ergebnis sonst unvollständig sein.
Kategorien bereinigen
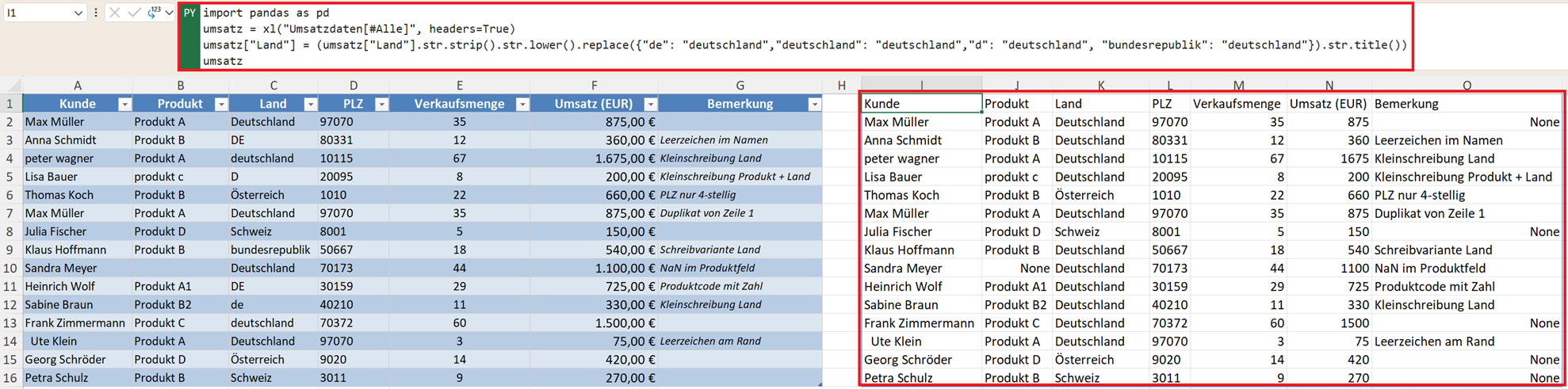
Mit dem folgenden Pandas-Befehl können Sie nun Ihren Text umfassend bereinigen. Beispiel: Sie wollen alle Länderschreibweisen vereinheitlichen. Angenommen, Ihr Datensatz enthält:
- Deutschland
- DE
- deutschland
- bundesrepublik
- D
Dann können Sie diese vereinheitlichen mit diesem Befehl:
umsatz["Land"] = (umsatz["Land"].str.strip().str.lower().replace({"de": "deutschland","deutschland": "deutschland","d": "deutschland", "bundesrepublik": "deutschland" }).str.title())
- Damit entfernen Sie zuerst die Leerzeichen mit str.strip().
- Dann wird der Text in Kleinbuchstaben geändert mit str.lower().
- Im nächsten Schritt werden die unterschiedlichen Schreibweisen vereinheitlicht mit replace(…).
- Und schließlich der erste Buchstabe zum Großbuchstaben geändert mit str.title().
Ergebnis: Einheitliche Schreibweise Deutschland.
Tipp: Immer zuerst .str.strip() und .str.lower() oder .str.upper() anwenden, bevor Sie mit replace() Kategorien vereinheitlichen – sonst bleiben Schreibweisen-Probleme bestehen. Das ist die sauberste Reihenfolge für solche Bereinigungsschritte.
Häufigkeiten von Texten analysieren
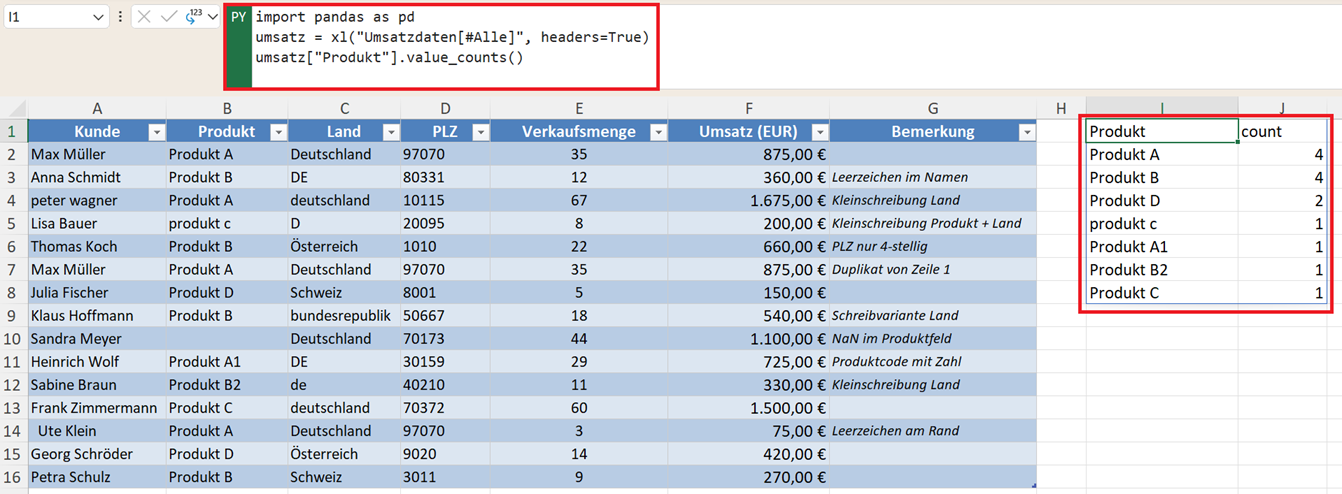
Sehr hilfreich für Kategorien ist der Befehl:
umsatz["Produkt"].value_counts()
Damit erkennen Sie häufig verkaufte Produkte und selten verkaufte Produkte.
Duplikate erkennen und entfernen
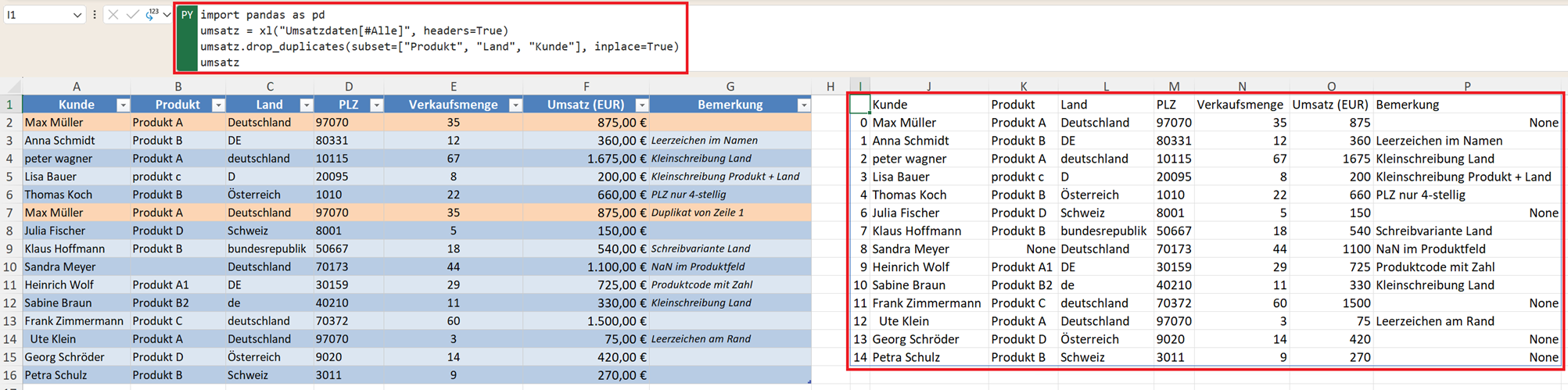
Oft schleichen sich doppelte Zeilen oder mehrfach genannte Kategorien ein. So können Sie Duplikate basierend auf mehreren Spalten löschen:
umsatz.drop_duplicates(subset=["Produkt", "Land", "Kunde"], inplace=True)
Das ist besonders wichtig, wenn Sie später aggregieren (zum Beispiel Summe pro Land).
Hinweis: Standardmäßig behält Pandas bei drop_duplicates() den ersten Treffer. Mit keep='last' behalten Sie den letzten Eintrag, mit keep=False entfernen Sie alle doppelten Vorkommen.
Encoding-Probleme
Ein in der Praxis häufig übersehenes Thema – besonders bei deutschen Texten: Encoding-Probleme. Umlaute (ä, ö, ü) oder Sonderzeichen können beim Einlesen von CSV-Dateien zu unleserlichen Zeichen führen.
Beim Laden einer Datei sollten Sie daher immer die Codierung mit encoding=… angeben:
import pandas as pd
umsatz = pd.read_csv("datei.csv", encoding="utf-8")
Oder bei älteren Windows-Dateien:
umsatz = pd.read_csv("datei.csv", encoding="latin1")
Tipp: Wenn Sie seltsame Zeichen wie "ü" statt "ü" sehen, ist das ein typisches Zeichen für ein Encoding-Problem. In den meisten Fällen hilft encoding="utf-8" oder encoding="latin1".