Power Pivot – DAX-Measures erstellen und anwendenPower Pivot: Performance und Best Practices in DAX
Wenn DAX langsam wird …
Wenn Sie intensiv mit Power Pivot arbeiten, wird Ihr Datenmodell mit der Zeit komplexer. Neue Tabellen, viele Measures, Beziehungen, Filter und Time-Intelligence-Funktionen kommen hinzu – und plötzlich dauert das Neuberechnen von Pivot-Tabellen merklich länger.
Diese Verlangsamung hat selten etwas mit Excel selbst zu tun, sondern fast immer mit ineffizienten DAX-Formeln oder einer nicht optimalen Modellstruktur.
Um zu verstehen, wie man DAX-Performance optimiert, muss man wissen, wie Power Pivot intern arbeitet.
Wie DAX und VertiPaq „denken“
Die Engine hinter Power Pivot heißt VertiPaq – sie ist spaltenbasiert und speichert Daten hochkomprimiert im Arbeitsspeicher. Das ist der Grund, warum DAX-Modelle mit Millionen von Zeilen immer noch blitzschnell aggregieren können.
Das Prinzip: VertiPaq komprimiert jede Spalte separat, ähnlich wie eine Datenbank. Je weniger unterschiedliche Werte eine Spalte enthält, desto stärker kann sie komprimiert werden. Deshalb sind Zahlen und IDs sehr effizient, während lange Texte Performance kosten.
Beispiel:
- Eine Spalte „Produktkategorie“ mit 5 möglichen Werten wird fast perfekt komprimiert.
- Eine Spalte „Produktname“ mit 10.000 unterschiedlichen Werten braucht dagegen mehr Speicher und verlängert die Zeit für die Verarbeitung.
Das bedeutet: DAX ist nicht langsam – falsch modellierte Daten sind es.
Grundprinzip: Denken in Spalten, nicht in Zeilen
Power Pivot ist spaltenorientiert, während Excel zeilenorientiert rechnet. Das ist der wichtigste mentale Umstieg.
In Excel: Jede Zelle wird einzeln berechnet.
In DAX: Eine Formel wie SUM(t_Bestellungen[Menge]) wird über eine komprimierte Spalte ausgeführt – die Engine summiert Millionen Werte, ohne jede Zeile einzeln zu betrachten.
Aber sobald Sie SUMX() oder FILTER() verwenden, muss DAX Zeile für Zeile iterieren – und das kostet Zeit.
Beispiel:
Umsatz_Langsam:= SUMX(t_Bestellungen; t_Bestellungen[Menge] * t_Bestellungen[Einzelpreis])
Diese Formel zwingt DAX, jede Zeile zu berechnen (Iteration). Wenn Sie dagegen eine Spalte Umsatz im Modell haben, reicht:
Umsatz_Schnell:= SUM(t_Bestellungen[Umsatz])
Das ist mehrfach schneller, weil VertiPaq spaltenbasiert aggregiert. Iterative Funktionen (X-Funktionen) sind also mächtig, aber aufwendig. Verwenden Sie diese DAX-Funktionen nur, wenn Sie wirklich eine Berechnung pro Zeile benötigen.
CALCULATE – das Herzstück von DAX, aber auch die Hauptbremse
CALCULATE() verändert den Filterkontext und ist damit die wichtigste, aber auch aufwendigste Funktion in DAX. Sie braucht Rechenleistung.
Bei jedem CALCULATE()-Aufruf muss die Engine den Kontext neu aufbauen.
Effizient ist die gleichzeitige Filterung:
Umsatz_Filter-DE_V1:= CALCULATE([Umsatz]; Kalendertabelle[Jahr] = 2024; t_Kunden[Land] = "Deutschland")
Ineffizient ist die verschachtelte Filterung:
Umsatz_Filter-DE_V2:= CALCULATE(CALCULATE([Umsatz]; Kalendertabelle[Jahr] = 2024); Kunden[Land] = "Deutschland")
Mehrere CALCULATE()-Verschachtelungen bedeuten mehrere Kontextwechsel. Besser ist eine kompakte Variante mit mehreren Filterargumenten.
Measure-Gruppen – Ordnung im Kennzahlen-Dschungel
Mit zunehmender Modellgröße werden Ihre Measures schnell unübersichtlich. Erstellen Sie daher eine eigene Tabelle (zum Beispiel t_Measures), in der alle Measures zentral gespeichert werden.
So geht’s:
- Erstellen Sie in Excel eine Mini-Tabelle mit einer Dummy-Spalte (zum Beispiel „1“).
- Laden Sie diese Tabelle ins Datenmodell.
- Legen Sie alle neuen Measures in dieser Tabelle ab.
Das hat mehrere Vorteile:
- Saubere Trennung zwischen Daten und Kennzahlen
- Einheitliche Logik an einer Stelle
- Einfacheres Auffinden Ihrer Measures in der Feldliste
- Schnelleres Kopieren und Vergleichen zwischen Modellen
Tipp: Benennen Sie Measures konsistent, zum Beispiel:
- Umsatz_Gesamt
- Umsatz_Vorjahr
- Umsatz_Wachstum
- Umsatz_ProKunde
So bleibt das Modell logisch und für andere verständlich.
Berechnete Spalten – sinnvoll, aber mit Vorsicht
Berechnete Spalten werden dauerhaft gespeichert, jede Zeile belegt also Speicherplatz.
Regel: Wenn Sie eine Spalte nur anlegen, um sie später zu summieren, erstellen Sie stattdessen ein Measure.
Falsch wäre eine neue Spalte mit der Berechnung:
Umsatz_Spalte = t_Bestellungen[Menge] * t_Bestellungen[Einzelpreis]
Richtig ist, ein Measure zu definieren:
Umsatz:= SUMX(t_Bestellungen; t_Bestellungen[Menge] * t_Bestellungen[Einzelpreis])
Hintergrund: Measures werden on demand berechnet – also nur, wenn sie gebraucht werden. Spalten dagegen immer im Speicher gehalten. Das spart bei großen Modellen massiv Speicherplatz und Ladezeit.
Datenreduktion – das A und O bei großen Modellen
Power Pivot liebt kleine, saubere Tabellen. Je weniger Daten geladen werden, desto schneller rechnet DAX.
Optimierungsstrategien:
- Nicht benötigte Spalten löschen. Jede Spalte kostet Speicherplatz, auch wenn sie nicht genutzt wird.
- Vorfilter in Power Query setzen. Laden Sie zum Beispiel nur die letzten 5 Jahre statt aller historischen Daten.
- Datentypen prüfen. Zahlen → Ganze Zahl, Texte → möglichst wenige eindeutige Werte.
- IDs statt Namen verwenden. ProduktID komprimiert sich besser als „Produktname“.
Tipp: Mit „Power Query → Spalten entfernen“ sparen Sie Speicher vor dem Laden – das ist effizienter als Ausblenden im Modell.
Beispiel: Komplexes Measure optimieren
Dieses DAX-Measure:
Produkte_Top-5_V1:= CALCULATE([Umsatz]; KEEPFILTERS(TOPN(5; ALL(t_Produkte[ProduktName]); [Umsatz]; DESC)))
Führt zu dem Problem: TOPN() muss die gesamte Produkttabelle durchlaufen, was bei vielen Artikeln aufwendig ist.
Deshalb wird das DAX-Measure optimiert:
Produkte_Top-5_V2:= CALCULATE([Umsatz]; KEEPFILTERS(TOPN(5; FILTER(ALL(t_Produkte); t_Produkte[Aktiv] = TRUE()); [Umsatz]; DESC)))
Hier wird vor der Sortierung gefiltert – weniger Zeilen, schnellere Berechnung.
Analysewerkzeuge und Fehlersuche
In Power BI Desktop (gleiche Engine wie Power Pivot) finden Sie den Performance Analyzer. Er zeigt:
- wie lange jedes Measure braucht,
- welche Abfragen besonders rechenintensiv sind und
- welche Tabellen am meisten Zeit kosten.
So können Sie Engpässe erkennen, bevor Ihr Modell zu langsam wird.
In Excel selbst bleibt nur das iterative Testen – zum Beispiel komplexe Measures in Teilformeln aufbrechen und Zwischenergebnisse prüfen.
Best Practices für nachhaltige DAX-Performance
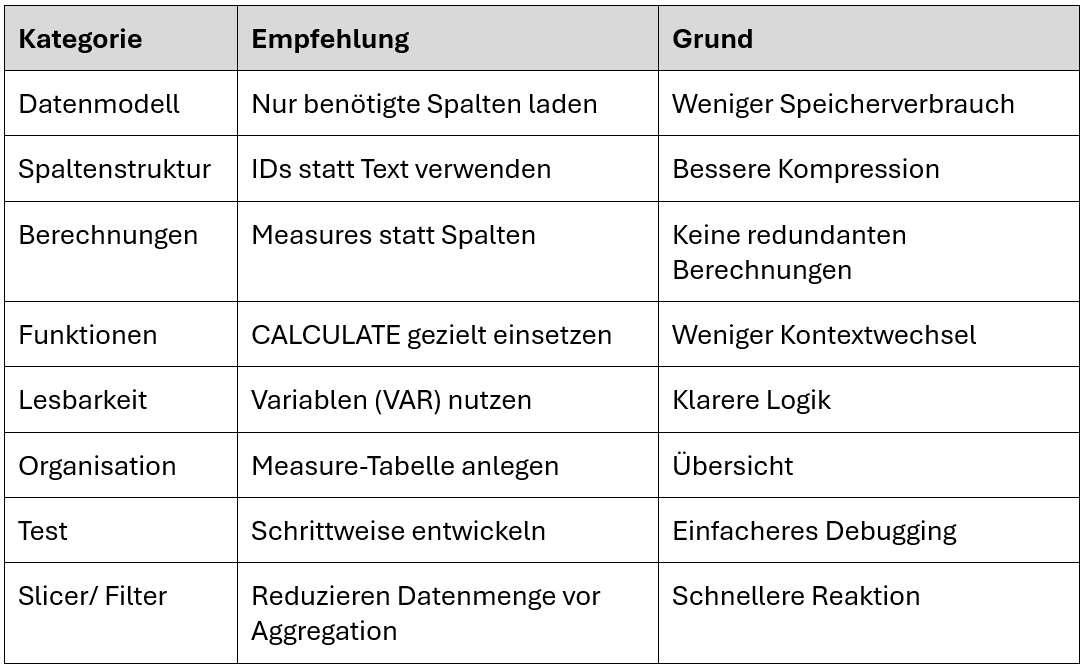
DAX-Performance = Modellierungs-Intelligenz
Die beste Performance entsteht nicht durch Tricks, sondern durch konzeptionelle Klarheit:
- saubere Beziehungen,
- logische Measures,
- minimale Redundanz.
Je klarer das Modell, desto weniger muss DAX „nachdenken“. Ein sauberes, durchdachtes Modell ist die halbe Optimierung.
Fazit
DAX-Performance ist keine Frage von Hardware, sondern von Denkweise:
- Denken Sie spaltenbasiert statt zeilenorientiert.
- Nutzen Sie Measures statt Spalten.
- Reduzieren Sie Komplexität und Datenvolumen frühzeitig in Power Query.
- Verwenden Sie Variablen für klare Logik und Wiederverwendung.
- Und testen Sie regelmäßig, ob Ihre Formeln wirklich effizient rechnen.
Wenn Sie diese Prinzipien beherzigen, können Sie auch mit Millionen Datensätzen flüssige, interaktive Dashboards erstellen – direkt in Excel.
Demo-Daten für Power Pivot und DAX-Measures
In der folgenden Excel-Vorlage sind alle vorgestellten DAX-Measures eingerichtet. Sie finden dazu in der Vorlage:
- die Übersicht (Menü) mit Links zu den jeweiligen Musteranalysen und DAX-Measures sowie
- einer Verlinkung auf die Anleitungen zu den jeweiligen DAX-Measures,
- Musterdaten für Kunden, Produkte und Bestellungen,
- eine Kalendertabelle für die Zeitanalyse und die Time-Intelligence-Funktionen,
- alle definierten DAX-Measures in einer gesonderten Tabelle des Datenmodells: t_Measures
- eine Auswahl von Pivot-Tabellen als Grundlage für das Beispiel-Dashboard und
- ein Dashboard, in dem beispielhaft ausgewählte Pivot-Tabellen und die hinterlegten DAX-Measures als Chart oder KPI-Karte aufbereitet sind.
Nutzen Sie diese Vorlage, um sich mit den DAX-Measures und den Excel-Funktionen vertraut zu machen. Sie können diese Funktionsvorlagen nutzen und für Ihre Daten leicht anpassen.
Mit den Anleitungen und Beschreibungen auf business-wissen.de erarbeiten Sie Schritt für Schritt Ihr eigenes Datenmodell und die für Sie passenden DAX-Measures.
So machen Sie sich schnell mit den umfassenden Möglichkeiten von Power Pivot vertraut.