Python in Excel – erste Schritte und BerechnungenArchitektur, Arbeitsweise und technische Grundlagen für Python und Excel
- Ein praxisnaher Einstieg
- Was passiert technisch bei =PY()?
- Wo wird der Python-Code ausgeführt?
- Sicherheit und Datenschutz
- Unterschied zur klassischen Excel-Berechnungslogik
- Warum dieses Architekturverständnis entscheidend ist
- Bibliotheken in Python in Excel – Was ist bereits vorhanden?
- Excel-Daten mit xl() übergeben – Arbeiten mit der Beispieldatei
Ein praxisnaher Einstieg
Stellen Sie sich folgende Situation vor: Sie erhalten aus dem ERP-System eine Datei mit 250.000 Verkaufspositionen. Ziel ist es, für das Management kurzfristig folgende Fragen zu beantworten:
- Wie hoch ist der Umsatz je Region?
- Welche Produktgruppe erzielt den höchsten Deckungsbeitrag?
- Wo liegen die größten Abweichungen zum Vormonat?
In Excel würden Sie:
- eine oder mehrere Pivot-Tabellen erstellen,
- Hilfsspalten für Berechnungen anlegen,
- Formeln kopieren und
- Diagramme erstellen.
Das funktioniert, solange die Datenmenge überschaubar ist und der Prozess nicht regelmäßig wiederholt werden muss. Doch was passiert, wenn
- die Datenmenge wächst,
- die Berechnungslogik komplexer wird,
- der Report monatlich automatisiert erzeugt werden soll oder
- statistische Verfahren ins Spiel kommen?
Genau hier setzt Python in Excel an. Python erweitert Excel um eine strukturierte Analyse-Engine im Hintergrund. Das bedeutet:
- Berechnungen erfolgen nicht mehr zellenweise, sondern spaltenweise und tabellenbasiert.
- Prozesse werden reproduzierbar.
- Logik wird explizit definiert – nicht implizit über Zellbezüge.
Was passiert technisch bei =PY()?
Wenn Sie in Excel eine normale Formel eingeben, zum Beispiel: =SUMME(A1:A10), berechnet Excel das Ergebnis direkt lokal auf Ihrem Rechner. Die Berechnungslogik ist zellenbasiert, Excel löst globale Abhängigkeiten auf und speichert den Wert in der Zielzelle.
Bei Python in Excel funktioniert das grundlegend anders. Wenn Sie mit Python arbeiten und in einer Excel-Zelle schreiben:
=PY()
erstellen Sie keine klassische Excel-Formel, sondern eine Python-Ausführungszelle, einen Codeblock.
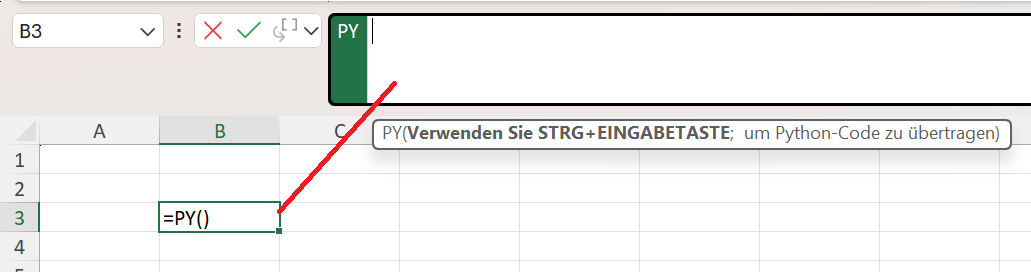
Diese Zelle:
- enthält später einen vollständigen Python-Codeblock,
- führt alle enthaltenen Anweisungen aus und
- gibt das letzte Ergebnis an Excel zurück.
Eine Python-Zelle ist damit eher vergleichbar mit einem kleinen Skript als mit einer einzelnen Zellformel. Innerhalb einer einzigen Zelle können Sie mehrere Schritte definieren:
- Daten einlesen
- Berechnungen durchführen
- Daten aggregieren
- Ergebnis strukturieren
Das ist konzeptionell ein großer Unterschied zur klassischen Excel-Logik.
Wo wird der Python-Code ausgeführt?
Das ist ein zentraler Punkt – besonders für Unternehmen. Der Code läuft nicht lokal auf Ihrem Rechner, sondern in einer isolierten Cloud-Umgebung auf Microsoft Azure. Der technische Ablauf ist:
- Sie schreiben Python-Code in Excel.
- Excel sendet diesen Code an eine Azure-Container-Umgebung.
- Der Code wird dort in einer isolierten Sandbox ausgeführt.
- Das Ergebnis wird an Excel zurückgesendet.
- Excel zeigt das Ergebnis als Tabelle oder Objekt an.
Sicherheit und Datenschutz
Gerade im Controlling-Umfeld ist das wichtig. Die Python-Ausführung erfolgt:
- in einer isolierten Container-Umgebung,
- ohne Zugriff auf Ihr lokales Dateisystem,
- ohne Zugriff auf Ihr Unternehmensnetzwerk und
- ohne direkten Internetzugriff.
Das bedeutet: Python in Excel kann keine lokalen Dateien manipulieren und nicht auf interne Systeme zugreifen.
Dennoch gilt: Wenn sensible oder personenbezogene Daten verarbeitet werden, sollte die Nutzung von Python mit IT und Datenschutz abgestimmt werden – insbesondere in regulierten Branchen.
Unterschied zur klassischen Excel-Berechnungslogik
Ein weiterer wichtiger Unterschied betrifft die Denkweise. Excel arbeitet zellenbasiert und mit globaler Abhängigkeitsauflösung. Python in Excel arbeitet blockbasiert und in klar definierten Ausführungseinheiten.
Eine Python-Zelle kann nicht „nachträglich“ auf eine weiter unten liegende Python-Zelle zugreifen, wenn diese noch nicht berechnet wurde.
Python-Zellen werden in Excel nach folgendem Prinzip berechnet: Von links nach rechts und von oben nach unten. Das nennt sich Row-Major Order. Das ist wichtig für den strukturellen Aufbau von Modellen.
Warum dieses Architekturverständnis entscheidend ist
Wenn Sie Python in Excel nutzen, wechseln Sie von impliziter Zelllogik zu expliziter Datenlogik. Sie definieren klar:
- welche Daten verwendet werden
- welche Schritte ausgeführt werden
- welches Ergebnis zurückgegeben wird
Das erhöht die Nachvollziehbarkeit, Reproduzierbarkeit und Skalierbarkeit. Ein Python-Code mit =PY() ist daher nicht einfach eine neue Formel – sondern der Einstieg in eine neue Rechenarchitektur innerhalb von Excel.
Bibliotheken in Python in Excel – Was ist bereits vorhanden?
Eine Bibliothek in Python ist eine Sammlung von fertigem Code, den andere bereits geschrieben haben, damit man das Rad nicht neu erfinden muss.
Excel-User können diese Sammlungen einfach in ihr Programm importieren, um komplexe Aufgaben wie das Erstellen von Grafiken oder Berechnungen mit nur wenigen Befehlen zu erledigen.
Man kann sie sich wie einen Werkzeugkasten vorstellen, aus dem Nutzer für jedes Projekt genau das passende Spezialwerkzeug herausnehmen.
Vorinstallierte Bibliotheken in der Microsoft-Umgebung
Eine der häufigsten Fragen beim Einstieg lautet: „Muss ich Python oder zusätzliche Pakete erst installieren?“ Die Antwort lautet: Nein.
Python in Excel läuft in einer von Microsoft bereitgestellten Cloud-Umgebung. Dort sind die wichtigsten Analysebibliotheken bereits installiert. Dazu gehören insbesondere:
- pandas: Tabellen- und Datenanalyse
- numpy: numerische Berechnungen
- matplotlib: Diagramme
- seaborn: erweiterte Visualisierungen
- statsmodels: statistische Verfahren
Das bedeutet: Sie müssen diese Pakete nicht manuell installieren und keine Abhängigkeiten verwalten.
Die bereits importierten Bibliotheken können Sie sich in Excel anzeigen lassen, indem Sie im Menüband den Befehl Registerkarten Formel > Befehl Python (Vorschau) > Befehl Initialisierung ausführen.
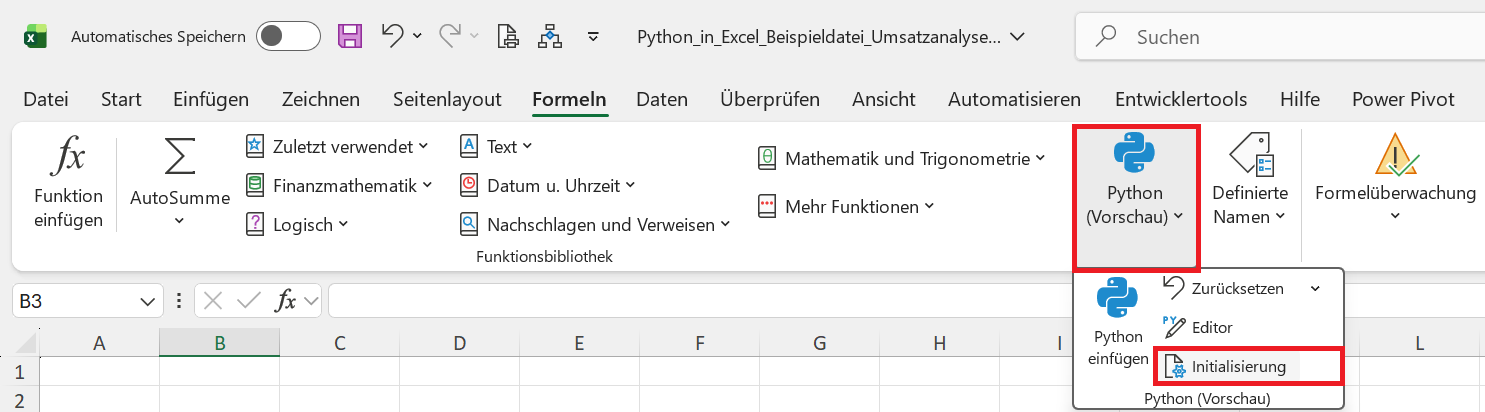
Sie bekommen daraufhin am rechten Rand den Aufgabenbereich Initialisierung angezeigt. Hier können Sie die automatisch importierten Bibliotheken einsehen.
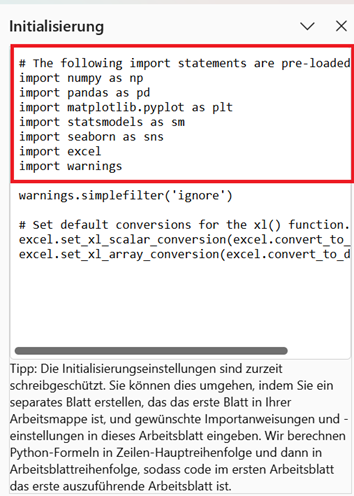
Warum sollten Sie „import pandas as pd“ schreiben?
Das müssen Sie grundsätzlich nicht machen, da die Pandas-Bibliothek standardmäßig von Excel importiert wird. Es gibt jedoch drei wichtige Gründe, warum es trotzdem gute Praxis ist:
1. Transparenz und Lesbarkeit
Wenn Sie das Excel-Dokument an jemanden schicken oder es nach drei Monaten selbst wieder öffnen, sehen Sie oben sofort in der Zelle: „Ah, hier wird mit Pandas gearbeitet.“ Ohne den expliziten Import müsste man erst im Initialisierungsmenü nachsehen, welche Werkzeuge überhaupt aktiv sind.
2. Kompatibilität (Copy & Paste)
Wenn Sie Ihren Code später außerhalb von Excel nutzen möchten – zum Beispiel in einem anderen Python-Editor wie Jupyter Notebook oder VS Code –, wird der Code dort nicht funktionieren, wenn das „import pandas as pd“ fehlt. Mit der Angabe bleibt der Code portabel.
3. Versionskontrolle und Eindeutigkeit
In der Initialisierung legt Excel fest, welche Version von Pandas genutzt und welches Kürzel (Alias) verwendet wird. Schreiben Sie es selbst, dann haben Sie die volle Kontrolle und stellen sicher, dass genau das passiert, was Sie erwarten.
Unterschied zur lokalen Python-Installation
Wenn Sie Python lokal auf Ihrem Rechner installieren, müssen Sie:
- Python selbst installieren
- Pakete mit pip install nachladen
- Versionen verwalten
- Abhängigkeiten prüfen
Bei Python in Excel entfällt dieser gesamte Aufwand. Das ist insbesondere für Excel-User in Unternehmen mit einer zentralen IT und getrenntem Admin attraktiv. Es sind keine Installationsrechte notwendig und die Umgebung ist für alle Nutzer einheitlich.
Grenzen der vorinstallierten Umgebung
Sie können keine beliebigen externen Pakete nachinstallieren. Sie sind auf die Pakete angewiesen, die Microsoft über die Anaconda-Distribution bereitstellt (das sind allerdings über 400 der gängigsten Bibliotheken für Datenanalyse).
Die Umgebung ist kontrolliert und abgesichert. Python läuft nicht direkt auf Ihrem Computer, sondern in einer isolierten Schüssel (Container) in der Microsoft Azure Cloud. Das verhindert, dass ein Python-Skript versehentlich (oder absichtlich) auf private Dateien oder das lokale Netzwerk zugreift.
Internetzugriffe sind eingeschränkt. Der Python-Code in Excel kann keine Daten von beliebigen Webseiten nachladen oder E-Mails verschicken. Das ist ein wichtiger Schutzmechanismus für Unternehmen (Governance), damit keine sensiblen Firmendaten unkontrolliert nach außen abfließen
Das ist bewusst so gestaltet – aus Sicherheits- und Governance-Gründen. Für klassische Controlling- und Analyseaufgaben sind die vorhandenen Bibliotheken jedoch mehr als ausreichend.
Excel-Daten mit xl() übergeben – Arbeiten mit der Beispieldatei
Für die folgenden Erläuterungen gibt es eine Excel-Datei mit einem Tabellenblatt: Umsatzdaten. Dort gibt es die Daten zu:
- Region
- Produktgruppe
- Umsatz
- Kosten
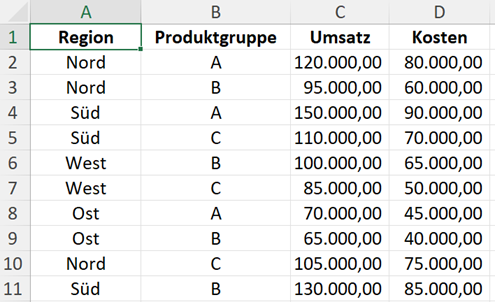
Daten korrekt an Python übergeben
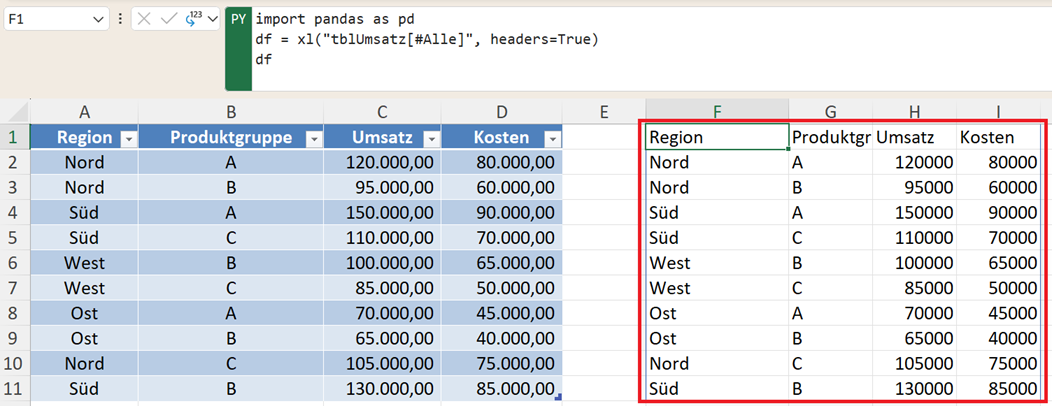
Angenommen, die Tabelle steht im Bereich A1:D11 und Sie wollen die Daten an eine Excel-Python-Zelle übergeben. Dann schreiben Sie den folgenden Code in die Python-Zelle (F1):
import pandas as pd
df = xl("A1:D11", headers=True)
df
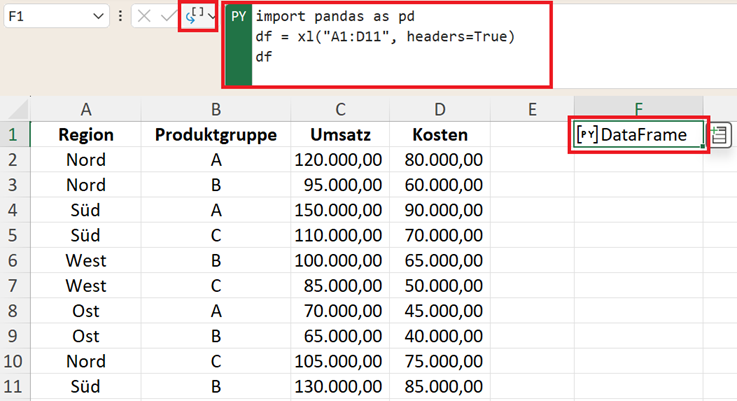
Warum headers=True wichtig ist
Standardmäßig versucht Excel zu erkennen, ob die erste Zeile Überschriften enthält. Sicher ist es jedoch, dies explizit zu definieren:
df = xl("A1:D11", headers=True)
Dadurch wird Zeile 1 als Spaltenname interpretiert und damit ist df["Umsatz"] korrekt möglich. Zudem werden keine numerischen Default-Spalten erzeugt. Explizite Definition ist in Python grundsätzlich Best Practice.
Noch robuster: Arbeiten mit Tabellenobjekten
Besser als feste Zellbereiche ist die Referenzierung einer formatierten Excel-Tabelle. Wenn Sie die Daten als Tabelle formatieren (Strg + T) und beispielsweise „tblUmsatz“ nennen, können Sie schreiben:
df = xl("tblUmsatz[#Alle]", headers=True)
Vorteile:
- automatische Erweiterung bei neuen Zeilen
- kein Anpassen des Zellbereichs
- stabiler Code bei wachsenden Daten
Was ist mit df = xl() passiert?
Mit:
df = xl("tblUmsatz[#Alle]", headers=True)
haben Sie:
- Excel-Daten in einen DataFrame überführt,
- eine strukturierte, spaltenorientierte Datenstruktur erzeugt und
- die Grundlage für alle weiteren Berechnungen gelegt.
Ab diesem Punkt denken Sie nicht mehr in einzelnen Zellen – sondern in Tabellenobjekten.
Mit df geben Sie die eingelesenen Daten wieder in der Python-Zelle F1 aus. Der ausgegebene Code wird im ersten Schritt in einem Python-Objekt (Datenframe) ausgegeben und ist somit auf den ersten Blick nicht sichtbar.
Sie können die Daten direkt im Excel-Blatt visuell zurückgeben lassen, indem Sie die Python-Zelle F1 markieren.
Klicken Sie in der Bearbeitungsleiste auf das Wechsel-Symbol, das sich direkt links neben dem PY befindet. Wählen Sie hier den Eintrag Excel-Wert aus.
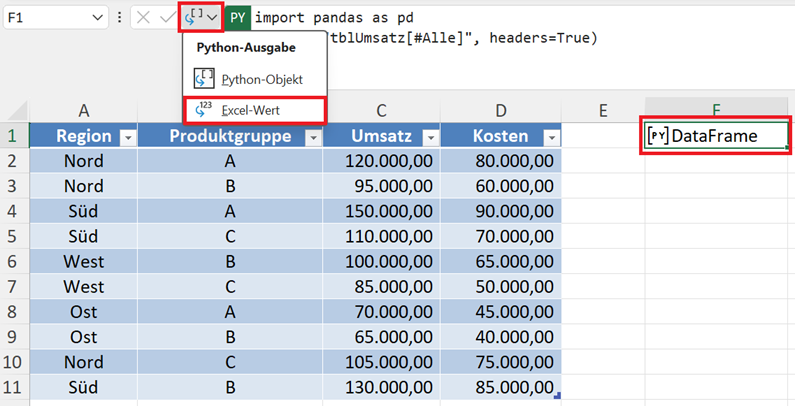
Die Daten des DataFrames werden jetzt direkt in das Tabellenblatt geschrieben. Sie können den Inhalt des Datenframes direkt im Excelblatt einsehen.