Power Pivot – Wichtige FunktionenDie besten Ergebnisse finden mit der DAX-Funktion TOPN()
Wofür die DAX-Funktion TOPN() eingesetzt wird
Im Controlling geht es selten darum, alles zu sehen – sondern darum, die wichtigsten Daten oder Merkmale herauszufiltern. Zum Beispiel:
- Welche fünf Produkte machen 80 % des Umsatzes aus?
- Wer sind Ihre Top-10-Kunden des Jahres?
- Welche Regionen tragen am stärksten zum Gesamtergebnis bei?
Mit der DAX-Funktion TOPN() können Sie solche Fragen gezielt beantworten. Sie hilft Ihnen, die besten oder schlechtesten Datensätze aus einem Datenmodell zu extrahieren – und das dynamisch, filterabhängig und in Echtzeit.
In diesem Beitrag erfahren Sie Schritt für Schritt, wie TOPN() funktioniert, welche Besonderheiten es gibt und wie Sie diese Funktion im Controlling einsetzen.
Was macht TOPN()?
Die Funktion TOPN() filtert eine Tabelle so, dass nur die obersten oder untersten n Zeilen nach einer bestimmten Kennzahl (zum Beispiel Umsatz, Gewinn, Absatzmenge) zurückgegeben werden. Sie können sich TOPN() vorstellen wie eine intelligente Sortiermaschine.
Sie sortiert Ihre Tabelle nach einem gewünschten Wert und behält nur die ersten n Einträge.
Beispiele:
- Zeige mir die 5 Produkte mit dem höchsten Umsatz
- Liste die 10 umsatzstärksten Kunden in Deutschland auf
Der Clou: TOPN() arbeitet dynamisch – Filter, Datenschnitte oder Zeiträume in Ihrer Pivot-Tabelle werden automatisch berücksichtigt.
Syntax von TOPN():
TOPN(n_value; Tabelle; SortBy_Expression; SortOrder)
Die Parameter bedeuten:
- n_value: Anzahl der Zeilen (Top-Werte), die Sie zurückgeben möchten (zum Beispiel 2, 5 oder 10).
- Tabelle: Tabelle, aus der gefiltert werden soll (zum Beispiel t_Produkte).
- SortBy_Expression: Der Ausdruck oder das Measure, nach dem sortiert wird (zum Beispiel [Umsatz]).
- SortOrder (optional): Sortierreihenfolge: DESC für absteigend (Standard) oder ASC für aufsteigend.
Beispiel 1 – Top 2 Produkte nach Umsatz
Angenommen, Sie möchten die zwei umsatzstärksten Produkte in Ihrem Datensatz ermitteln. Das dafür notwendige Measure für die Berechnung des Umsatzes lautet:
Umsatz:= SUMX(t_Bestellungen; t_Bestellungen[Menge] * RELATED(Produkte[Einzelpreis]))
Das Measure für die Top-2-Produkte:
t_Top2_Produkte:= TOPN(2; VALUES(t_Produkte[ProduktName]); [Umsatz]; DESC)
Erklärung:
- 2 → gibt an, dass Sie die Top-2-Zeilen möchten.
- VALUES(t_Produkte[ProduktName]) → erzeugt eine Liste aller Produkte mit dem Produktnamen
- [Umsatz] → ist die Kennzahl, nach der sortiert wird
- DESC → sorgt dafür, dass das Ranking nach absteigendem Umsatz erfolgt; höchster Umsatz = Top 1
Das Ergebnis ist eine Tabelle mit den zwei umsatzstärksten Produkten. Allerdings können Sie dieses Measure so nicht in einer Pivot-Tabelle einsetzen, da eine Pivot-Tabelle einen Wert und nicht eine Auflistung von Werten in der Werte-Spalte erwartet.
Sie können diese Tabelle aber mit CALCULATE() einbetten, um die Werte weiter zu analysieren oder in Pivot-Tabellen zu visualisieren. Dazu nutzen Sie beispielsweise folgende DAX-Formel:
Top2_Produkte:= CALCULATE([Umsatz]; KEEPFILTERS( TOPN(2; ALL(t_Produkte[ProduktName]); [Umsatz]; DESC)))
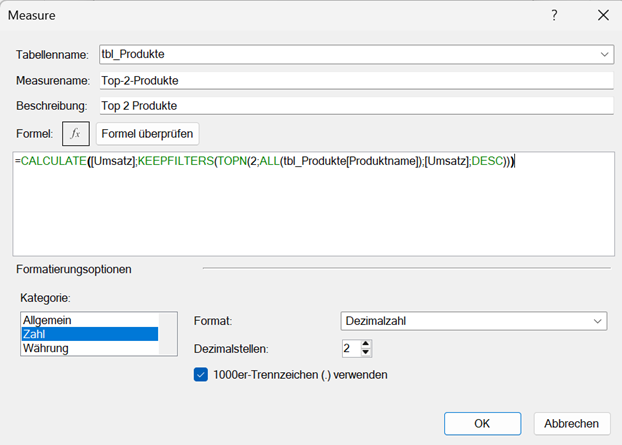
Dieses Measure berechnet den Gesamtumsatz der zwei umsatzstärksten Produkte im gesamten Datenmodell – unabhängig davon, welche Produkte in der Pivot-Tabelle oder im Bericht ausgewählt sind.
Es ist somit ideal für Top-N-Analysen und Pareto-Betrachtungen im Controlling, etwa um zu ermitteln, welchen Anteil die zwei erfolgreichsten Produkte am Gesamtumsatz haben.
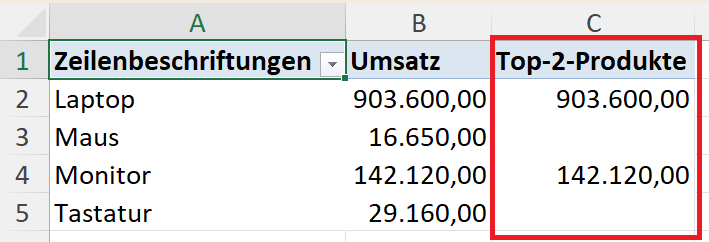
Schritt-für-Schritt-Erklärung
Äußerste Funktion: CALCULATE() ist das Herzstück vieler DAX-Berechnungen. Sie verändert den Filterkontext, bevor eine Berechnung ausgeführt wird.
Hier sorgt sie dafür, dass das Measure [Umsatz] nicht über alle Produkte, sondern nur über die Top-2-Produkte summiert wird.
Hinweis: CALCULATE() „denkt um“ – es berechnet einen Ausdruck (hier: [Umsatz]) unter einem veränderten Filterkontext. Lesen Sie hier mehr zur DAX-Funktion CALCULATE und ihren Filtern.
Filterargument: KEEPFILTERS() bewirkt, dass bestehende Filter beibehalten und ergänzt werden, statt sie komplett zu überschreiben.
Wenn also in der Pivot-Tabelle ein Land oder ein Jahr ausgewählt wird, wirkt der TOPN()-Filter zusätzlich, aber nicht stattdessen. Ohne KEEPFILTERS() würde TOPN() den bisherigen Filter aufheben, und das Measure würde global (über alle Kontexte) rechnen.
Beispiel: Wird im Datenschnitt oder mit der Zeitachse der Pivot-Tabelle das Jahr 2024 gewählt, zeigt [Top-2-Produkte] die Top-2-Produkte innerhalb des Jahres 2024 – nicht global über alle Jahre.
TOPN(…): Hier passiert die eigentliche „Magie“:
- 2 → Anzahl der zurückzugebenden Zeilen (Top 2).
- ALL(t_Produkte[ProduktName]) → entfernt alle aktuellen Filter auf die Produktnamen, damit die Top-2-Auswahl global über alle Produkte erfolgt. (Ohne ALL() würde die Berechnung nur im aktuellen Filterkontext laufen, zum Beispiel pro Kategorie.)
- [Umsatz] → nach dieser Kennzahl wird sortiert.
- DESC → absteigend, also höchste Umsätze zuerst.
Das Ergebnis von TOPN() ist eine Tabelle, die nur die zwei Produkte mit dem höchsten Umsatz enthält.
Wie das Zusammenspiel funktioniert:
- TOPN() liefert eine Tabelle mit den 2 besten Produktnamen.
- KEEPFILTERS() sorgt dafür, dass diese Auswahl zusätzlich zu anderen Filtern gilt.
- CALCULATE() führt dann das Measure [Umsatz] nur über diese gefilterten Produkte aus.
Das Ergebnis ist ein einziger Wert: der Umsatz der zwei umsatzstärksten Produkte.
Vergleich TOPN() mit RANKX()
RANKX() und TOPN() verfolgen ein ähnliches Ziel, unterscheiden sich aber konzeptionell:
Funktion: Rückgabe → Typische Anwendung
- RANKX(): Zahl (Rang eines Elements) → Ranking oder Platzierung anzeigen
- TOPN(): Tabelle (Liste der besten Werte) → Top-N-Analysen oder Filterung
Oft werden beide kombiniert: TOPN() wählt die besten Datensätze aus, und RANKX() nummeriert sie anschließend durch.
Praxisbeispiele aus dem Controlling
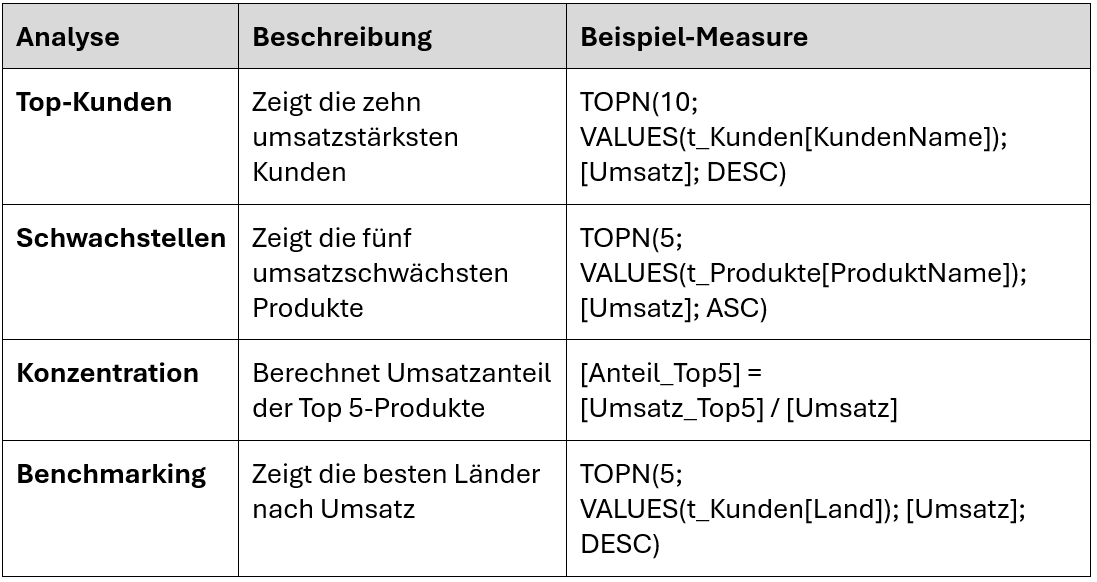
Diese Auswertungen sind echte Klassiker im Controlling – besonders im Produktmanagement, Vertrieb und Ergebnisanalyse.
Fazit
Mit der Funktion TOPN() können Sie gezielt die entscheidenden Datensätze identifizieren – und damit Ihre Reports deutlich aussagekräftiger gestalten.
Sie ist ideal für:
- Top-N-Analysen (Top-Kunden, Top-Produkte)
- Bottom-N-Analysen (Flop-Artikel, Schwachstellen)
- Pareto-Analysen (80/20-Regel)
- Benchmarking und Marktvergleiche
Während RANKX() für Rangnummern sorgt, liefert TOPN() die konkrete Datenbasis für Ihre Analysen. Kombiniert eingesetzt, sind beide Funktionen ein mächtiges Werkzeug für datengestütztes Controlling in Excel.
Demo-Daten für Power Pivot und DAX-Measures
In der folgenden Excel-Vorlage sind alle vorgestellten DAX-Measures eingerichtet. Sie finden dazu in der Vorlage:
- die Übersicht (Menü) mit Links zu den jeweiligen Musteranalysen und DAX-Measures sowie
- einer Verlinkung auf die Anleitungen zu den jeweiligen DAX-Measures,
- Musterdaten für Kunden, Produkte und Bestellungen,
- eine Kalendertabelle für die Zeitanalyse und die Time-Intelligence-Funktionen,
- alle definierten DAX-Measures in einer gesonderten Tabelle des Datenmodells: t_Measures
- eine Auswahl von Pivot-Tabellen als Grundlage für das Beispiel-Dashboard und
- ein Dashboard, in dem beispielhaft ausgewählte Pivot-Tabellen und die hinterlegten DAX-Measures als Chart oder KPI-Karte aufbereitet sind.
Nutzen Sie diese Vorlage, um sich mit den DAX-Measures und den Excel-Funktionen vertraut zu machen. Sie können diese Funktionsvorlagen nutzen und für Ihre Daten leicht anpassen.
Mit den Anleitungen und Beschreibungen auf business-wissen.de erarbeiten Sie Schritt für Schritt Ihr eigenes Datenmodell und die für Sie passenden DAX-Measures.
So machen Sie sich schnell mit den umfassenden Möglichkeiten von Power Pivot vertraut.