Python in Excel für die DatenanalyseVisualisierung mit Python – professionelle Diagramme mit Seaborn
- Warum Visualisierung für die explorative Statistik wichtig ist
- Python-Bibliothek Seaborn
- Grundlage: Datensatz für die Datenanalyse
- Daten in Python importieren
- Säulendiagramm mit Seaborn erstellen
- Was bewirkt der Python-Code für das Säulendiagramm
- Streudiagramm: Zusammenhang zwischen Preis und Verkaufsmenge
- Was bewirkt der Python-Code für das Streudiagramm?
- Liniendiagramm für Umsatzentwicklung nach Produkt
- Wie wird mit Python ein Liniendiagramm erstellt?
- Boxplot: Verteilungen und Ausreißer erkennen
- Wie wird mit Python ein Boxplot erstellt?
- Heatmap: Umsatz nach Land und Produkt visualisieren
- Wie wird mit Python eine Heatmap erstellt?
- Diagrammtyp gezielt auswählen
- Fazit
Warum Visualisierung für die explorative Statistik wichtig ist
Mit Python in Excel lassen sich einfache Diagramme im Rahmen einer deskriptiven Statistik erstellen. Für viele Datenanalysen reicht das bereits aus.
Doch es gibt auch weitergehende Fragen, um Sachverhalte besser zu verstehen. Zum Beispiel:
- Wie unterscheiden sich Umsätze nach Vertriebskanal?
- Gibt es einen Zusammenhang zwischen Preis und Verkaufsmenge?
- Welche Produkte erzielen in welchen Ländern die höchsten Umsätze?
- Wie verteilen sich die Verkaufswerte innerhalb einzelner Kategorien?
Für solche Fragestellungen sind erweiterte Visualisierungen hilfreich. Sie zeigen nicht nur einzelne Werte, sondern machen Muster, Verteilungen und Zusammenhänge sichtbar.
Python-Bibliothek Seaborn
Dafür eignet sich in Python besonders die Bibliothek Seaborn. Seaborn baut auf Matplotlib auf, bietet aber komfortablere Funktionen und bessere Standardlayouts für statistische Diagramme.
Der große Vorteil gegenüber Standard-Excel-Charts: Während Sie in Excel meist zuerst eine Pivot-Tabelle erstellen müssen, kann Seaborn Daten direkt im Diagramm aggregieren; zum Beispiel Summen, Mittelwerte oder Quantile.
Grundlage: Datensatz für die Datenanalyse
Alle folgenden Codebeispiele basieren auf einer Excel-Tabelle mit Verkaufsdaten mit folgendem Aufbau.
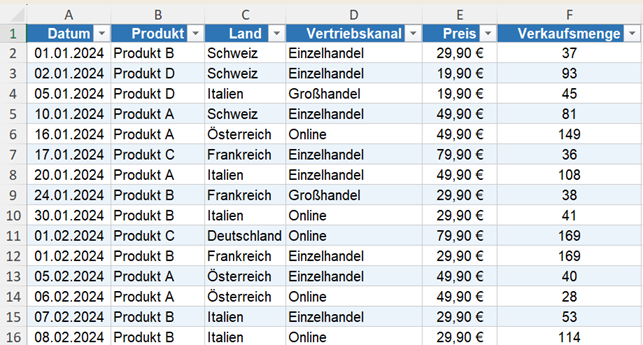
Daten in Python importieren
Zunächst laden Sie den Datensatz und berechnen aus Verkaufsmenge und Preis den Umsatz. Zudem formatieren Sie das Datum und die Angaben zum Vertriebskanal im passenden Datenformat:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid")
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
umsatz["Datum"] = pd.to_datetime(umsatz["Datum"])
umsatz["Vertriebskanal"] = umsatz["Vertriebskanal"].astype("category")
umsatz
In diesem Code passiert Folgendes:
- pandas verarbeitet die Daten.
- matplotlib.pyplot stellt die technische Basis für Diagramme bereit.
- seaborn erzeugt komfortable statistische Visualisierungen. Mit sns.set_theme() sorgen Sie für ein professionelles Layout der Diagramme.
- Die Spalte Umsatz wird berechnet und das Datum korrekt formatiert.
- Die Spalte Vertriebskanal erhält den Python-Datentyp category; das hat Vorteile im Hinblick auf Speicherbedarf und Performance.
Die Bibliotheken Seaborn, Pandas und Matplotlib sind in Excel bereits vorinstalliert, weshalb kein zusätzliches Setup nötig ist.
In der Praxis enthalten Excel-Tabellen oft leere Zellen. Seaborn ignoriert fehlende Werte in vielen Fällen automatisch. Dennoch können sie – insbesondere bei Aggregationen – zu unerwarteten Ergebnissen führen.
Am besten bereinigen Sie fehlende Werte vor der Datenanalyse und Visualisierung mit:
umsatz.dropna(subset=['Umsatz'])
oder
umsatz.fillna(0)
Säulendiagramm mit Seaborn erstellen
Ein häufiger Anwendungsfall ist der Vergleich von Kategorien. Dazu wird im folgenden Beispiel der Umsatz der einzelnen Vertriebskanäle (= Kategorie) verglichen. Der Python-Code mit Seaborn lautet dafür:
order = umsatz.groupby("Vertriebskanal")["Umsatz"].sum().sort_values().index
sns.barplot(
data=umsatz,
x="Vertriebskanal",
y="Umsatz",
estimator="sum",
errorbar=None,
order=order
)
plt.title("Umsatz nach Vertriebskanal")
plt.show()
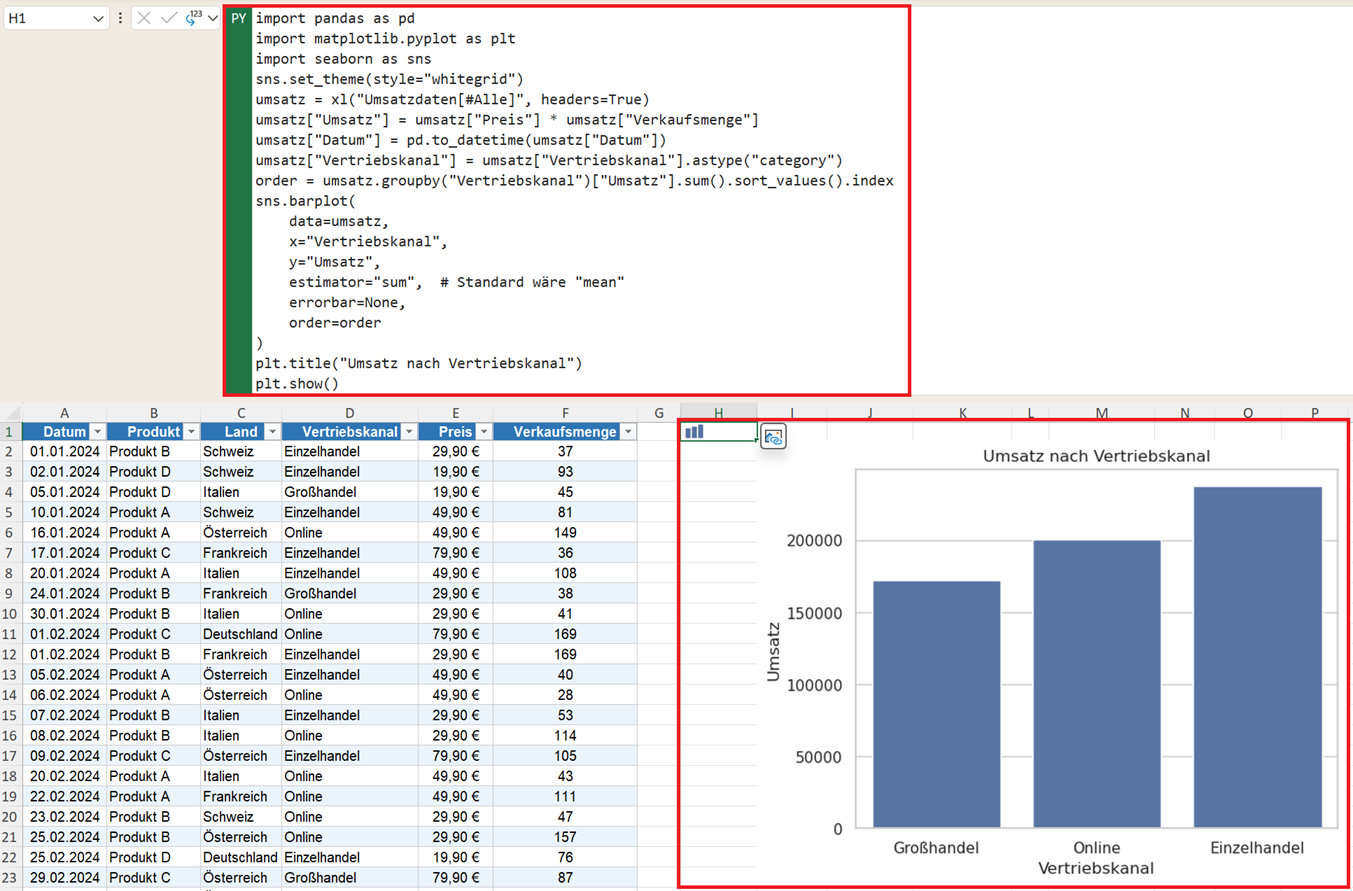
Dieses Diagramm zeigt, welcher Vertriebskanal den höchsten Gesamtumsatz erzielt. Im Gegensatz zu Excel müssen Sie hier die Daten nicht vorher gruppieren – Seaborn erledigt das direkt im Diagrammbefehl.
Was bewirkt der Python-Code für das Säulendiagramm
Die Schritt-für-Schritt-Erklärung des Python-Codes beginnt mit der folgenden Zeile:
order = umsatz.groupby("Vertriebskanal")["Umsatz"].sum().sort_values().index
Diese Zeile berechnet die Reihenfolge der Vertriebskanäle für das spätere Diagramm. Hier passieren mehrere Schritte gleichzeitig:
- groupby("Vertriebskanal"): Alle Datensätze werden nach Vertriebskanälen gruppiert.
- ["Umsatz"]: Es wird festgelegt, dass die Umsätze analysiert werden sollen.
- .sum(): Alle Umsätze je Vertriebskanal werden addiert. Standardmäßig wird hier der Mittelwert ("mean") berechnet.
- .sort_values(): Die Vertriebskanäle werden nach Umsatz sortiert. Standardmäßig erfolgt die Sortierung aufsteigend. Der kleinste Umsatz steht also zuerst.
- .index: Hier werden nur die Namen der Vertriebskanäle übernommen. Diese Reihenfolge wird später im Diagramm verwendet.
- sns.barplot(…: Mit dieser Funktion wird ein Säulendiagramm mit Seaborn erstellt. Seaborn erzeugt automatisch moderne und optisch ansprechende Diagramme.
data=umsatz,
Legt fest, dass die Daten aus dem DataFrame umsatz verwendet werden.
x="Vertriebskanal",
Die Spalte Vertriebskanal wird auf der x-Achse dargestellt.
y="Umsatz",
Die Umsätze werden auf der y-Achse dargestellt. Je höher der Umsatz, desto höher der Balken.
estimator="sum",
Dieser Parameter legt fest, wie Seaborn die Werte berechnet. Ohne diesen Parameter würde Seaborn standardmäßig den Durchschnitt berechnen mit mean. Mit: sum werden stattdessen die Umsätze addiert. Das Diagramm zeigt damit den Gesamtumsatz pro Vertriebskanal.
errorbar=None,
Normalerweise zeigt Seaborn häufig zusätzliche Fehlerbalken an. Diese stellen statistische Unsicherheiten oder Streuungen dar. Mit None werden diese Fehlerbalken deaktiviert. Das Diagramm wirkt dadurch übersichtlicher.
order=order
Hier wird die zuvor berechnete Sortierreihenfolge verwendet. Dadurch erscheinen die Säulen im Diagramm sortiert nach Umsatz. Ohne diesen Parameter würde Seaborn meist alphabetisch sortieren.
)
Diese Klammer beendet die Funktion sns.barplot().
plt.title("Umsatz nach Vertriebskanal")
Fügt dem Diagramm einen Titel hinzu. Dadurch erkennt der Betrachter sofort, was dargestellt wird.
plt.show()
Mit plt.show() wird das Diagramm angezeigt.
Hinweis: Wenn Sie kein Säulen-, sondern ein Balkendiagramm erstellen wollen, drehen Sie die Angaben für die x- und y-Achse einfach um. Sie definieren an der entsprechenden Stelle:
sns.barplot(
data=umsatz,
x="Umsatz",
y="Vertriebskanal",
estimator="sum",
errorbar=None,
order=order
)
Streudiagramm: Zusammenhang zwischen Preis und Verkaufsmenge
Ein Streudiagramm eignet sich besonders gut, um Zusammenhänge zwischen zwei numerischen Variablen sichtbar zu machen. Dafür nutzen Sie im Beispiel den Python-Code:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid")
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
umsatz["Datum"] = pd.to_datetime(umsatz["Datum"])
umsatz["Vertriebskanal"] = umsatz["Vertriebskanal"].astype("category")
sns.scatterplot(
data=umsatz,
x="Preis",
y="Verkaufsmenge",
hue="Vertriebskanal"
)
plt.title("Preis und Verkaufsmenge nach Vertriebskanal")
plt.show()
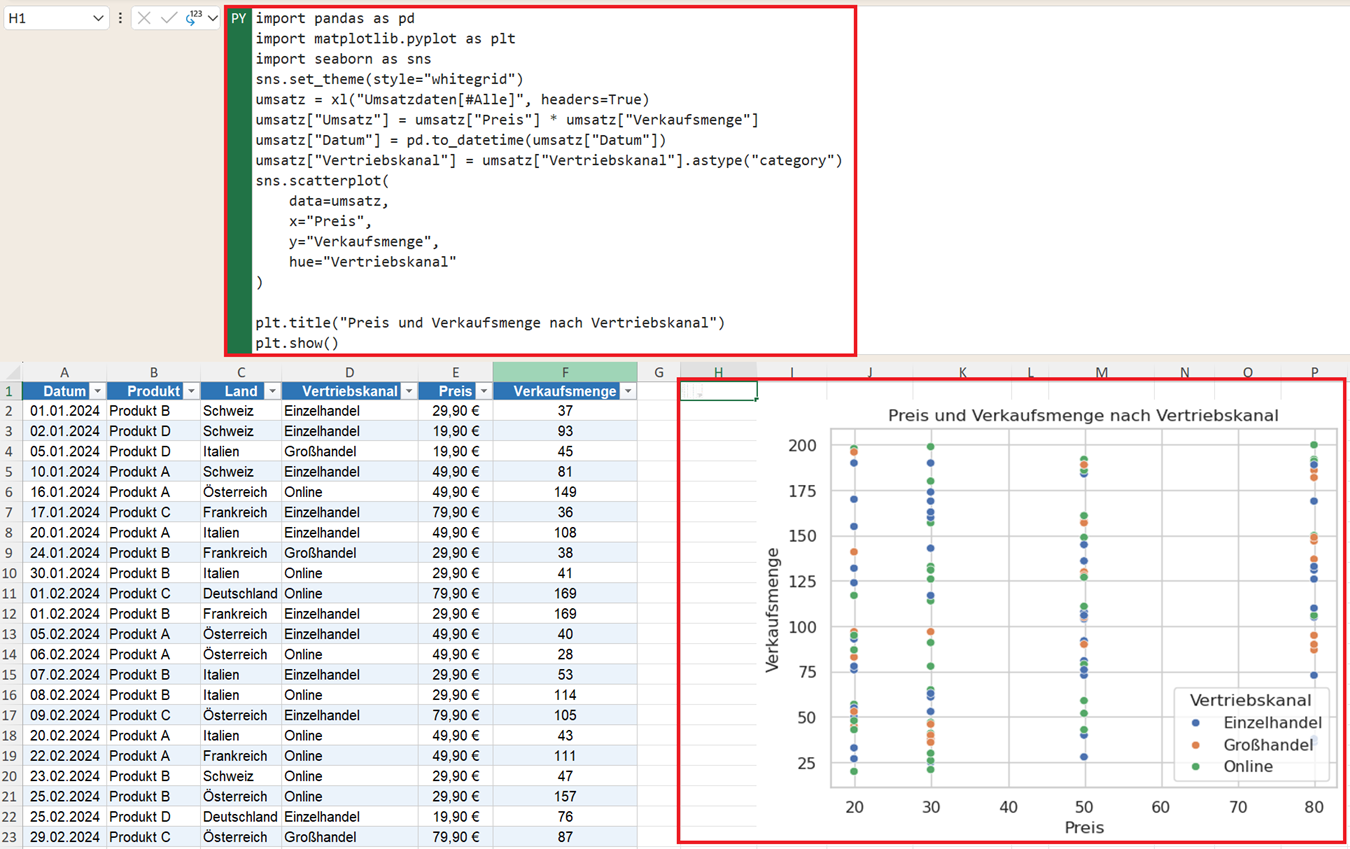
Was bewirkt der Python-Code für das Streudiagramm?
Der Python-Code für diese Diagramm-Variante funktioniert folgendermaßen:
sns.scatterplot(
Mit dieser Funktion wird ein Streudiagramm erstellt. Ein Streudiagramm zeigt Beziehungen zwischen zwei numerischen Variablen. Jeder Punkt repräsentiert einen Datensatz.
data=umsatz,
Legt fest, dass die Daten aus dem DataFrame umsatz verwendet werden.
x="Preis",
Die Spalte Preis wird auf der x-Achse dargestellt. Je weiter rechts ein Punkt liegt, desto höher ist der Preis.
y="Verkaufsmenge",
Die Spalte Verkaufsmenge wird auf der y-Achse dargestellt. Je höher ein Punkt liegt, desto größer ist die Verkaufsmenge.
hue="Vertriebskanal"
Dieser Parameter färbt die Datenpunkte nach Vertriebskanal ein. Jeder Vertriebskanal erhält automatisch eine eigene Farbe. Dadurch erkennt man sofort Unterschiede zwischen den Vertriebskanälen.
)
Diese Klammer beendet die Funktion sns.scatterplot().
plt.title("Preis und Verkaufsmenge nach Vertriebskanal")
Dieser Befehl fügt dem Diagramm einen Titel hinzu. Dadurch erkennt der Betrachter sofort, was dargestellt wird.
plt.show()
Mit plt.show() wird das Diagramm angezeigt.
Liniendiagramm für Umsatzentwicklung nach Produkt
Das nächste Beispiel zeigt, wie Sie mit Seaborn ein Liniendiagramm erstellen. Das zeigt oft den Umsatz im Zeitverlauf an. Dafür nutzen Sie diesen Python-Code:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid")
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
umsatz["Datum"] = pd.to_datetime(umsatz["Datum"])
umsatz["Vertriebskanal"] = umsatz["Vertriebskanal"].astype("category")
umsatz_monatlich = (
umsatz.groupby([pd.Grouper(key="Datum", freq="M"), "Produkt"])["Umsatz"]
.sum()
.reset_index()
)
sns.lineplot(
data=umsatz_monatlich,
x="Datum",
y="Umsatz",
hue="Produkt"
)
plt.title("Monatliche Umsatzentwicklung nach Produkt")
plt.xticks(rotation=45, ha='right')
plt.show()
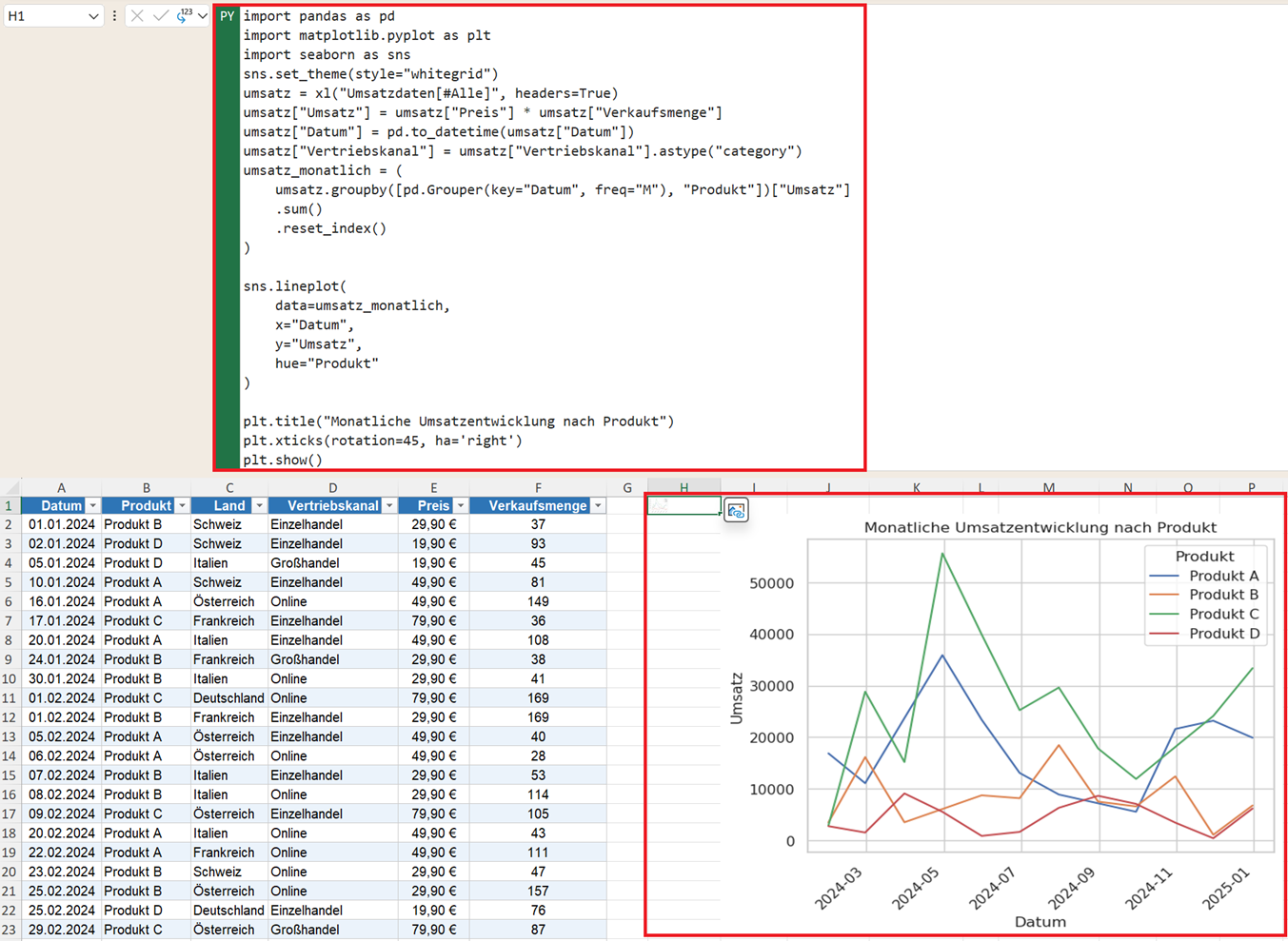
Wie wird mit Python ein Liniendiagramm erstellt?
Der Python-Code wird im Folgenden wieder Schritt für Schritt erklärt.
Zunächst werden die benötigten Daten berechnet
umsatz_monatlich = (
Hier beginnt eine mehrzeilige Zuweisung. Das Ergebnis der folgenden Berechnung wird in der Variable umsatz_monatlich gespeichert. Die runden Klammern ermöglichen es, den Code übersichtlich auf mehrere Zeilen aufzuteilen.
umsatz.groupby([pd.Grouper(key="Datum", freq="M"), "Produkt"])["Umsatz"]
Diese Zeile gruppiert die Daten gleichzeitig nach Monaten und nach Produkten. Die einzelnen Bestandteile bedeuten:
- groupby(...): Mit groupby() werden Datensätze gruppiert.
- pd.Grouper(key="Datum", freq="M"): Das ist ein spezieller Parameter, um das Datum zu gruppieren: key="Datum" verwendet die Spalte Datum, freq="M" gruppiert nach Monaten.
- "Produkt": Zusätzlich zur Monatsgruppierung werden die Daten auch nach Produkten getrennt.
- ["Umsatz"]: Es wird festgelegt, dass die Umsatzspalte analysiert werden soll.
.sum()
Addiert alle Umsätze pro Monat und Produkt. Dadurch entstehen aggregierte Monatswerte.
.reset_index()
Wandelt das Gruppierungsergebnis wieder in eine normale Tabelle um. Ohne diese Funktion würden Monat und Produkt als Index gespeichert bleiben.
)
Diese Klammer beendet die mehrzeilige Berechnung.
Dann wird das Diagramm erstellt
sns.lineplot(
Mit dieser Funktion wird ein Liniendiagramm erstellt. Ein Liniendiagramm eignet sich besonders gut für Zeitreihenanalysen.
data=umsatz_monatlich,
Legt fest, dass die Daten aus dem DataFrame umsatz_monatlich verwendet werden.
x="Datum",
Das Datum aus der Datumsspalte wird auf der x-Achse dargestellt.
y="Umsatz",
Die Umsatzwerte werden auf der y-Achse dargestellt. Je höher die Linie, desto höher der Umsatz.
hue="Produkt"
Dieser Parameter färbt die Linien nach Produkt ein. Jedes Produkt erhält automatisch eine eigene Farbe. Dadurch lassen sich Umsatzentwicklungen verschiedener Produkte direkt vergleichen.
)
Diese Klammer beendet die Funktion sns.lineplot().
plt.title("Monatliche Umsatzentwicklung nach Produkt")
Fügt dem Diagramm einen Titel hinzu. Dadurch erkennt der Betrachter sofort, was dargestellt wird.
plt.xticks(rotation=45, ha='right')
Diese Zeile formatiert die Beschriftung der x-Achse. Es bedeuten:
- rotation=45: Dreht die Datumswerte um 45 Grad.
- ha='right': Richtet die Beschriftung rechtsbündig aus. Dadurch bleiben längere Datumswerte besser lesbar.
plt.show()
Mit plt.show() wird das Diagramm schließlich angezeigt.
Boxplot: Verteilungen und Ausreißer erkennen
Um weitere Erkenntnisse aus dem Datensatz zu gewinnen, sind komplexere Auswertungen hilfreich. Eine bewährte Methode ist, einen Boxplot zu analysieren. Ein solches Diagramm erstellen Sie mit Python und Seaborn mit diesem Code:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid")
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
umsatz["Datum"] = pd.to_datetime(umsatz["Datum"])
umsatz["Vertriebskanal"] = umsatz["Vertriebskanal"].astype("category")
sns.boxplot(
data=umsatz,
x="Vertriebskanal",
y="Umsatz"
)
plt.title("Umsatzverteilung nach Vertriebskanal")
plt.show()
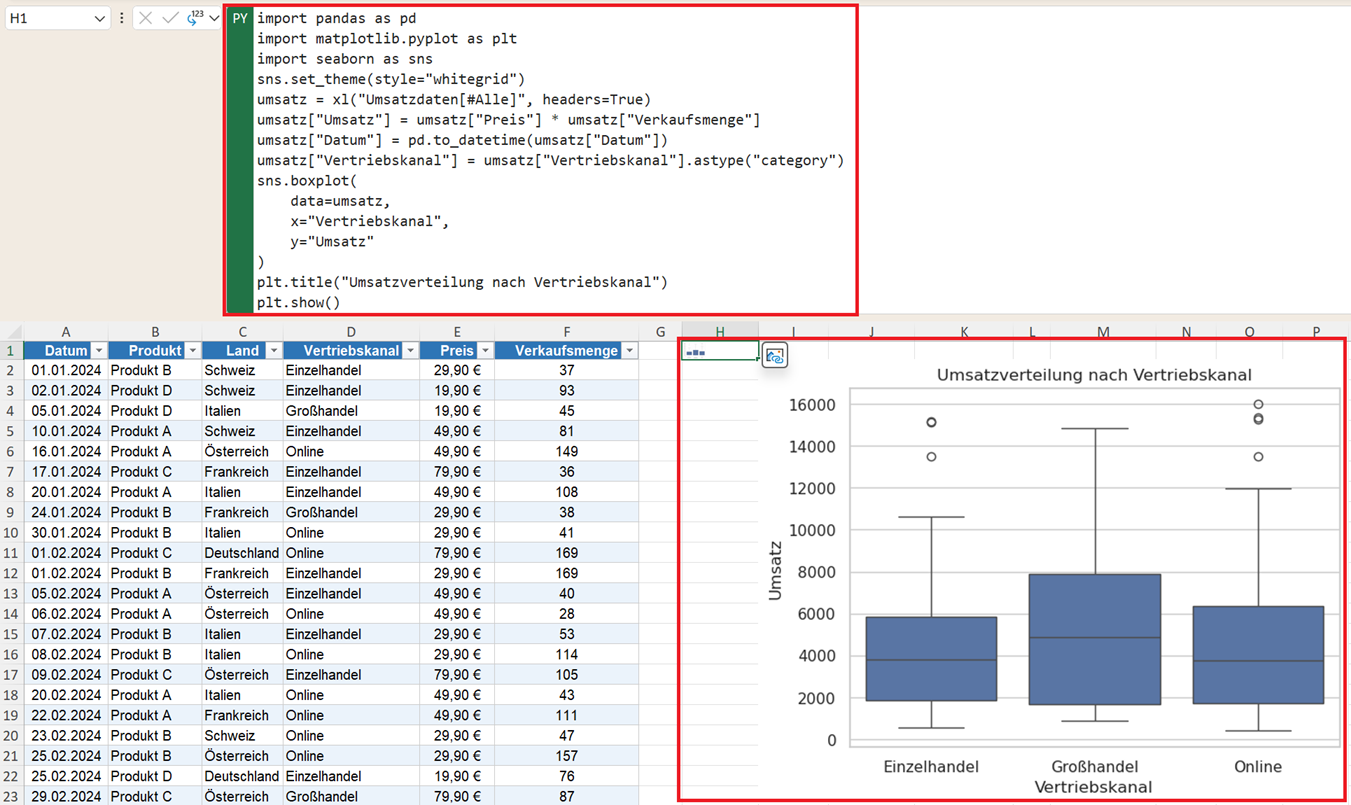
Wie wird mit Python ein Boxplot erstellt?
Die Befehle für einen Boxplot mit Python und Seaborn lauten:
sns.boxplot(
Mit dieser Funktion erstellen Sie ein Diagramm als sogenannten Boxplot. Ein Boxplot eignet sich, um Verteilungen, Streuungen, Medianwerte und Ausreißer sichtbar zu machen.
data=umsatz,
Legt fest, dass die Daten aus dem DataFrame umsatz verwendet werden.
x="Vertriebskanal",
Die Spalte Vertriebskanal wird auf der x-Achse dargestellt. Jeder Vertriebskanal erhält eine eigene Box.
y="Umsatz"
Die Umsatzwerte werden auf der y-Achse dargestellt. Dadurch analysiert das Diagramm die Umsatzverteilung je Vertriebskanal.
)
Diese Klammer beendet die Funktion sns.boxplot().
plt.title("Umsatzverteilung nach Vertriebskanal")
Fügt dem Diagramm einen Titel hinzu. Dadurch erkennt der Betrachter sofort, was dargestellt wird.
plt.show()
Mit plt.show() wird das Diagramm angezeigt. Ein Boxplot enthält mehrere statistische Informationen gleichzeitig:
- Die Box: Zeigt den mittleren Bereich der Daten. Dort liegen die meisten Werte.
- Die Linie in der Box: Stellt den Median dar. Der Median ist der mittlere Wert der Verteilung.
- Die „Whisker“: Die Linien oberhalb und unterhalb der Box zeigen die typische Streuung der Daten.
- Punkte außerhalb der Box: Einzelne Punkte außerhalb der Whisker gelten als mögliche Ausreißer. Zum Beispiel durch ungewöhnlich hohe Umsätze, extrem große Bestellungen oder Sonderaktionen.
Heatmap: Umsatz nach Land und Produkt visualisieren
Eine weitere Variante, um Zusammenhänge zwischen Daten sichtbar zu machen und zu verstehen, ist die sogenannte Heatmap. Auch diese Diagrammform lässt sich mit Python und Seaborn schnell und einfach erstellen. Sie nutzen diesen Code:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid")
umsatz = xl("Umsatzdaten[#Alle]", headers=True)
umsatz["Umsatz"] = umsatz["Preis"] * umsatz["Verkaufsmenge"]
umsatz["Datum"] = pd.to_datetime(umsatz["Datum"])
umsatz["Vertriebskanal"] = umsatz["Vertriebskanal"].astype("category")
pivot = pd.pivot_table(
umsatz,
values="Umsatz",
index="Land",
columns="Produkt",
aggfunc="sum",
fill_value=0
)
sns.heatmap(
pivot,
annot=True,
fmt=".0f",
cmap="YlGnBu"
)
plt.title("Umsatz-Heatmap nach Land und Produkt")
plt.show()
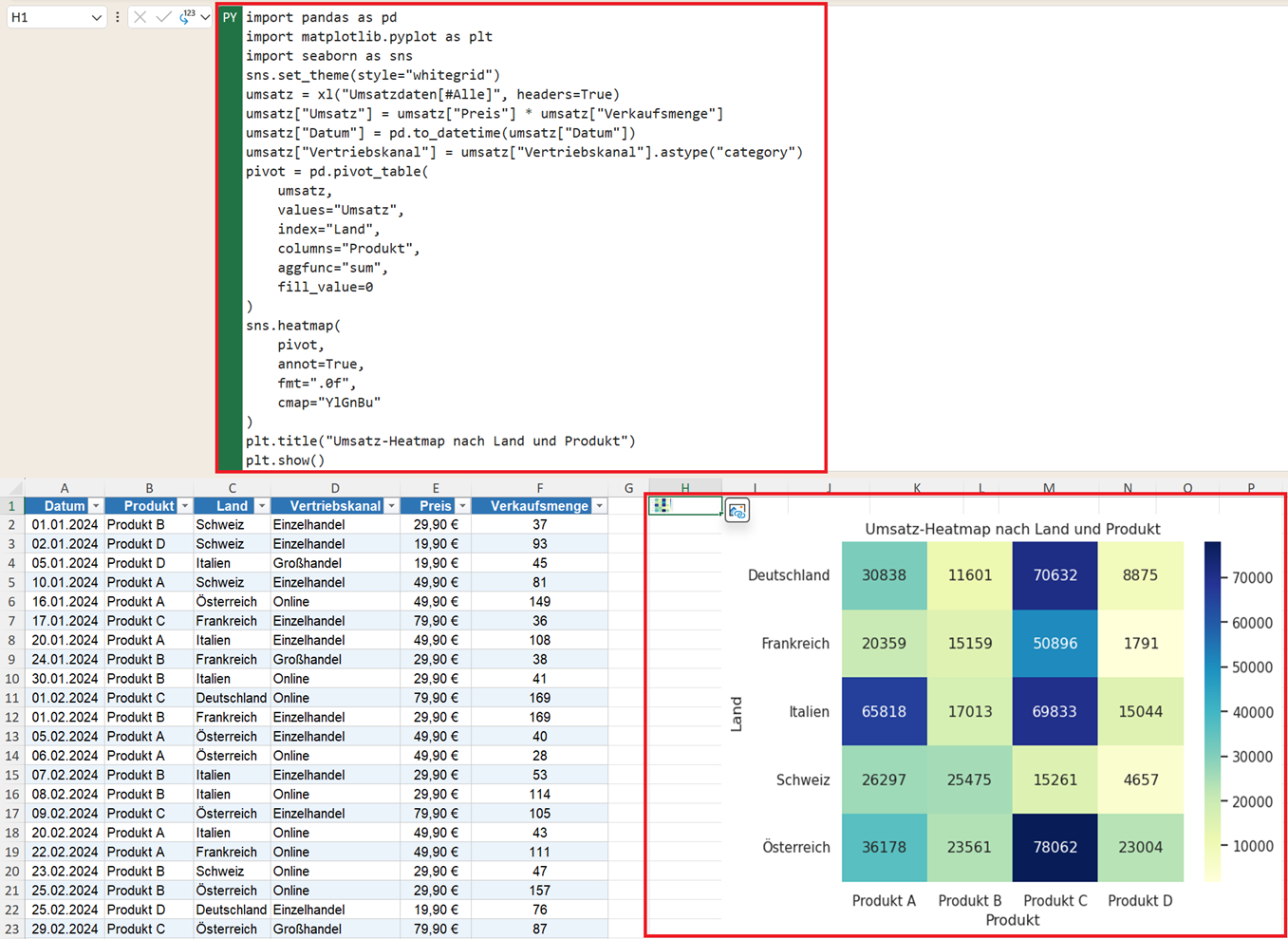
Wie wird mit Python eine Heatmap erstellt?
Zunächst wird mit den folgenden Befehlen eine Pivot-Tabelle erzeugt
pivot = pd.pivot_table(
Die Funktion pivot_table() gehört zu Pandas und funktioniert ähnlich wie eine PivotTable in Excel. Das Ergebnis wird in der Variable pivot gespeichert.
umsatz,
Legt fest, dass die Daten aus dem DataFrame umsatz verwendet werden.
values="Umsatz",
Bestimmt, welche Werte analysiert werden sollen. Hier werden die Umsatzwerte verwendet.
index="Land",
Die Zeilen der Pivot-Tabelle werden nach Ländern gruppiert.
columns="Produkt",
Die Spalten der Pivot-Tabelle werden nach Produkten aufgeteilt. Dadurch entsteht eine Kreuztabelle.
aggfunc="sum",
Legt fest, wie die Werte aggregiert werden. sum bedeutet, alle Umsätze werden addiert. Das entspricht der Summenfunktion in einer Excel-PivotTable.
fill_value=0
Fehlende Werte werden mit 0 ersetzt. Das ist wichtig, damit keine leeren Felder entstehen und die Heatmap sauber dargestellt wird.
)
Diese Klammer beendet die Funktion pd.pivot_table().
Dann wird das Diagramm als Heatmap mit den folgenden Befehlen erzeugt
sns.heatmap(
Eine Heatmap visualisiert Zahlenwerte über Farben. Hohe Werte erscheinen meist dunkler oder intensiver als kleine Werte. Dadurch lassen sich Muster und Auffälligkeiten schnell erkennen.
pivot,
Verwendet die zuvor erstellte Pivot-Tabelle als Datenquelle.
annot=True,
Zeigt die Zahlenwerte zusätzlich direkt in den Feldern der Heatmap an. Ohne diesen Parameter wären nur die Farben sichtbar.
fmt=".0f",
Legt das Zahlenformat fest. .0f bedeutet: keine Nachkommastellen und Ganzzahlen darstellen.
cmap="YlGnBu"
Bestimmt die Farbpalette der Heatmap. YlGnBu steht für Yellow, Green, Blue. Kleine Werte erscheinen heller, große Werte dunkler.
)
Diese Klammer beendet die Funktion sns.heatmap().
plt.title("Umsatz-Heatmap nach Land und Produkt")
Fügt dem Diagramm einen Titel hinzu. Dadurch erkennt der Betrachter sofort, was dargestellt wird.
plt.show()
Mit plt.show() wird das Diagramm angezeigt.
Diagrammtyp gezielt auswählen
Wählen Sie je nach Aufgabenstellung immer den passenden Diagrammtyp für die jeweilige Darstellung ab. Zum Beispiel:
| Ziel | Diagrammtyp |
|---|---|
| Kategorien vergleichen | Balken- oder Säulendiagramm |
| Entwicklung über Zeit zeigen | Liniendiagramm |
| Zusammenhang prüfen | Streudiagramm |
| Verteilungen vergleichen | Boxplot |
| Zwei Dimensionen kombinieren | Heatmap |
Fazit
Mit Seaborn wird Python in Excel zu einem leistungsfähigen Werkzeug für moderne Business-Analysen. Während einfache Diagramme oft direkt in Excel erstellt werden, bietet Seaborn Vorteile bei statistischen Auswertungen und flexibler Aggregation.
Die Diagramme aktualisieren sich automatisch bei Änderungen der Quelldaten. Beachten Sie jedoch: Es handelt sich um statische Visualisierungen ohne Interaktivität.
Die wichtigsten Funktionen in diesem Beitrag:
| Funktion | Verwendung |
|---|---|
| sns.set_theme() | Design festlegen |
| sns.barplot() | Kategorien vergleichen |
| sns.scatterplot() | Zusammenhänge analysieren |
| sns.lineplot() | Zeitreihen darstellen |
| sns.boxplot() | Verteilungen analysieren |
| sns.heatmap() | Matrix visualisieren |


