Python in Excel – erste Schritte und BerechnungenWas ist der DataFrame und warum ist er so wichtig?
Ein DataFrame ist mehr als eine Tabelle
Wenn Sie mit Python in Excel arbeiten, begegnet Ihnen ein Begriff immer wieder: DataFrame. Er ist das Herzstück jeder Datenanalyse in Python.
Auf den ersten Blick sieht ein DataFrame aus wie eine Excel-Tabelle. Technisch ist er jedoch etwas völlig anderes. Ein DataFrame ist eine spaltenorientierte In-Memory-Datenstruktur. Das bedeutet:
- Die Daten liegen im Arbeitsspeicher.
- Sie werden spaltenweise organisiert.
- Berechnungen erfolgen optimiert auf ganzen Spalten.
Vergleich: Excel-Zellen vs. DataFrame
Excel speichert jede Zelle einzeln mit Formatierungen, Formeln und Metadaten. Excel ist stark auf Darstellung und Benutzerinteraktion ausgelegt. Pandas speichert:
- nur Datenwerte
- spaltenorientiert
- ohne Formatierungslogik
- optimiert für Berechnungen
Das erklärt, warum Python bei größeren Datenmengen oft deutlich schneller ist als klassische Excel-Formeln.
Wichtig: In Excel ist die Zeilennummer fix. In Pandas hat ein DataFrame einen Index. Wenn man Daten sortiert oder filtert, bleibt der Index am Datensatz kleben. Das ist für Excel-Nutzer oft verwirrend, wenn plötzlich die Zeilennummern durcheinander sind.
Einsatz des DataFrame mit einer Beispieldatei
Ausgangspunkt ist der DataFrame, der auf der Basis von Umsatzdaten in einer Excel-Datei angelegt ist und in dieser Anleitung vorgestellt wird: Architektur, Arbeitsweise und technische Grundlagen für Python und Excel.
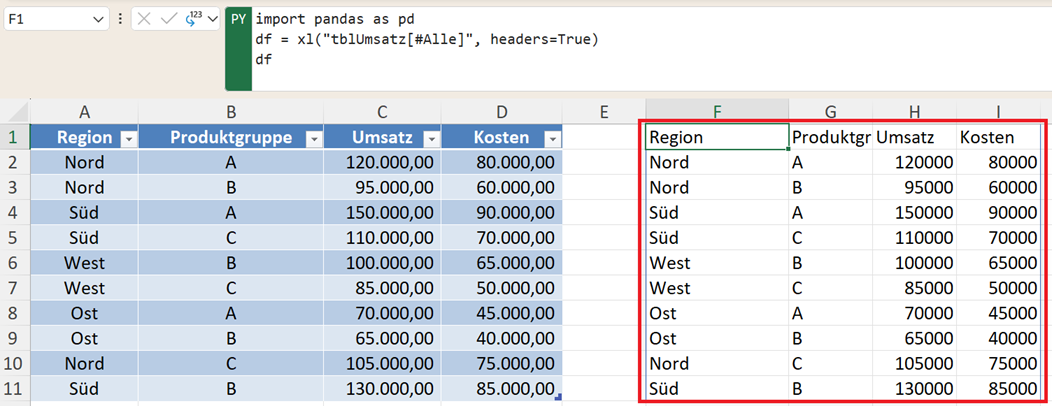
Der Python-Befehl lautet:
import pandas as pd
df = xl("tblUmsatz[#Alle]", headers=True)
df
Was passiert hier?
- Excel übergibt die Tabelle tblUmsatz an Python.
- Python erzeugt ein DataFrame-Objekt.
- Dieses Objekt wird in Excel angezeigt.
Ab diesem Moment arbeiten Sie nicht mehr mit Zellen, sondern mit einer strukturierten Datenrepräsentation.
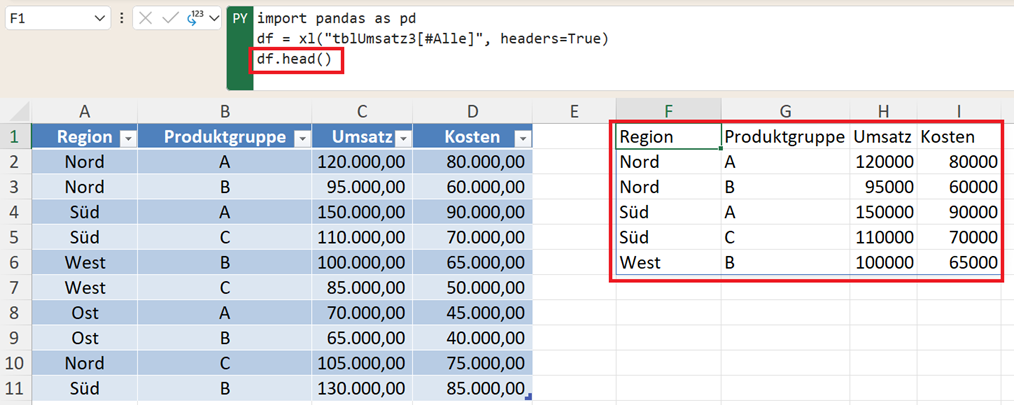
Behalten Sie den Überblick mit .head()
In Excel sind Sie es gewohnt, durch tausende Zeilen zu scrollen, um ein Gefühl für die Daten zu bekommen. In Python ist das oft gar nicht nötig – und bei sehr großen Datensätzen sogar unübersichtlich.
Hier hilft eine der wichtigsten Funktionen in pandas:
df.head()
Diese Anweisung zeigt nur die ersten 5 Zeilen Ihres DataFrames an. Warum ist das für Sie nützlich?
- Schnelle Kontrolle: Sie sehen sofort, ob die Spaltenüberschriften korrekt erkannt wurden und welche Datentypen vorliegen.
- Performance: Anstatt 100.000 Zeilen in Ihr Excel-Sheet zurückzuschreiben, lassen Sie sich nur einen Auszug anzeigen, während Sie Ihre Logik entwickeln.
- Fokus: Sie konzentrieren sich auf die Struktur der Daten, nicht auf die Masse.
Tipp aus der Praxis: Wenn Sie mehr sehen wollen, schreiben Sie einfach eine Zahl in die Klammer, zum Beispiel für die ersten zehn Zeilen:
df.head(10)
Das Gegenstück dazu ist übrigens df.tail(), womit Sie die letzten Zeilen Ihres Datensatzes prüfen können – ideal, um zu sehen, ob am Ende der Tabelle Summenzeilen oder Leerwerte stehen, die Sie eventuell entfernen müssen.
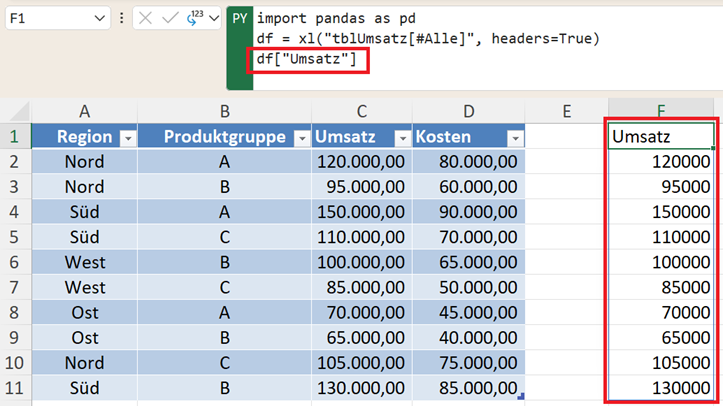
Zugriff auf Spalten des Datensatzes
In Excel würden Sie eine Spalte markieren. Im DataFrame greifen Sie so zu:
df["Umsatz"]
Das Ergebnis ist keine einzelne Zelle, sondern eine komplette Spalte als Datenobjekt.
Stellen Sie sich den DataFrame wie ein Kartenspiel vor: Jede Karte ist eine Spalte. Sie können eine Karte herausnehmen, sie bearbeiten und wieder in den Stapel stecken.
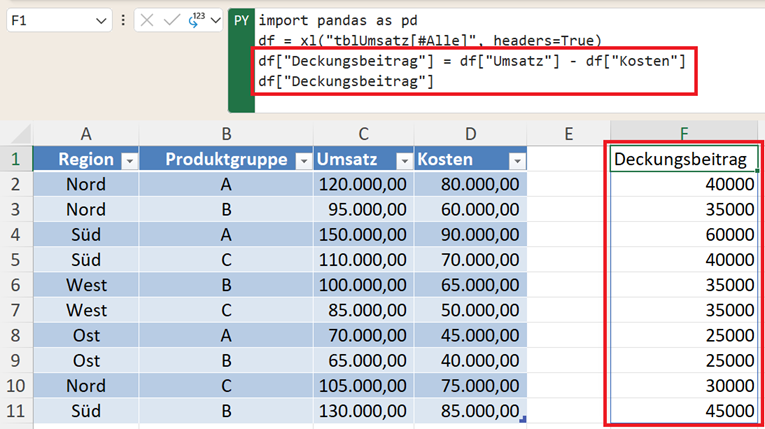
Damit können Sie Operationen direkt auf ganze Spalten anwenden. Beispiel:
df["Deckungsbeitrag"] = df["Umsatz"] - df["Kosten"]
Hier passiert:
- Die gesamte Umsatz-Spalte wird verarbeitet.
- Die gesamte Kosten-Spalte wird verarbeitet.
- Die Berechnung des Deckungsbeitrags erfolgt vektorisiert.
- Eine neue Spalte wird erzeugt.
Der Vorteil: kein Kopieren von Formeln, kein Ziehen mit der Maus, kein Risiko vergessener Zeilen.
Pandas speichert Daten spaltenweise im Speicher. Im Gegensatz dazu speichert Excel jede Zelle als eigenes Objekt. Dieser strukturelle Unterschied ist einer der Hauptgründe für Performancevorteile.
Warum das für Controller relevant ist? Im Controlling arbeiten Sie oft mit:
- großen Transaktionsdaten
- strukturierten Tabellen
- wiederkehrenden Berechnungen
Der DataFrame ist ideal für:
- Aggregationen
- KPI-Berechnungen
- Filterlogik
- Simulationen
Er ist im Grunde eine kleine Datenbank im Arbeitsspeicher.