Python in Excel – erste Schritte und BerechnungenAggregationen mit groupby() – die Python-Variante der Pivot-Tabelle
Praxisfall: Umsatz je Region mit Python ermitteln
Im Controlling lautet eine der häufigsten Fragen: Wie hoch ist der Umsatz oder Deckungsbeitrag je Region?
Ausgangspunkt ist der DataFrame, der auf der Basis von Umsatzdaten in einer Excel-Datei angelegt ist und in dieser Anleitung vorgestellt wird: Architektur, Arbeitsweise und technische Grundlagen für Python und Excel.
Der Python-Befehl lautet:
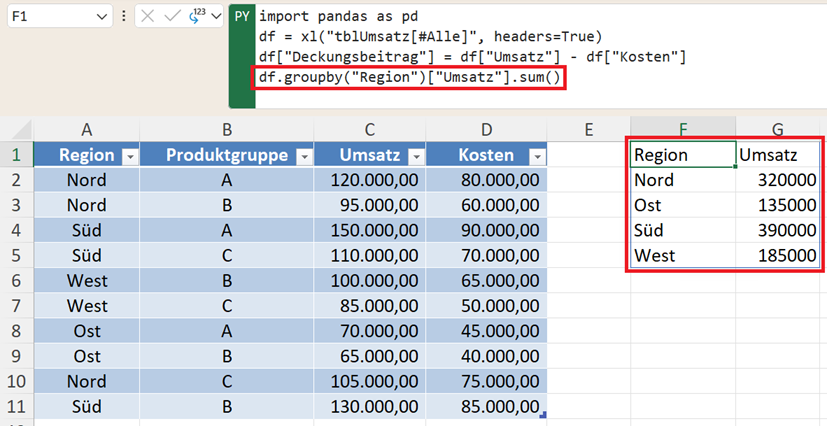
import pandas as pd
df = xl("tblUmsatz[#Alle]", headers=True)
df
Der Deckungsbeitrag ist berechnet zu:
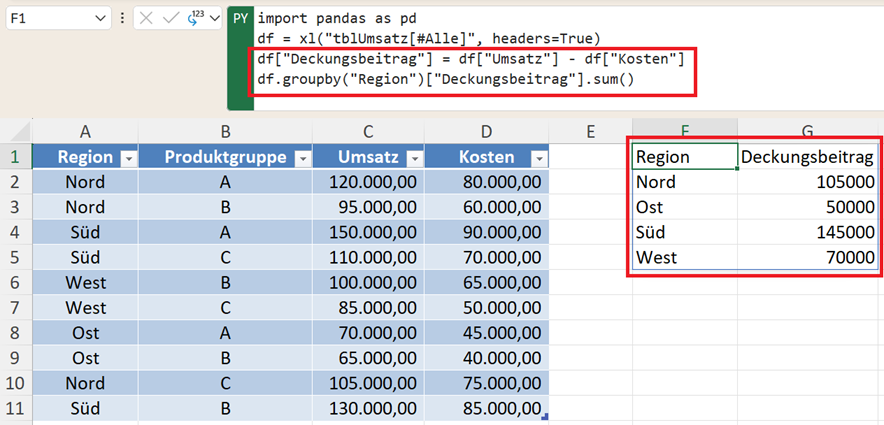
df["Deckungsbeitrag"] = df["Umsatz"] - df["Kosten"]
Nun kommt der entscheidende Schritt mit dem Python-Code:
df.groupby("Region")["Umsatz"].sum()
Was passiert hier genau?
- groupby("Region") → Die Daten werden nach Region gruppiert.
- ["Umsatz"] → Es wird nur die Umsatz-Spalte betrachtet.
- .sum() → Der Umsatz wird je Gruppe summiert.
Das Ergebnis ist eine verdichtete Übersicht, die funktional identisch mit einer Pivot-Tabelle ist.
Deckungsbeitrag je Region berechnen
Jetzt aggregieren Sie den Deckungsbeitrag als weitere Kennzahl:
df.groupby("Region")["Deckungsbeitrag"].sum()
Damit erhalten Sie direkt eine Management-Kennzahl ohne Pivot-Konfiguration, manuelle Feldzuweisung und Layout-Anpassung. Die Logik ist vollständig im Code definiert.
Ein wichtiger technischer Punkt: Das Ergebnis ist eine Series
Wenn Sie in Excel eine Pivot-Tabelle erstellen, erhalten Sie immer eine Tabelle mit Zeilen und Spalten. In Python passiert nach einer einfachen Aggregation wie .sum() etwas Besonderes: Das Ergebnis ist kein gewöhnlicher Datensatz (DataFrame), sondern ein Series-Objekt.
Das bedeutet:
- „Region“ wird zum Index
- Die Spaltenbezeichnung ist nicht explizit sichtbar
Was bedeutet das für Sie?
Stellen Sie sich eine Series als eine einzelne Datenspalte vor, die jedoch eine Besonderheit hat: Die Beschriftungen (im Beispiel die „Region“) sind nicht mehr Teil der Daten, sondern sie sind zum Index geworden.
Warum ist das ein Problem für Excel?
Wenn Sie dieses Series-Objekt direkt an eine Excel-Zelle zurückgeben, fehlen oft die Spaltenüberschriften oder die Zuordnung der Zeilenbeschriftungen wirkt „verschoben“.
Damit Excel die Daten wieder als saubere, zweidimensionale Tabelle erkennt, nutzen Sie einen einfachen Trick. Sie wandeln den Index mit reset wieder in eine normale Datenspalte um.
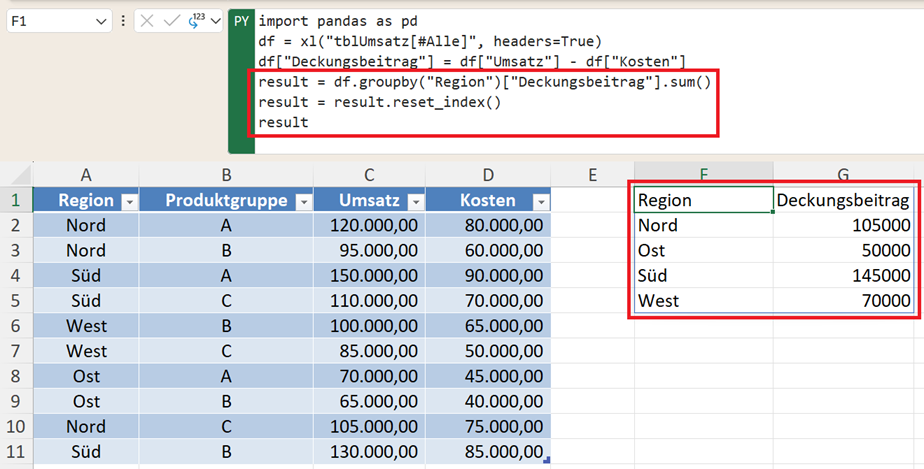
result = df.groupby("Region")["Deckungsbeitrag"].sum()
result = result.reset_index()
result
Warum ist reset_index() wichtig?
- Die Rückverwandlung: Der Index „Region“ wird wieder zu einer ganz normalen Datenspalte.
- Klare Struktur: Das Ergebnis ist nun wieder ein DataFrame.
- Saubere Übergabe: Excel kann die Daten nun perfekt mit korrekten Überschriften in die Zellen schreiben – genau so, wie Sie es von einer Pivot-Tabelle erwarten.
Wichtig: Immer, wenn Sie nach einem groupby() nur eine einzige Spalte berechnen, erzeugt Pandas eine Series. Mit .reset_index() machen Sie daraus wieder eine „excel-taugliche“ Tabelle.
Mehrdimensionale Aggregation (Ausblick)
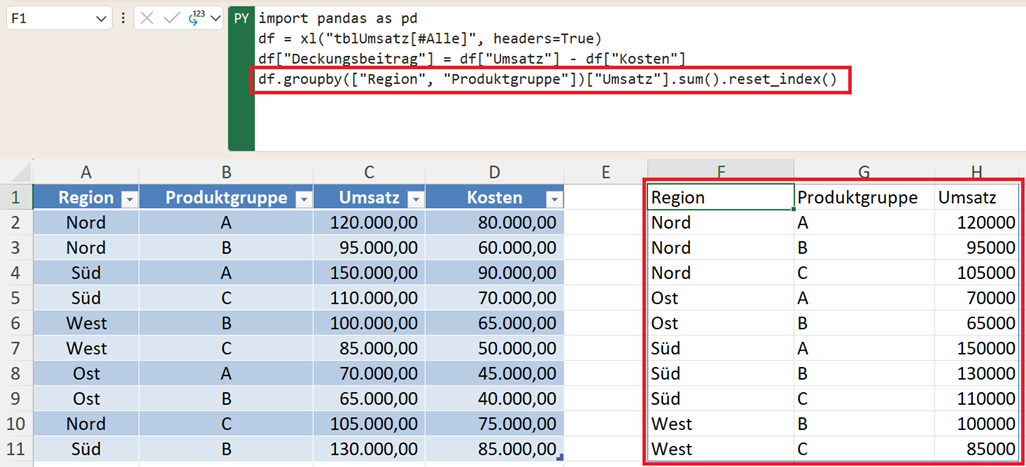
Sie können auch mehrere Dimensionen kombinieren und die Addition der jeweiligen Umsätze direkt mit reset_index() verbinden:
df.groupby(["Region", "Produktgruppe"])["Umsatz"].sum().reset_index()
Das entspricht einer Pivot-Tabelle mit:
- Region in Zeilen
- Produktgruppe als Untergliederung
- Umsatz als Summe
Und das in einer einzigen Codezeile.
Warum groupby() so mächtig ist
groupby() ist eines der wichtigsten Werkzeuge in Pandas. Sie können damit:
- Summen bilden
- Durchschnittswerte berechnen
- Minimum oder Maximum bestimmen
- Mehrere Kennzahlen gleichzeitig aggregieren
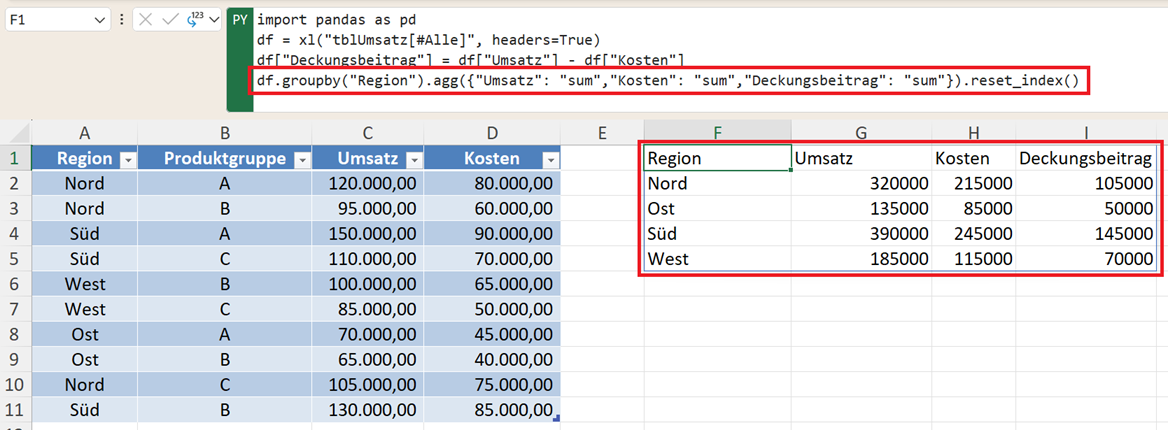
Beispiel:
df.groupby("Region").agg({
"Umsatz": "sum",
"Kosten": "sum",
"Deckungsbeitrag": "sum"
}).reset_index()
Damit erzeugen Sie eine komplette Management-Übersicht.
Fazit
In Excel konfigurieren Sie eine Pivot-Tabelle visuell. In Python definieren Sie die Aggregationslogik explizit. Das hat Vorteile:
- Reproduzierbarkeit
- Dokumentation
- Wiederverwendbarkeit
- Erweiterbarkeit
Gerade bei wiederkehrenden Reports ist das ein großer Mehrwert.
Mit groupby() haben Sie:
- eine strukturierte Alternative zur Pivot-Tabelle,
- eine skalierbare Aggregationslogik und
- die Basis für nahezu alle Controlling-Analysen.
Und vor allem: Sie haben gelernt, wie Python Daten nicht visuell, sondern strukturell verarbeitet.