Power Pivot – DAX-Measures erstellen und anwendenWie Pivot-Tabellen mit DAX-Funktionen arbeiten
Pivot-Tabellen mit Berechnungen aus einer Tabelle des Datenmodells
Um mit DAX-Funktionen wirklich erfolgreich zu sein, reicht es nicht, einfach Formeln anzuwenden. Sie sollten verstehen, wie eine Pivot-Tabelle mit den DAX-Funktionen rechnet.
Nur so können Sie später komplexe Measures entwickeln und deren Ergebnisse richtig interpretieren.
Grundlage sei folgendes Szenario: Sie arbeiten nur mit der Tabelle t_Bestellungen.
Und Sie möchten Folgendes für Ihre Datenanalyse wissen:
- Wie viele Bestellungen hat ein Kunde aufgegeben?
- Wie viele Artikel hat er insgesamt gekauft?
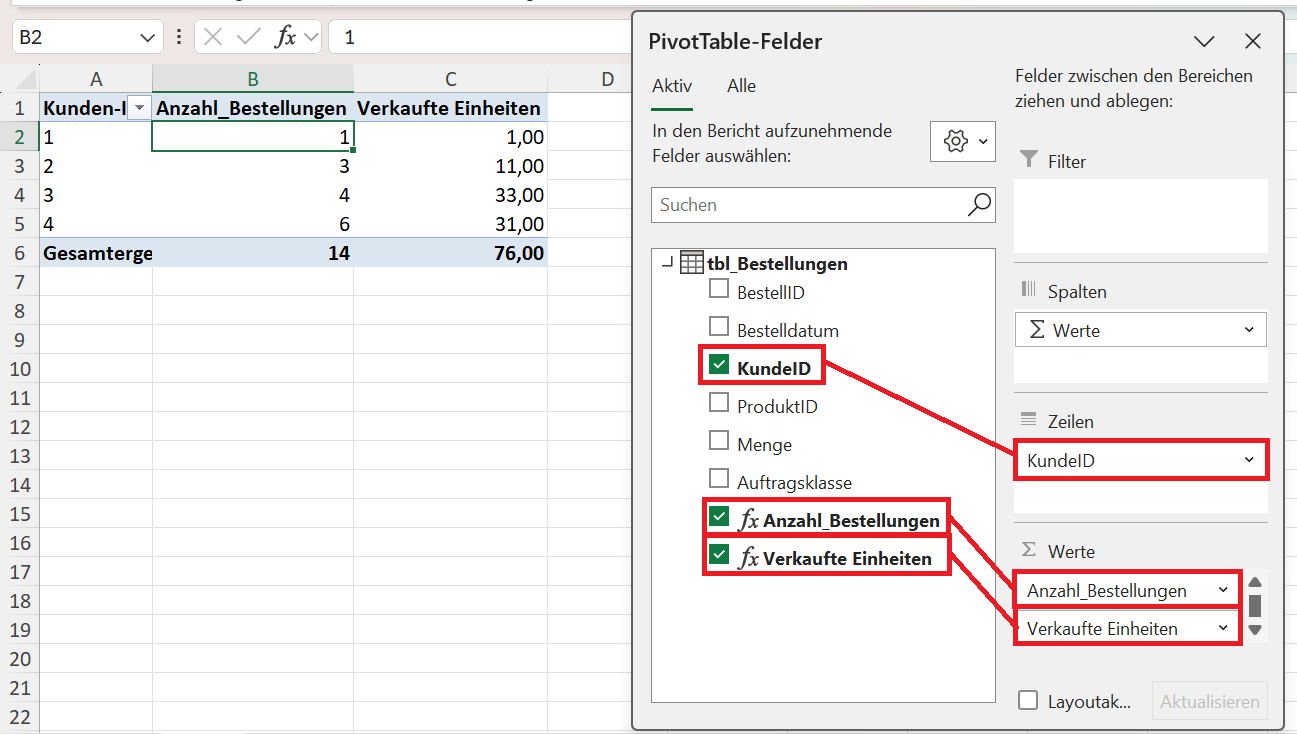
Dazu ziehen Sie die KundenID aus der Bestellungen-Tabelle in die Zeilen und verwenden die beiden Measures Produkte_Menge_verkauft und Anzahl_Bestellungen in den Wertebereich der Pivot-Tabelle.
Hinweis: In diesen beiden Anleitungen lesen Sie, wie die Summe der verkauften Einheiten und die Anzahl der Bestellungen mit DAX-Funktionen in Power Pivot berechnet werden.
Beispiel für den Kunden BikeLife:
- 159 Bestellungen
- 3.034 verkaufte Artikel
Was passiert im Hintergrund bei einer DAX-Funktion?
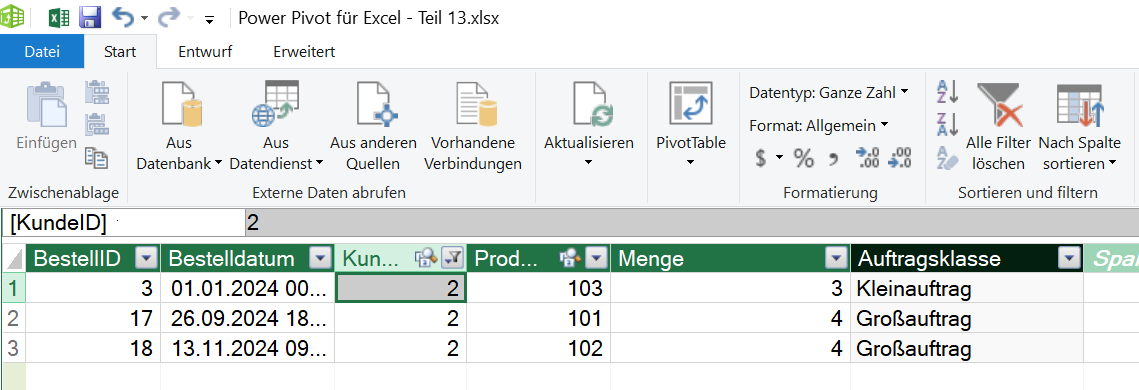
Die Pivot-Tabelle filtert die Tabelle mit den Bestellungen so, dass nur die Zeilen dieses Kunden sichtbar bleiben.
Auf diese gefilterte Teilmenge werden dann die Measures angewendet:
- DISTINCTCOUNT der BestellID → 159 Bestellungen
- SUM der verkauften Einheiten (Menge) → 3.034 Artikel
Damit erkennen Sie das Prinzip: Jede Zelle in einer Pivot-Tabelle ist das Ergebnis einer Filterung + Measure-Berechnung.
Pivot-Tabelle mit Daten aus mehreren Tabellen erstellen
Dabei müssen die Elemente für die Filterung nicht in der gleichen Tabelle stehen, in der die Daten für die Berechnung und Datenanalyse stehen. Das folgende Beispiel zeigt:
- Sie filtern aus der Dimensionstabelle mit Produkten t_Produkte den Produktnamen: Bremsbeläge MTB und
- berechnen dann die Zahl der Bestellungen mit diesem Produkt und die verkauften Mengen von diesem Produkt aus der Faktentabelle t_Bestellungen.
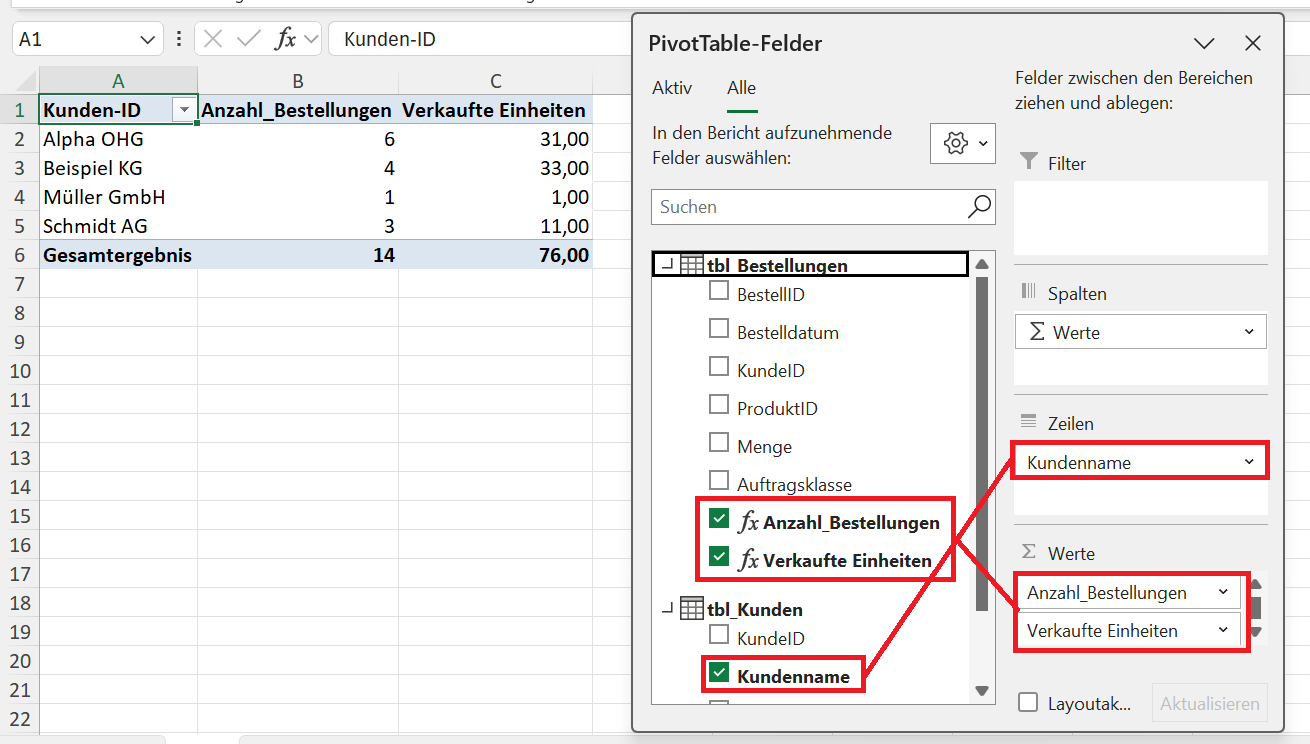
Beispiel: Bremsbeläge MTB
- 391 Bestellungen
- 2.344 verkaufte Einheiten (Menge)
Wie wird die Pivot-Tabelle mit den berechneten Daten erstellt?
Zuerst wird die Produkttabelle t_Produkte gefiltert – es bleibt nur die Zeile von Bremsbeläge MTB übrig.
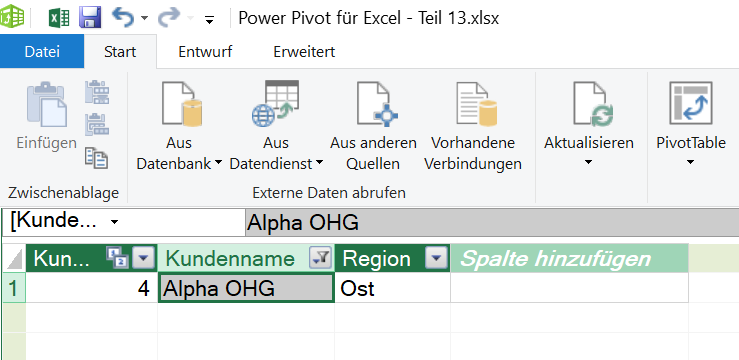
Über die Beziehung zwischen der Produkttabelle und der Tabelle mit den Bestellungen wird dieser Filter „weitergegeben“.
Die Tabelle mit Bestellungen enthält dadurch nur noch die Zeilen, bei denen die ProduktID = P-0015 ist.
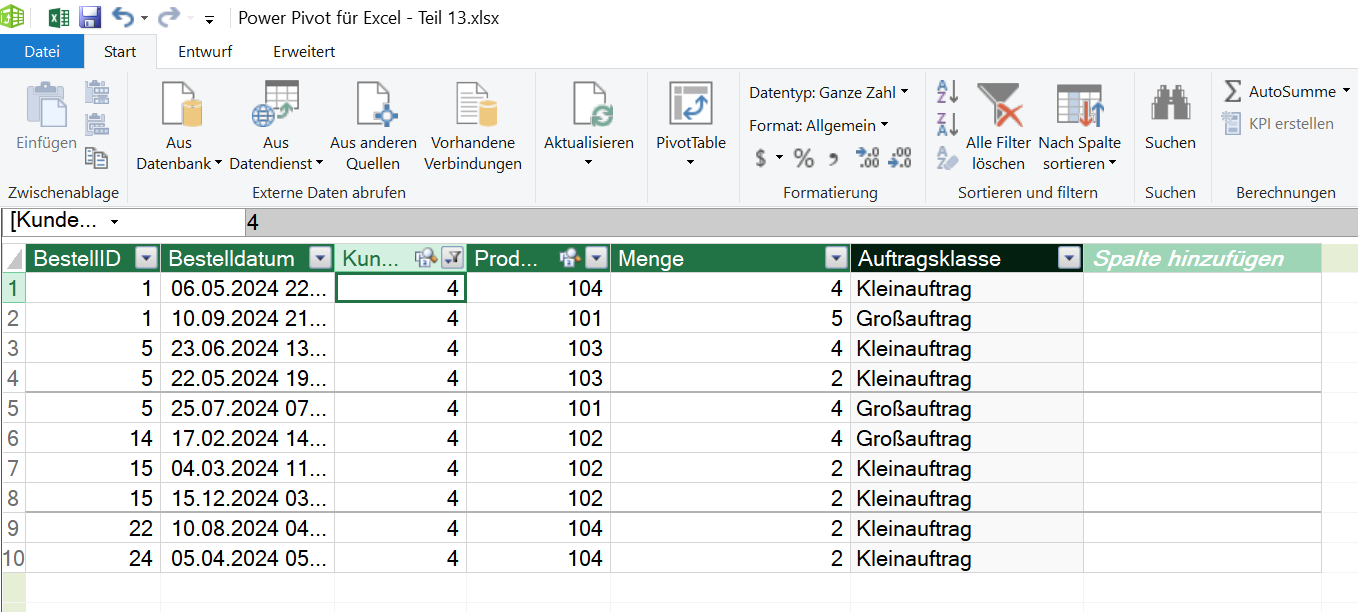
Erst danach kommen die Measures ins Spiel:
- Anzahl_Bestellungen:= DISTINCTCOUNT(t_Bestellungen[BestellID]) = 391
- Produkte_Menge_verkauft:= SUM(t_Bestellungen[Menge]) = 2.344
Das Ergebnis ist identisch, unabhängig davon, ob Sie mit der ProduktID aus t_Bestellungen oder mit dem Produktnamen aus t_Produkte arbeiten. Der Unterschied liegt in der Art, wie der Filter ins Modell einfließt.
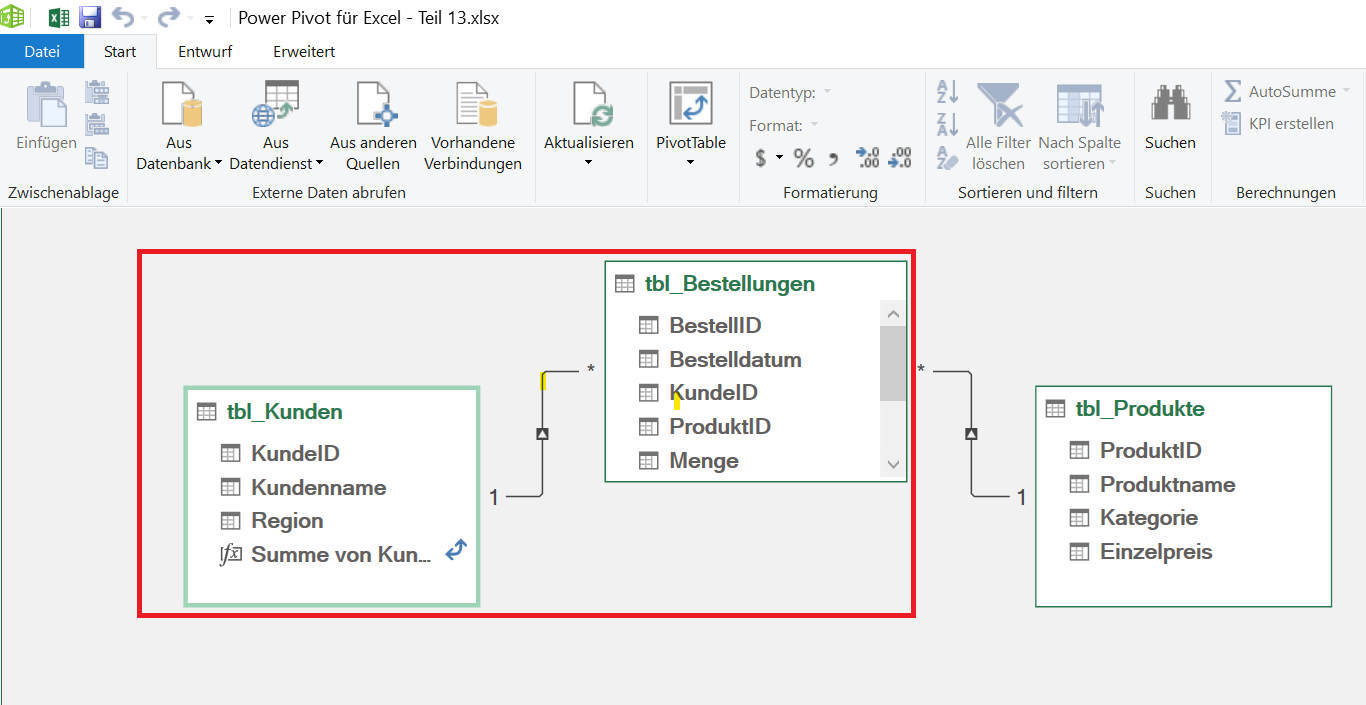
Filterfluss im Datenmodell
In der Diagrammansicht des Datenmodells können Sie den Mechanismus sehr gut nachvollziehen:
- Die Produkttabelle ist mit der Bestellungen-Tabelle über die Spalte ProduktID verbunden.
- Der Filter, der in der Produkttabelle gesetzt wird (zum Beispiel Bremsbeläge MTB), fließt entlang dieser Beziehung in die Bestellungen-Tabelle.
- Der Richtungspfeil in der Beziehung zeigt die Fließrichtung des Filters an.
Erst wenn alle Filter übertragen sind, führen die Measures ihre Berechnung durch.
Warum dieses Wissen so wichtig ist
Die Filterlogik ist das Fundament von Power Pivot und DAX. Wer diesen Mechanismus verstanden hat, kann:
- Ergebnisse besser nachvollziehen und Fehler vermeiden,
- komplexere Szenarien korrekt modellieren (zum Beispiel Filter über mehrere Dimensionstabellen) und
- die Unterschiede zwischen Filterkontext und Zeilenkontext begreifen – eines der wichtigsten Konzepte in DAX.
Ohne dieses Verständnis wirken viele DAX-Funktionen wie „Magie“. Mit diesem Wissen wird klar: Jede Berechnung ist nur das Ergebnis einer Filterung + Measure-Formel.
Fazit
Eine Pivot-Tabelle arbeitet immer nach demselben Muster:
- Filterung der Tabellen – basierend auf den ausgewählten Feldern in Zeilen, Spalten und Filtern.
- Weitergabe der Filter – über Beziehungen an andere Tabellen im Modell.
- Berechnung der Measures – auf Grundlage der gefilterten Daten.
Das gilt sowohl für den einfachen Fall mit einer einzigen Tabelle als auch für komplexe Datenmodelle mit vielen verknüpften Tabellen.
Demo-Daten für Power Pivot und DAX-Measures
In der folgenden Excel-Vorlage sind alle vorgestellten DAX-Measures eingerichtet. Sie finden dazu in der Vorlage:
- die Übersicht (Menü) mit Links zu den jeweiligen Musteranalysen und DAX-Measures sowie
- einer Verlinkung auf die Anleitungen zu den jeweiligen DAX-Measures,
- Musterdaten für Kunden, Produkte und Bestellungen,
- eine Kalendertabelle für die Zeitanalyse und die Time-Intelligence-Funktionen,
- alle definierten DAX-Measures in einer gesonderten Tabelle des Datenmodells: t_Measures
- eine Auswahl von Pivot-Tabellen als Grundlage für das Beispiel-Dashboard und
- ein Dashboard, in dem beispielhaft ausgewählte Pivot-Tabellen und die hinterlegten DAX-Measures als Chart oder KPI-Karte aufbereitet sind.
Nutzen Sie diese Vorlage, um sich mit den DAX-Measures und den Excel-Funktionen vertraut zu machen. Sie können diese Funktionsvorlagen nutzen und für Ihre Daten leicht anpassen.
Mit den Anleitungen und Beschreibungen auf business-wissen.de erarbeiten Sie Schritt für Schritt Ihr eigenes Datenmodell und die für Sie passenden DAX-Measures.
So machen Sie sich schnell mit den umfassenden Möglichkeiten von Power Pivot vertraut.