Power Pivot – Wichtige FunktionenVerteilungsanalysen und Statistik mit Power Pivot
Worum geht es bei Verteilungsanalysen?
Bei der Analyse von Kennzahlen zu Umsatz, Bestellungen oder Kosten erzählen Summen und Zeitverlauf oft nur einen Teil der Wahrheit. Vertiefende und weitaus hilfreichere Erkenntnisse ergeben sich aber erst aus genaueren Verteilungsanalysen.
Wenn Sie wissen wollen, wie sich Ihre Bestellungen tatsächlich verteilen, brauchen Sie Kennzahlen wie den Median, das 0,9-Quantil, den Mittelwert oder die Standardabweichung.
Mit diesen Kennzahlen können Sie Fragen beantworten wie:
- Wie groß ist der typische Bestellwert (Median)?
- Ab welcher Bestellsumme gehören Bestellungen zu den 10 % der höchsten Bestellsummen?
- Wie stark unterscheiden sich die kleinen von den großen Bestellungen?
- Wie konzentriert ist der Umsatz?
All das lässt sich mit DAX-Funktionen wie SUMX, AVERAGEX, STDEVX.P und PERCENTILEX.INC in Power Pivot elegant abbilden.
Ausgangssituation: Das Datenmodell
Im betrachteten Datenmodell gibt es zwei wichtige Tabellen:
- tbl_Bestellungen: Enthält alle Transaktionsdaten wie zum Beispiel BestellID, Bestelldatum, KundeID, ProduktID, Menge
- tbl_Produkte: Enthält Produktstammdaten wie zum Beispiel ProduktID, Einzelpreis
Zwischen tbl_Bestellungen[ProduktID] und tbl_Produkte[ProduktID] besteht eine 1:n-Beziehung. Damit können Sie Preise über die Funktion RELATED() in Berechnungen der Bestellungen einbeziehen.
Grundlage: Measure Umsatz je Bestellung
Für die genaue Datenanalyse betrachten Sie im Folgenden die Kennzahl „Umsatz je Bestellung“. Sie wollen sich also die Größe des Warenkorbs über alle Kundenbestellungen genauer ansehen und Muster erkennen.
Dazu berechnen Sie zunächst den entsprechenden Wert:
UmsatzjeBestellung :=SUMX(FILTER(tbl_Bestellungen; NOT(ISBLANK(tbl_Bestellungen[BestellID]))); tbl_Bestellungen[Menge] * RELATED(tbl_Produkte[Einzelpreis]))
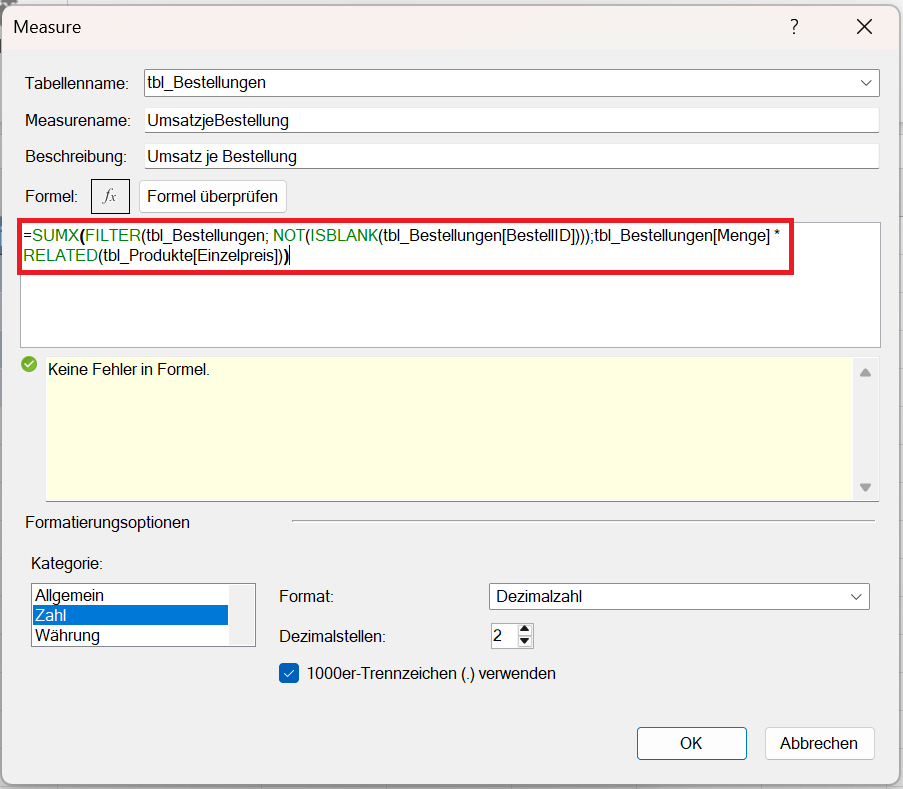
So funktioniert das Measure Schritt für Schritt:
- FILTER(tbl_Bestellungen; NOT(ISBLANK(…))): Blendet eventuelle leere oder fehlerhafte Zeilen aus, damit keine Nullwerte das Ergebnis verfälschen.
- RELATED(tbl_Produkte[Einzelpreis]): Holt aus der Produkttabelle den zur ProduktID passenden Einzelpreis über die Modell-Beziehung.
- SUMX( … ): Läuft zeilenweise über die Tabelle und multipliziert Menge und Einzelpreis und summiert alle Ergebnisse pro Bestellung.
Der Clou liegt im Filterkontext der daraus erstellten Pivot-Tabelle:
Wenn Sie in einer Pivot-Tabelle BestellID als Spaltenbeschriftung verwenden, berechnet das Measure den Umsatz nur für diese Bestellung. Steht im Spaltenbereich die KundenID, summiert es über alle Bestellungen des Kunden.
Das Measure liefert also den Umsatz je Bestellung, abhängig vom jeweiligen Kontext.
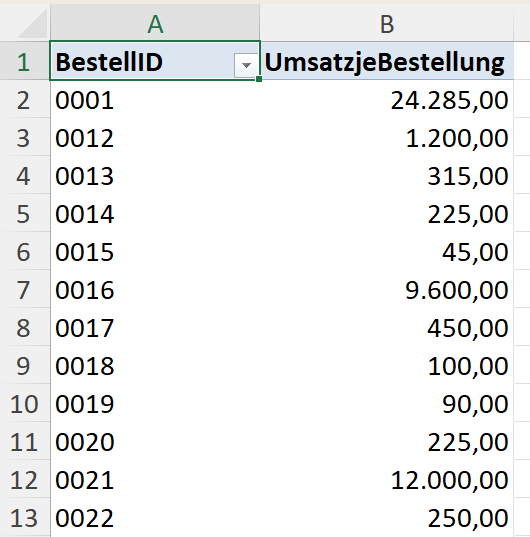
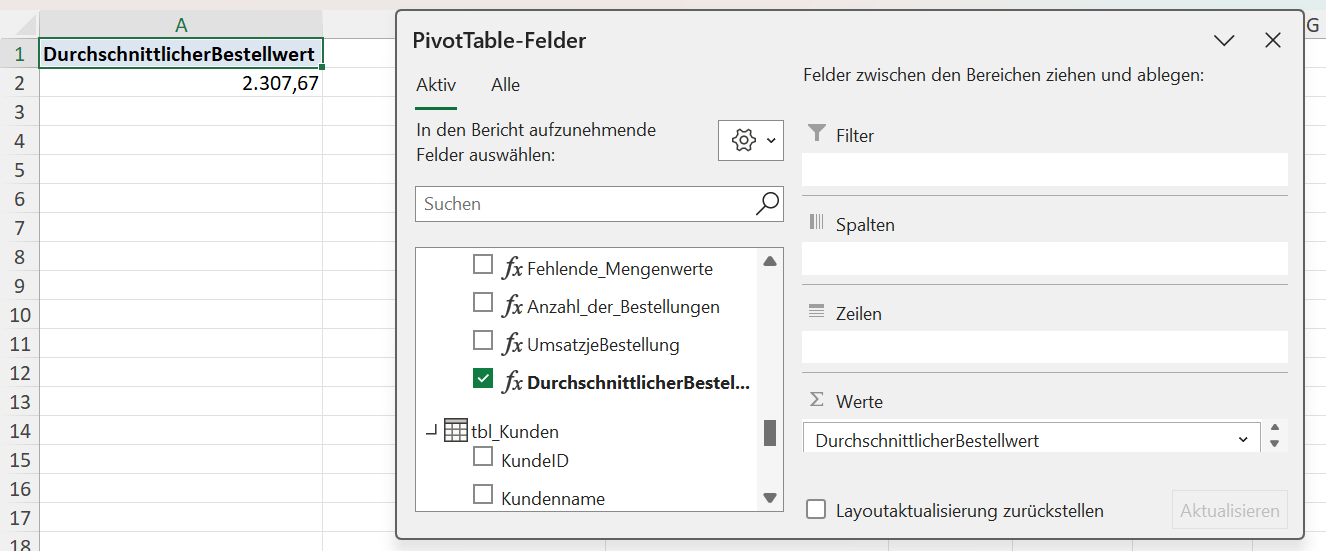
Durchschnittlicher Bestellwert (AVERAGEX)
Zunächst interessiert Sie der durchschnittliche Bestellwert über alle Bestellungen hinweg, also die durchschnittliche Größe des Warenkorbs für alle Bestellungen. Dazu berechnen Sie das Measure:
DurchschnittlicherBestellwert :=AVERAGEX(VALUES(tbl_Bestellungen[BestellID]); CALCULATE([UmsatzjeBestellung]))
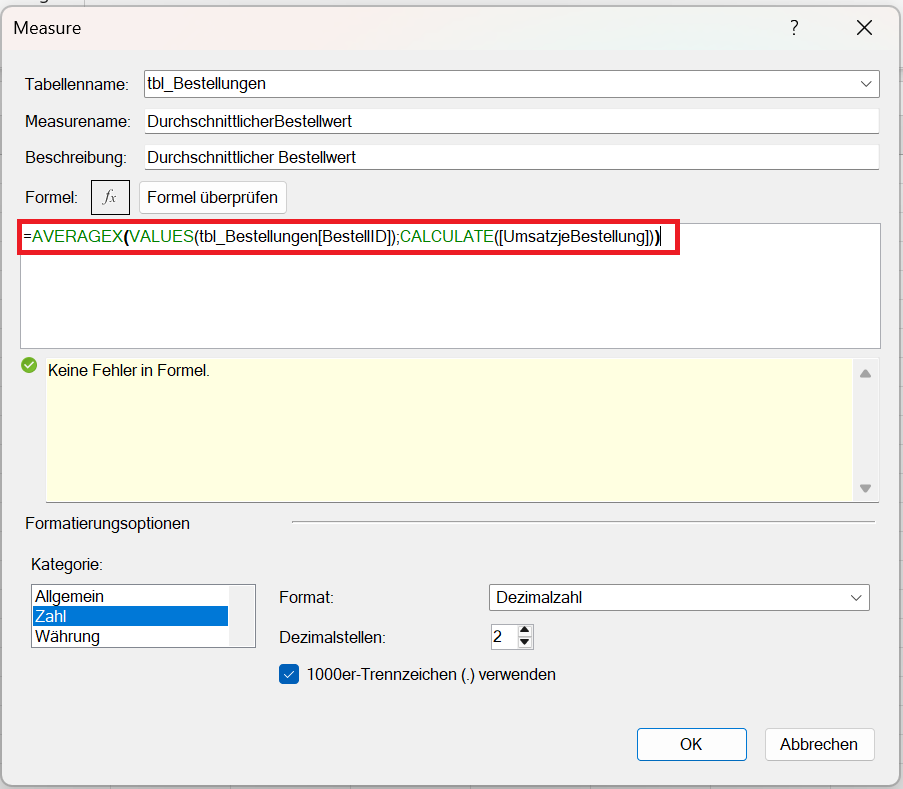
Erklärung des Measures:
- VALUES(tbl_Bestellungen[BestellID]): Erstellt eine Liste aller eindeutigen BestellID im aktuellen Kontext.
- CALCULATE([UmsatzjeBestellung]): Berechnet für jede dieser BestellIDs den jeweiligen Bestellumsatz (aus dem zuvor erstellten Measure).
- AVERAGEX( … ): Bildet daraus den Durchschnitt (arithmetisches Mittel) dieser Einzel-Bestellwerte.
Dieses Measure zeigt den durchschnittlichen Bestellwert – also, was eine typische Bestellung im Mittel einbringt. Damit erhalten Sie eine realistischere Kennzahl als bei einer simplen Durchschnittsbildung über Zeilen.
Das 90. Perzentil der Bestellwerte (PERCENTILEX.INC)
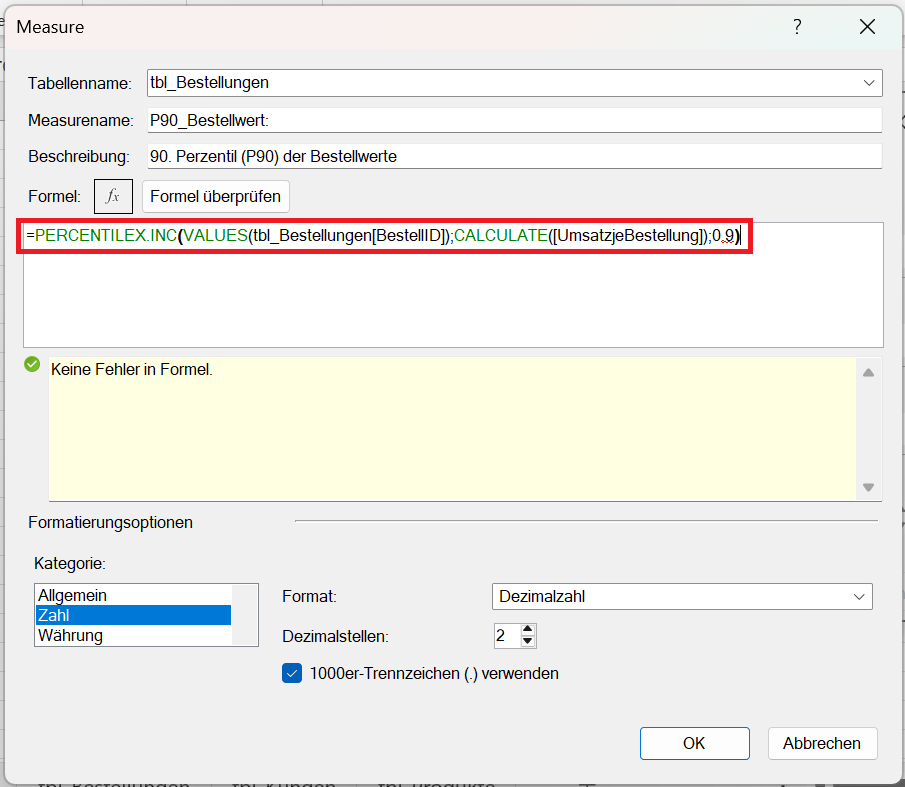
Im nächsten Schritt interessiert Sie, was den Warenkorbwert der Bestellungen auszeichnet, die zu den 10 % mit dem höchsten Bestellwert gehören. Dazu berechnen Sie das 90. Perzentil oder auch 0,9-Quantil mit der folgenden DAX-Formel:
P90_Bestellwert :=PERCENTILEX.INC(VALUES(tbl_Bestellungen[BestellID]); CALCULATE([UmsatzjeBestellung]); 0.9)
Erklärung der DAX-Formel:
PERCENTILEX.INC() sortiert alle Werte des angegebenen Ausdrucks (hier die Bestell- oder Warenkorbwerte) und liefert den Wert, unterhalb dessen 90 % der Bestellungen liegen.
Die drei Parameter bedeuten:
- VALUES(tbl_Bestellungen[BestellID]): Tabellenparameter → Liste aller Bestellungen.
- CALCULATE([UmsatzjeBestellung]): Ausdruck → Bestellwert pro Bestellung.
- Perzentilwert: 0.9 → 90 %.
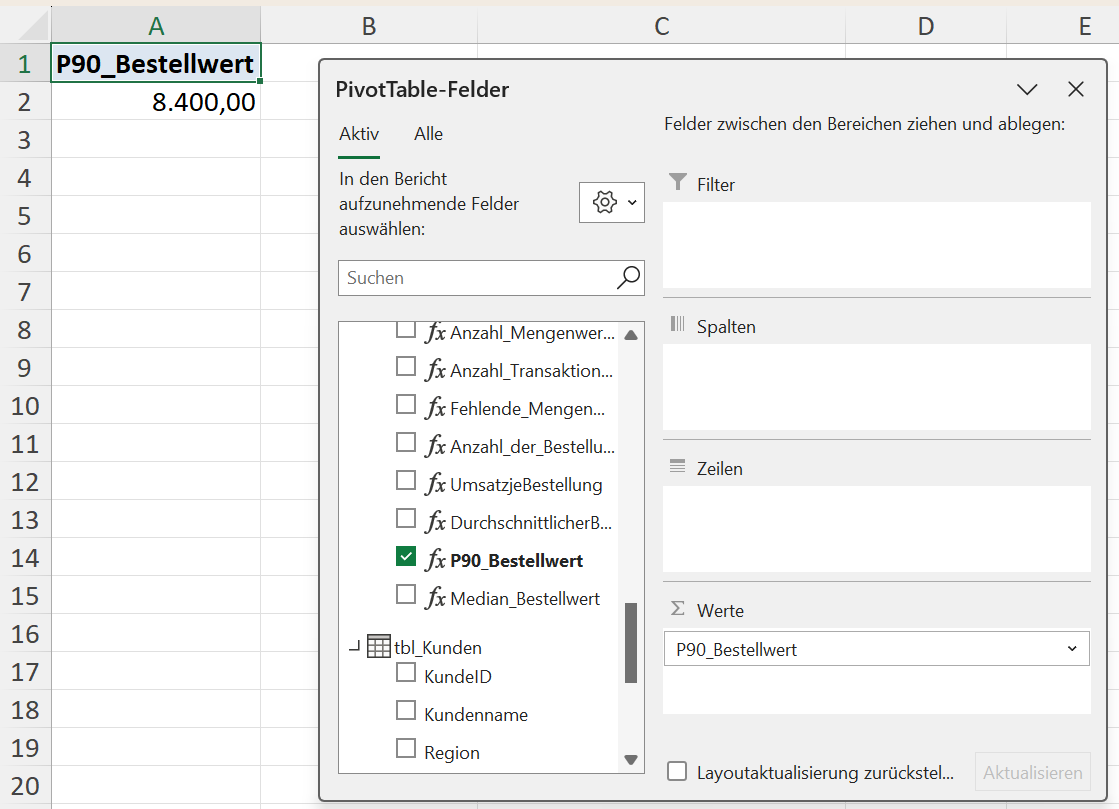
Im Beispiel liegt dieser Umsatz pro Bestellung bei 8.400,00 EUR. Das bedeutet: 90 % aller Bestellungen haben einen geringeren Bestellwert. 10 % der Bestellungen liegen mit ihrem Bestellwert darüber.
Ausführliche Erläuterungen zu Perzentilen und Quantilen finden Sie in diesem Beitrag: Methoden für deskriptive Statistik und Datenanalyse.
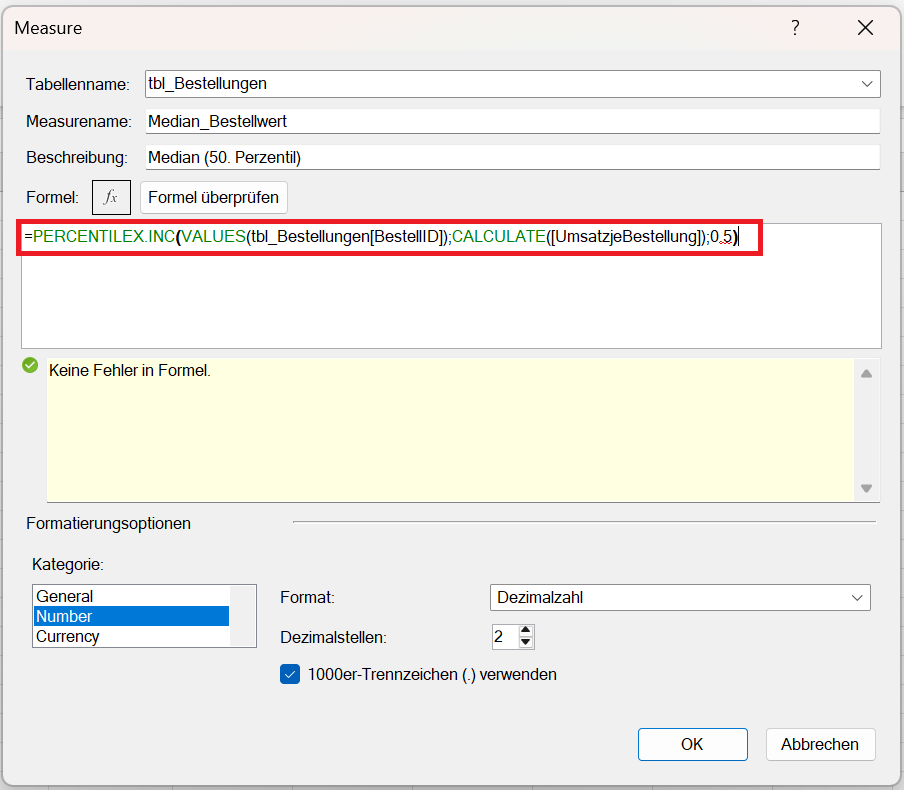
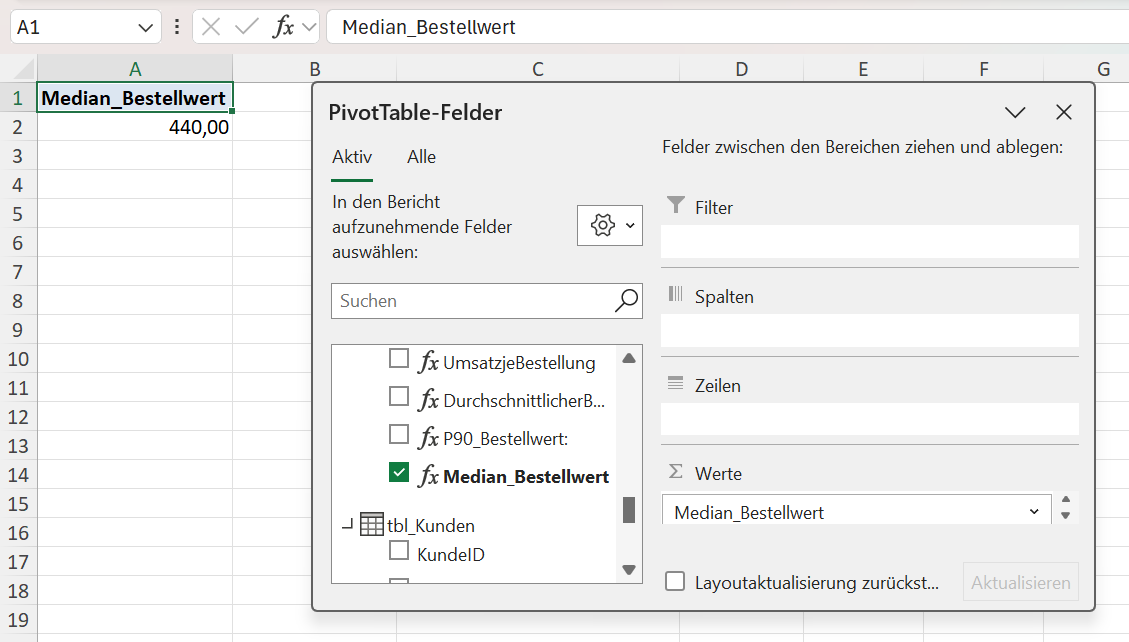
Median: 50. Perzentil oder 0,5-Quantil
Nicht immer ist der Durchschnitt oder Mittelwert eine hilfreiche Kennzahl. Das ist insbesondere dann der Fall, wenn es „Ausreißer“ gibt. Um deren Effekt einzugrenzen, wird der Median berechnet.
Die entsprechende DAX-Formel für das Datenmodell lautet:
Median_Bestellwert :=PERCENTILEX.INC(VALUES(tbl_Bestellungen[BestellID]); CALCULATE([UmsatzjeBestellung]); 0.5)
Der Median teilt Ihre Bestellungen in zwei Hälften:
- 50 % der Warenkorbwerte sind kleiner oder gleich dem Medianwert,
- 50 % sind größer.
Der Median ist robust gegen Ausreißer und beschreibt den „typischen“ Bestellwert besser als der Durchschnitt. Wenn der Median deutlich kleiner ist als der Mittelwert, wissen Sie sofort, dass einige wenige Großbestellungen das Gesamtbild stark verzerren.
Weitere interessante Perzentile: P25 und P75 oder Quartile
In der statistischen Datenanalyse werden zudem häufig die sogenannten Quartile betrachtet. Sie teilen – zusammen mit dem Median – eine Liste mit Werten (hier die Warenkorbwerte) in vier Gruppen.
Dazu werden mit den Quartilen die Werte bestimmt, unterhalb denen 25 % und 75 % der Werte liegen. Das ist das 25. Perzentil (0,25-Quantil) und das 75. Perzentil (0,75-Quantil).
Die DAX-Formeln dafür lauten:
P25_Bestellwert :=PERCENTILEX.INC(VALUES(tbl_Bestellungen[BestellID]); CALCULATE([UmsatzjeBestellung]); 0.25)
P75_Bestellwert :=PERCENTILEX.INC(VALUES(tbl_Bestellungen[BestellID]); CALCULATE([UmsatzjeBestellung]); 0.75)
Diese beiden Measures definieren die untere und obere Grenze des mittleren 50 %-Bereichs (Interquartilsabstand). Mit P25, P75, Median und P90 können Sie Streuungen sehr gut visualisieren – zum Beispiel in einer Boxplot-Darstellung oder einer Pivot mit Bedingter Formatierung.
Fazit
Mit diesen Measures haben Sie ein mächtiges Analysetool geschaffen:
- UmsatzjeBestellung: Gesamtumsatz je Bestellung = Basis für alle weiteren Berechnungen
- DurchschnittlicherBestellwert: Mittelwert oder Durchschnitt des Warenkorbwerts = Umsatz je Bestellung
- P25 / Median / P75 / P90: Lage- und Streuungsmaße der Bestellwerte
Diese Kennzahlen ermöglichen Ihnen eine tiefgehende Verteilungsanalyse, zeigen Umsatzschwerpunkte und machen sichtbar, welche Bestellungen den größten Beitrag zum Gesamtergebnis leisten.
Damit schaffen Sie die Grundlage für eine echte datenbasierte Entscheidungsunterstützung – direkt in Excel und ganz ohne zusätzliche Tools.
Weitere Möglichkeiten mit Power Pivot
In diesen Anleitungen erfahren Sie mehr zu den Grundlagen für Power Pivot:
- Einführung und Grundlagen zur Datenanalyse mit Power Pivot
- So aktivieren Sie Power Pivot
- So nutzen Sie Power Pivot für die Datenanalyse
- Power-Pivot-Modell vereinfachen mit RELATED und ausgeblendeten Feldern
- Datumsfunktionen in Power Pivot
- Benutzerdefinierte Spalten in Power Pivot mit der IF-Funktion
- Komplexe Bedingungen in Power Pivot mit IF, AND und OR
- In Power Pivot mit Measures (Kennzahlen) arbeiten
- Implizite Measures in Power Pivot
- Nachteile von impliziten Measures und Löschen dieser Measures
- Explizites Measure in Power Pivot: Zahlen mit SUM addieren
So erstellen Sie Kalendertabellen in Power Pivot, die Sie für Analysen im Zeitverlauf benötigen:
- Kalendertabellen in Power Pivot anlegen und nutzen
- Dynamische Kalendertabelle in Power Query erstellen und in Power Pivot nutzen
- Kalendertabelle ins Datenmodell integrieren und Hierarchie definieren
Und in diesen Anleitungen sind die wichtigen Time-Intelligence-Funktionen in Power Pivot erklärt:
- Time-Intelligence-Funktionen in DAX bei Power Pivot
- Vorjahresvergleich erstellen mit SAMEPERIODLASTYEAR
- Kumulierte Jahreswerte berechnen mit TOTALYTD
- Flexiblere Jahresberechnungen mit DATESYTD
- Zeiträume verschieben mit PARALLELPERIOD
- Kennzahlen für beliebige Zeiträume vergleichen mit DATEADD
- Gleitende Zeiträume betrachten mit DATESINPERIOD
- Schneller Datenvergleich mit PREVIOUSMONTH, NEXTMONTH …